马дёҠжіЁеҶҢе…ҘдјҡпјҢз»“дәӨ专家еҗҚжөҒпјҢдә«еҸ—иҙөе®ҫеҫ…йҒҮпјҢи®©дәӢдёҡз”ҹжҙ»еҸҢиөўгҖӮ
жӮЁйңҖиҰҒ зҷ»еҪ• жүҚеҸҜд»ҘдёӢиҪҪжҲ–жҹҘзңӢпјҢжІЎжңүеёҗеҸ·пјҹз«ӢеҚіжіЁеҶҢ


x
жҙӘж°ёж·ј жұӘеҜҝйҳіпјҲдёӯеӣҪ科еӯҰйҷўж•°еӯҰдёҺзі»з»ҹ科еӯҰз ”з©¶йҷўпјү дёҖгҖҒеј•иЁҖ
еңЁдёӯеӣҪпјҢз»Ҹеёёеҗ¬еҲ°йңҖиҰҒйҮҚи§Ҷз»ҸжөҺеӯҰжҖқжғіпјҢеә”иҜҘиҜҙиҝҷдёҖзӮ№еҰӮдҪ•ејәи°ғйғҪдёҚдёәиҝҮпјҢдҪҶз»ҸжөҺеӯҰз ”з©¶йҷӨдәҶжҖқжғіеӨ–пјҢиҝҳйңҖиҰҒж–№жі•жқҘжҸҗеҮәи§ЈеҶій—®йўҳзҡ„ж–№жЎҲпјҢжүҚиғҪеҪўжҲҗе®Ңж•ҙзҡ„зҗҶи®әдҪ“зі»гҖӮеӣ жӯӨпјҢеңЁз»ҸжөҺеӯҰз ”з©¶дёӯпјҢж–№жі•дёҺжҖқжғіеҗҢзӯүйҮҚиҰҒ(жҙӘж°ёж·јгҖҒжұӘеҜҝйҳіпјҢ2020)гҖӮз”ұдәҺеҺҶеҸІеҺҹеӣ пјҢдёӯеӣҪз»ҸжөҺеӯҰз ”з©¶жӣҫеңЁзӣёеҪ“й•ҝдёҖж®өж—¶жңҹеҶ…дёҖзӣҙд»Ҙе®ҡжҖ§еҲҶжһҗдёәдё»пјҢиҖҢзҺ°д»ЈиҘҝж–№з»ҸжөҺеӯҰд»Ҙе®ҡйҮҸеҲҶжһҗдёәдё»пјҢзү№еҲ«жҳҜиҝҮеҺ» 40 е№ҙжқҘеҪўжҲҗдәҶд»ҘеҹәдәҺж•°жҚ®зҡ„е®ҡйҮҸе®һиҜҒз ”з©¶дёәдё»зҡ„з ”з©¶иҢғејҸпјҢиҝҷе°ұжҳҜзҺ°д»Јз»ҸжөҺеӯҰжүҖи°“зҡ„вҖңе®һиҜҒйқ©е‘ҪвҖқ(empirical revolution)жҲ–вҖңеҸҜдҝЎжҖ§йқ©е‘ҪвҖқ(creditability revolution)гҖӮж”№йқ©ејҖж”ҫд»ҘжқҘпјҢдёӯеӣҪз»ҸжөҺеӯҰеңЁе®ҡйҮҸе®һиҜҒеҲҶжһҗдёҠеҸ–еҫ—дәҶй•ҝи¶ізҡ„иҝӣжӯҘпјҢиҝҷдёҖзӮ№еҸӘиҰҒзҝ»ејҖгҖҠз»ҸжөҺз ”з©¶гҖӢе’ҢгҖҠз®ЎзҗҶдё–з•ҢгҖӢзӯүеӣҪеҶ…з»ҸжөҺеӯҰгҖҒз®ЎзҗҶеӯҰзӯүйЎ¶е°–жңҹеҲҠжүҖеҸ‘иЎЁзҡ„еӯҰжңҜи®әж–ҮеҚіжңүж·ұеҲ»зҡ„ж„ҹеҸ—гҖӮдёӯеӣҪз»ҸжөҺеӯҰд»Ҙз ”з©¶дёӯеӣҪзү№иүІзӨҫдјҡдё»д№үеёӮеңәз»ҸжөҺиҝҗиЎҢдёҺеҸ‘еұ•и§„еҫӢдёәдё»иҰҒеҶ…е®№пјҢе…¶ж №жң¬д»»еҠЎжҳҜжһ„йҖ дёӯеӣҪз»ҸжөҺеӯҰеҺҹеҲӣжҖ§зҗҶи®әпјҢиҝҷдёҖзӮ№еңЁеӣҪеҶ…з»ҸжөҺеӯҰ家дёӯе·ІеҪўжҲҗжҷ®йҒҚе…ұиҜҶгҖӮдҪҶжҳҜпјҢдёӯеӣҪз»ҸжөҺеӯҰзҡ„з ”з©¶иҢғејҸеҲӣж–°гҖҒз ”з©¶ж–№жі•еҲӣж–°иҝҳжңүеҫ…ж”№иҝӣгҖӮд»ҺиҝҷдёӘж„Ҹд№үдёҠиҜҙпјҢеҜ№дәҺдёӯеӣҪз»ҸжөҺеӯҰз ”з©¶пјҢжңүж—¶ж–№жі•жҜ”жҖқжғіеҸҜиғҪиҝҳжӣҙйҮҚиҰҒпјҢеӣ дёәдёӯеӣҪз»ҸжөҺеӯҰ家иғҪеӨҹиҜҶеҲ«йҮҚиҰҒзҡ„з»ҸжөҺй—®йўҳпјҢдҪҶеңЁеҗ‘еӣҪйҷ…еӯҰжңҜеҗҢиЎҢи®Іиҝ°дёӯеӣҪз»ҸжөҺж•…дәӢж—¶жүҖйҮҮз”Ёзҡ„ж–№ејҸгҖҒж–№жі•еёёжңүж¬ зјәпјҢеҜјиҮҙдёӯеӣҪз»ҸжөҺеӯҰзҡ„еӣҪйҷ…еӯҰжңҜеҪұе“ҚеҠӣиҝҳжҜ”иҫғејұе°ҸгҖӮеҸҰдёҖж–№йқўпјҢжҲ‘们жӯЈеӨ„дәҺеӨ§ж•°жҚ®ж—¶д»ЈпјҢеӨ§ж•°жҚ®йқ©е‘ҪжӯЈеңЁж·ұеҲ»ең°еҪұе“ҚзҺ°д»Јз»ҸжөҺеӯҰзҡ„з ”з©¶иҢғејҸе’Ңз ”з©¶ж–№жі•пјҢжҺЁеҠЁе®ҡжҖ§еҲҶжһҗиҪ¬еҢ–дёәе®ҡйҮҸеҲҶжһҗпјҢзү№еҲ«жҳҜдёҚж–ӯеҲӣж–°д»Ҙж•°жҚ®дёәеҹәзЎҖзҡ„е®ҡйҮҸе®һиҜҒеҲҶжһҗж–№жі•гҖӮеӨ§ж•°жҚ®д№ҹжӯЈеңЁжӢ“еұ•з»ҸжөҺеӯҰз ”з©¶зҡ„иҢғз•ҙе’Ңиҫ№з•ҢпјҢжҺЁеҠЁз»ҸжөҺеӯҰдёҚд»…дёҺиҮӘ然科еӯҰдәӨеҸүиһҚеҗҲпјҢиҖҢдё”дёҺдәәж–ҮзӨҫдјҡ科еӯҰе…¶д»–еӯҰ科дә’зӣёжё—йҖҸпјҢиҝҷд№ҹеҝ…е°Ҷдҝғиҝӣз»ҸжөҺеӯҰдёҺдәәж–ҮзӨҫдјҡ科еӯҰзҡ„дёҚж–ӯиһҚеҗҲгҖӮ
жң¬ж–Үзҡ„дё»иҰҒзӣ®зҡ„жҳҜи®Ёи®әеңЁж•°еӯ—з»ҸжөҺж—¶д»ЈпјҢеӨ§ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ еҜ№з»ҸжөҺеӯҰзҡ„з ”з©¶иҢғејҸе’Ңз ”з©¶ж–№жі•зҡ„еҪұе“ҚпјҢзү№еҲ«жҳҜжүҖеёҰжқҘзҡ„жңәйҒҮе’ҢжҢ‘жҲҳгҖӮжҲ‘们е°ҶйҰ–е…Ҳд»Ӣз»Қз»ҸжөҺеӯҰз ”з©¶иҢғејҸзҡ„еҺҶеҸІжј”еҸҳпјҢзү№еҲ«жҳҜиҝҮеҺ» 40 е№ҙзҺ°д»Јз»ҸжөҺеӯҰвҖңе®һиҜҒйқ©е‘ҪвҖқзҡ„йҮҚиҰҒж„Ҹд№үпјҢ并йҖҡиҝҮ收е…ҘдёҚе№ізӯүз ”з©¶е’ҢеҸҚиҙ«еӣ°з ”究дёӨдёӘжЎҲдҫӢиҜҙжҳҺз ”з©¶иҢғејҸе’Ңз ”з©¶ж–№жі•еҜ№з»ҸжөҺзҗҶи®әеҲӣж–°зҡ„йҮҚиҰҒжҖ§пјҢ然еҗҺйҮҚзӮ№жҺўи®ЁеӨ§ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ еҜ№з»ҸжөҺеӯҰз ”з©¶иҢғејҸе’Ңз ”з©¶ж–№жі•зҡ„еҪұе“ҚпјҢжҲ‘们иҒҡз„Ұд»ҘдёӢеӣӣдёӘйўҶеҹҹ:дёҖжҳҜеӨ§ж•°жҚ®зү№еҲ«жҳҜж–Үжң¬ж•°жҚ®еҲӣж–°дәҶж–Үжң¬еӣһеҪ’(textual regression)зҡ„з ”з©¶иҢғејҸпјҢе°Ҷдәәж–ҮзӨҫдјҡеӣ зҙ пјҢеҰӮеҝғзҗҶжғ…ж„ҹгҖҒж”ҝжІ»жі•еҫӢгҖҒеҺҶеҸІж–ҮеҢ–гҖҒз”ҹжҖҒзҺҜеўғгҖҒеҚ«з”ҹеҒҘеә·зӯүдёҺз»ҸжөҺзҡ„дә’еҠЁе…ізі»зәіе…ҘдёҖдёӘз»ҹдёҖзҡ„е®ҡйҮҸе®һиҜҒеҲҶжһҗжЎҶжһ¶дёӯгҖӮжүҖи°“ж–Үжң¬еӣһеҪ’еҲҶжһҗпјҢжҳҜжҢҮеҹәдәҺеӨ§ж•°жҚ®зү№еҲ«жҳҜж–Үжң¬ж•°жҚ®жһ„е»әз»ҸжөҺдәәж–ҮеҸҳйҮҸпјҢ然еҗҺиҝҗз”Ёи®ЎйҮҸз»ҸжөҺеӯҰзҗҶи®әдёҺж–№жі•пјҢз ”з©¶з»ҸжөҺдёҺдәәж–Үеӣ зҙ д№Ӣй—ҙзҡ„йҖ»иҫ‘е…ізі»пјҢзү№еҲ«жҳҜеӣ жһңе…ізі»гҖӮдәҢжҳҜеӨ§ж•°жҚ®еёҰжқҘеҫҲеӨҡж–°еһӢж•°жҚ®пјҢеҰӮж–Үжң¬ж•°жҚ®гҖҒеӣҫеҪўж•°жҚ®гҖҒйҹійў‘ж•°жҚ®зӯүйқһз»“жһ„еҢ–ж•°жҚ®пјҢд»ҘеҸҠеҢәй—ҙж•°жҚ®(interval-valueddata)гҖҒз¬ҰеҸ·ж•°жҚ®(symbolic data)е’ҢеҮҪж•°ж•°жҚ®(functional data)зӯүпјҢиҝҷдәӣж–°еһӢж•°жҚ®е‘је”ӨеҲӣж–°и®ЎйҮҸз»ҸжөҺеӯҰжЁЎеһӢдёҺж–№жі•гҖӮдҫӢеҰӮпјҢеҢәй—ҙж•°жҚ®жҜ”зӮ№ж•°жҚ®(point-valued data)еҢ…еҗ«зҡ„дҝЎжҒҜеӨҡпјҢдҪҶй•ҝжңҹжІЎжңүеҫ—еҲ°жңүж•ҲеҲ©з”ЁгҖӮеҢәй—ҙи®ЎйҮҸз»ҸжөҺеӯҰжЁЎеһӢеҸҜз”ЁдәҺз»ҸжөҺйҮ‘иһҚеҸҳйҮҸеҢәй—ҙйў„жөӢе’Ңе®Ҹи§Ӯз»ҸжөҺеҢәй—ҙз®ЎзҗҶгҖӮдёүжҳҜжңәеҷЁеӯҰд№ дҪңдёәдәәе·ҘжҷәиғҪж–№жі•зҡ„дёҖдёӘдё»иҰҒж–№жі•пјҢеҸҜз”ЁдәҺзІҫеҮҶиҜҶеҲ«еӣ жһңе…ізі»е’Ңе®ҡйҮҸиҜ„дј°е…¬е…ұз»ҸжөҺж”ҝзӯ–пјҢд»ҘжӣҙеҘҪеҸ‘жҢҘж”ҝеәңдҪңз”ЁгҖӮеӣӣжҳҜжңәеҷЁеӯҰд№ зҡ„жӯЈеҲҷжҖ§(regularization)еҺҹзҗҶеҸҜз”ЁжқҘз®ҖеҢ–й«ҳз»ҙз”ҡиҮіи¶…й«ҳз»ҙи®ЎйҮҸз»ҸжөҺеӯҰжЁЎеһӢпјҢйҖҡиҝҮжңүж•ҲйҷҚз»ҙпјҢеё®еҠ©иҜҶеҲ«йҮҚиҰҒи§ЈйҮҠеҸҳйҮҸжҲ–йў„жөӢеҸҳйҮҸпјҢжҸҗеҚҮи®ЎйҮҸз»ҸжөҺеӯҰжЁЎеһӢзҡ„еҸҜи§ЈйҮҠжҖ§гҖҒз»ҹи®ЎжҺЁж–ӯж•ҲзҺҮе’Ңж ·жң¬еӨ–йў„жөӢиғҪеҠӣгҖӮ
дәҢгҖҒз»ҸжөҺеӯҰз ”з©¶иҢғејҸзҡ„еҺҶеҸІжј”еҸҳ
дҪңдёәдёҖй—ЁеҺҶеҸІз§‘еӯҰпјҢз»ҸжөҺеӯҰзҡ„з ”з©¶иҢғејҸйҡҸзқҖж—¶д»Јзҡ„еҸ‘еұ•иҖҢдёҚж–ӯеҸҳеҢ–гҖӮжҙӘж°ёж·јгҖҒжұӘеҜҝйҳіпјҲ2020пјүе·ІеҜ№з»ҸжөҺеӯҰз ”з©¶иҢғејҸзҡ„еҸ‘еұ•еҒҡдәҶз®ҖиҰҒжҺўи®ЁпјҢиҝҷйҮҢиҝӣдёҖжӯҘеұ•ејҖпјҢд»Ҙжӣҙе…Ёйқўең°еҸҚжҳ з ”з©¶иҢғејҸжј”еҸҳзҡ„е…ЁиІҢгҖӮ1776 е№ҙдәҡеҪ“В·ж–ҜеҜҶзҡ„гҖҠеӣҪеҜҢи®әгҖӢзҡ„еҸ‘иЎЁпјҢж Үеҝ—зқҖз»ҸжөҺеӯҰдҪңдёәдёҖй—ЁзӢ¬з«Ӣзҡ„еӯҰ科жӯЈејҸиҜһз”ҹгҖӮдәҡеҪ“В·ж–ҜеҜҶд»Ҙз»ҸжөҺеўһй•ҝдёәдё»йўҳпјҢиҝҗз”ЁеҺҶеҸІж–№жі•е’ҢйҖ»иҫ‘ж–№жі•пјҢи®әиҜҒиҮӘз”ұз«һдәүзҡ„иө„жң¬дё»д№үз»ҸжөҺеҲ¶еәҰиғҪеӨҹжҜ”е°Ғе»әз»ҸжөҺеҲ¶еәҰеҲӣйҖ еҮәжӣҙеӨ§зҡ„з”ҹдә§еҠӣгҖӮдәҡеҪ“В·ж–ҜеҜҶдҪҝз”ЁдәҶеҫҲеӨҡжЎҲдҫӢеҲҶжһҗпјҢиҝҷжҳҜе®һиҜҒз ”з©¶зҡ„дёҖдёӘжңҖеҹәжң¬ж–№жі•пјҲSmithпјҢ1776пјүгҖӮд№қеҚҒе№ҙеҗҺпјҢ马е…ӢжҖқпјҲMarxпјҢ1867пјүзҡ„гҖҠиө„жң¬и®әгҖӢ第дёҖеҚ·дәҺ 1867 е№ҙеҮәзүҲгҖӮ马е…ӢжҖқиҝҗз”ЁеҺҶеҸІе”Ҝзү©дё»д№үе’Ңиҫ©иҜҒе”Ҝзү©дё»д№үзҡ„еҲҶжһҗж–№жі•пјҢжҸӯзӨәдәҶиө„жң¬дё»д№үз»ҸжөҺеҲ¶еәҰдёӢиө„жң¬е’ҢеҠіеҠЁзҡ„зҹӣзӣҫдёҺеҜ№з«ӢпјҢд»ҘеҸҠиө„жң¬дё»д№үеҺҶеҸІеҸ‘еұ•зҡ„规еҫӢгҖӮдёҺгҖҠиө„жң¬и®әгҖӢ第дёҖеҚ·зҡ„еҮәзүҲзӣёе·®дёҚеҲ°еҚҒе№ҙпјҢ19 дё–зәӘ 70 е№ҙд»ЈиҘҝж–№з»ҸжөҺеӯҰеҮәзҺ°дәҶжүҖи°“зҡ„вҖңиҫ№йҷ…йқ©е‘ҪвҖқпјҲmarginal revolutionпјүпјҢд»ЈиЎЁдәәзү©еҢ…жӢ¬жқ°ж–Үж–ҜпјҲJevonsпјҢ1871пјүгҖҒз“Ұе°”жӢүж–ҜпјҲWalrasпјҢ1874пјүе’Ңй—Ёж је°”пјҲMengerпјҢ1871пјүзӯүгҖӮвҖңиҫ№йҷ…йқ©е‘ҪвҖқйҖҡиҝҮж•Ҳз”ЁеҮҪж•°е°ҶеҝғзҗҶеӣ зҙ еј•е…Ҙз»ҸжөҺеӯҰзҡ„еҲҶжһҗжЎҶжһ¶пјҢи§ЈйҮҠйңҖжұӮеҮҪж•°е’ҢдҫӣйңҖе…ізі»пјҢзү№еҲ«жҳҜзЁҖзјәиө„жәҗзҡ„жңүж•Ҳй…ҚзҪ®й—®йўҳпјҢиҖҢиҫ№йҷ…жҰӮеҝөзҡ„еј•иҝӣпјҢд№ҹдёәж•°еӯҰпјҲеҫ®з§ҜеҲҶпјүеңЁз»ҸжөҺеӯҰзҡ„е№ҝжіӣеә”з”Ёжү“ејҖдәҶдёҖжүҮеӨ§й—ЁпјҢжҺЁеҠЁдәҶзҺ°д»Јз»ҸжөҺеӯҰе®ҡйҮҸеҲҶжһҗж–№жі•зҡ„еҸ‘еұ•пјҢдёәж–°еҸӨе…ёз»ҸжөҺеӯҰзҡ„еҪўжҲҗеҘ е®ҡдәҶйҮҚиҰҒзҡ„ж–№жі•и®әеҹәзЎҖпјҢд№ҹдёәд»ҘеҗҺе®һйӘҢз»ҸжөҺеӯҰе’ҢиЎҢдёәз»ҸжөҺеӯҰз ”з©¶еҝғзҗҶеӣ зҙ еҜ№з»ҸжөҺдё»дҪ“иЎҢдёәзҡ„еҪұе“ҚеҘ е®ҡдәҶзҗҶи®әеҹәзЎҖгҖӮ
20 дё–зәӘ 30 е№ҙд»ЈеӨ§иҗ§жқЎеҗҺзҡ„вҖңеҮҜжҒ©ж–Ҝйқ©е‘ҪвҖқпјҲKeynesian revolutionпјүпјҢејҖиҫҹдәҶд»ҘзҺ°е®һй—®йўҳдёәеҜјеҗ‘зҡ„е®Ҹи§Ӯз»ҸжөҺеӯҰжҖ»йҮҸеҲҶжһҗзҡ„з ”з©¶иҢғејҸпјҢйҖҡиҝҮеҲҶжһҗе®Ҹи§Ӯз»ҸжөҺз»ҹи®ЎеҸҳйҮҸпјҲеҰӮ GDPгҖҒйҖҡиҙ§иҶЁиғҖзҺҮгҖҒеӨұдёҡзҺҮгҖҒеҲ©зҺҮпјүд№Ӣй—ҙзҡ„ж•°йҮҸе…ізі»пјҢеҜ»жүҫи§ЈйҮҠеӨұдёҡгҖҒжңүж•ҲйңҖжұӮдёҚи¶ізӯүзҺ°е®һз»ҸжөҺй—®йўҳд»ҘеҸҠи§ЈеҶіж–№жі•гҖӮеҮҜжҒ©ж–Ҝд№ҹеӣ жӯӨиў«з§°дёәвҖңе®Ҹи§Ӯз»ҸжөҺеӯҰд№ӢзҲ¶вҖқпјҢе…¶гҖҠе°ұдёҡгҖҒеҲ©жҒҜе’Ңиҙ§еёҒйҖҡи®әгҖӢеҮәзүҲзҡ„ж—¶й—ҙпјҲKeynesпјҢ1936пјүпјҢдёҺи®ЎйҮҸз»ҸжөҺеӯҰиҝҷдёҖеӯҰ科иҜһз”ҹзҡ„ж—¶й—ҙпјҲ1930 е№ҙпјүеҹәжң¬дёҖиҮҙгҖӮи®ЎйҮҸз»ҸжөҺеӯҰжҳҜз»ҸжөҺеӯҰе®һиҜҒз ”з©¶зҡ„жңҖдё»иҰҒж–№жі•и®әпјҢдёҺеҮҜжҒ©ж–Ҝд»Ҙй—®йўҳдёәеҜјеҗ‘зҡ„е®Ҹи§Ӯз»ҸжөҺжҖ»йҮҸеҲҶжһҗзҡ„з ”з©¶иҢғејҸзӣёиҫ…зӣёжҲҗгҖӮеҸҜд»ҘиҜҙпјҢеҮҜжҒ©ж–Ҝйқ©е‘ҪејҖиҫҹдәҶи®ЎйҮҸз»ҸжөҺеӯҰдҪңдёәз»ҸжөҺеӯҰе®һиҜҒз ”з©¶жңҖдё»иҰҒж–№жі•и®әзҡ„е№ҝйҳ”еҸ‘еұ•дёҺеә”з”Ёз©әй—ҙгҖӮдәӢе®һдёҠпјҢж—©жңҹзҡ„и®ЎйҮҸз»ҸжөҺеӯҰзҗҶи®әдёҺж–№жі•еӨ§еӨҡд»Ҙе®Ҹи§Ӯи®ЎйҮҸз»ҸжөҺеӯҰжЁЎеһӢдёәз ”з©¶еҜ№иұЎпјҢиҝҷдёҖдј з»ҹдёҖзӣҙ延з»ӯеҲ°д»ҠеӨ©е®Ҹи§Ӯз»ҸжөҺеӯҰдёӯеҹәдәҺеҠЁжҖҒйҡҸжңәдёҖиҲ¬еқҮиЎЎжЁЎеһӢзҡ„е®һиҜҒз ”з©¶пјҢиҝҷд»Һж ҮеҮҶзҡ„и®ЎйҮҸз»ҸжөҺеӯҰж•ҷ科д№ҰдёӯеҸҜжё…жҘҡзңӢеҲ°гҖӮеҪ“然пјҢз»ҸиҝҮиҝ‘зҷҫе№ҙзҡ„еҸ‘еұ•пјҢзҺ°д»Ји®ЎйҮҸз»ҸжөҺеӯҰзҺ°еңЁдёҚдҪҶжңүе®Ҹи§Ӯи®ЎйҮҸз»ҸжөҺеӯҰпјҢиҝҳеҢ…жӢ¬еҫ®и§Ӯи®ЎйҮҸз»ҸжөҺеӯҰзӯүеҫҲеӨҡеҲҶж”ҜпјҢиҖҢдё”еҸ‘еұ•йқһеёёиҝ…йҖҹгҖӮ
еҲ°дәҶ 20 дё–зәӘдә”е…ӯеҚҒе№ҙд»ЈпјҢж–°еҸӨе…ёз»јеҗҲпјҲnew classical synthesisпјүзҗҶи®әе°Ҷж–°еҸӨе…ёз»ҸжөҺеӯҰпјҲеҫ®и§Ӯз»ҸжөҺеӯҰпјүе’ҢеҮҜжҒ©ж–Ҝз»ҸжөҺеӯҰпјҲе®Ҹи§Ӯз»ҸжөҺеӯҰпјүжңүжңәиһҚеҗҲпјҢ并йҖҡиҝҮзҗҶжҖ§з»ҸжөҺдәәиҝҷдёҖж–°еҸӨе…ёз»ҸжөҺеӯҰзҡ„еҹәжң¬еҒҮи®ҫе’ҢдёҘи°Ёзҡ„ж•°еӯҰжҺЁеҜјпјҢе»әз«ӢдәҶдҪ“зі»еҢ–зҡ„зҺ°д»Јз»ҸжөҺеӯҰзҗҶи®әгҖӮиҝҷж–№йқўзҡ„дёҖдёӘе…ёеһӢжЎҲдҫӢжҳҜйҳҝзҪ—е’Ңеҫ·еёғйІҒпјҲArrow and DebreuпјҢ1954пјүпјҢ他们иҝҗз”Ёж•°еӯҰзҡ„дёҚеҠЁзӮ№е®ҡзҗҶпјҲfixed point theoremпјүпјҢиҜҒжҳҺдёҖиҲ¬еқҮиЎЎеёӮеңәеӯҳеңЁзҡ„еҸҜиғҪжҖ§пјҢд»ҺиҖҢеңЁе…«еҚҒе№ҙеҗҺе®ҢжҲҗз“Ұе°”жӢүж–ҜеңЁ 1874 е№ҙжңҖж—©жҸҗеҮәзҡ„дёҖиҲ¬еқҮиЎЎи®әзҡ„зҗҶи®әиҜҒжҳҺгҖӮж–°еҸӨе…ёз»јеҗҲзҗҶи®әеҗҺжқҘеҸ‘еұ•дёәзҗҶжҖ§йў„жңҹеӯҰжҙҫе’ҢеҠЁжҖҒйҡҸжңәдёҖиҲ¬еқҮиЎЎзҗҶи®әпјҢжҲҗдёәзҺ°д»Је®Ҹи§Ӯз»ҸжөҺеӯҰзҡ„зҗҶи®әеҹәзЎҖпјҢиҖҢеҺҹжқҘдҪңдёәеә”з”Ёж•°еӯҰдёҖдёӘеҲҶж”Ҝзҡ„еҚҡејҲи®әеҲҷжҲҗдёәеҫ®и§Ӯз»ҸжөҺеӯҰзҡ„зҗҶи®әеҹәзЎҖпјҢ并且дёҺдҝЎжҒҜдёҚеҜ№з§°гҖҒйқһе®Ңе…ЁзҗҶжҖ§зӯүеҒҸзҰ»з»ҸжөҺеӯҰзҗҶжғізҠ¶жҖҒзҡ„еҒҮи®ҫз»“еҗҲеңЁдёҖиө·пјҢжҺЁеҠЁдҝЎжҒҜз»ҸжөҺеӯҰгҖҒиЎҢдёәз»ҸжөҺеӯҰпјҲеҢ…жӢ¬иЎҢдёәйҮ‘иһҚеӯҰпјүе’Ңе®һйӘҢз»ҸжөҺеӯҰзӯүеӯҰ科зҡ„е…ҙиө·дёҺеҸ‘еұ•гҖӮ
20 дё–зәӘ 80 е№ҙд»Јд»ҘжқҘпјҢз”ұдәҺи®Ўз®—жңәжҠҖжңҜдёҺиҝҗз®—йҖҹеәҰзҡ„дёҚж–ӯиҝӣжӯҘпјҢд»ҘеҸҠз»ҸжөҺж•°жҚ®зҡ„еҸҜиҺ·еҫ—жҖ§пјҢз»ҸжөҺеӯҰз ”з©¶йҖҗжӯҘиҪ¬еҸҳдёәд»Ҙи®ЎйҮҸз»ҸжөҺеӯҰе’Ңе®һйӘҢз»ҸжөҺеӯҰдёәдё»иҰҒж–№жі•зҡ„е®һиҜҒеҲҶжһҗпјҢдёҚжҳҜйҖҡиҝҮж•°еӯҰжҺЁеҜјпјҢиҖҢжҳҜеҹәдәҺи§ӮжөӢж•°жҚ®е’Ңе®һйӘҢж•°жҚ®жҺЁж–ӯзҺ°е®һз»ҸжөҺдёӯз»ҸжөҺеҸҳйҮҸд№Ӣй—ҙзҡ„йҖ»иҫ‘е…ізі»пјҢзү№еҲ«жҳҜеӣ жһңе…ізі»пјҢ并йӘҢиҜҒз»ҸжөҺзҗҶи®әжҲ–з»ҸжөҺеҒҮиҜҙи§ЈйҮҠзҺ°е®һз»ҸжөҺзҺ°иұЎзҡ„иғҪеҠӣгҖӮиҝҷе°ұжҳҜзҺ°д»Јз»ҸжөҺеӯҰж–°зҡ„иҢғејҸйқ©е‘ҪпјҢеҚіжүҖи°“зҡ„вҖңе®һиҜҒйқ©е‘ҪвҖқпјҲempirical revolutionпјүгҖӮAngrist et al.пјҲ2017пјүеҸ‘зҺ°пјҢеңЁ 1980-2015 е№ҙпјҢеӣҪйҷ…йЎ¶е°–е’Ңдё»жөҒз»ҸжөҺеӯҰжңҹеҲҠд»Ҙж•°жҚ®дёәеҹәзЎҖзҡ„е®һиҜҒз ”з©¶и®әж–Үж•°йҮҸд»ҺдёҚеҲ° 35% дёҠеҚҮеҲ° 55% е·ҰеҸігҖӮз»ҸжөҺеӯҰд№ӢжүҖд»ҘдјҡеҮәзҺ°вҖңе®һиҜҒйқ©е‘ҪвҖқпјҢдё»иҰҒжҳҜеӣ дёәе®ғз¬ҰеҗҲ科еӯҰз ”з©¶иҢғејҸгҖӮжүҖ谓科еӯҰз ”з©¶иҢғејҸдё»иҰҒжҳҜжҢҮ科еӯҰе·ҘдҪңиҖ…жҸҗеҮәзҡ„д»»дҪ•зҗҶи®әжҲ–иҖ…еҒҮиҜҙйғҪйңҖиҰҒз”Ёз»ҸйӘҢпјҲж•°жҚ®пјүйӘҢиҜҒпјҲе…ідәҺз ”з©¶иҢғејҸзҡ„и®Ёи®әпјҢеҸӮи§Ғ KuhnпјҲ2012пјүпјүгҖӮиҝҷз§Қз ”з©¶иҢғејҸжңҖж—©жқҘиҮӘиҮӘ然科еӯҰзҡ„е®һйӘҢз ”з©¶пјҢз»ҸжөҺеӯҰ家е°Ҷд№Ӣеј•е…Ҙз»ҸжөҺеӯҰз ”з©¶пјҢ并еңЁж–№жі•и®әдёҠиҝӣиЎҢеҲӣж–°пјҢдҪҝд№Ӣжӣҙз¬ҰеҗҲз»ҸжөҺеӯҰз ”з©¶жүҖеҹәдәҺзҡ„еүҚжҸҗеҒҮи®ҫе’Ңж•°жҚ®зү№еҫҒгҖӮд»Ҙеӣ жһңе…ізі»з ”з©¶дёәдҫӢпјҢеҮ е№ҙеүҚдёӯеӣҪз»ҸжөҺеӯҰ家еҜ№дә§дёҡж”ҝзӯ–жҳҜеҗҰжңүж•Ҳдәүи®әеҫ—йқһеёёжҝҖзғҲгҖӮиҝҷз§ҚеӯҰжңҜдәүи®әжҳҜеҚҒеҲҶжңүзӣҠзҡ„пјҢеҗҢж—¶пјҢеҹәдәҺз»ҸжөҺи§ӮжөӢж•°жҚ®еҜ№дә§дёҡж”ҝзӯ–ж•Ҳеә”иҝӣиЎҢйҮҸеҢ–иҜ„дј°пјҢд№ҹеҸҜжҸҗдҫӣйҮҚиҰҒзҡ„иҜҒжҚ®дёҺжҙһи§ҒпјҢжңүеҠ©дәҺзІҫеҮҶж–Ҫзӯ–гҖӮдј—жүҖе‘ЁзҹҘпјҢйҷӨдәҶдә§дёҡж”ҝзӯ–еӨ–пјҢеҪұе“Қз»ҸжөҺзҡ„еӣ зҙ еҫҲеӨҡпјҢиҝҷдәӣеӣ зҙ жңүзҡ„еҸҜи§ӮжөӢпјҢжңүзҡ„дёҚеҸҜи§ӮжөӢгҖӮдә§дёҡж”ҝзӯ–иҜ„дј°е°ұжҳҜжҺ§еҲ¶е…¶д»–еӣ зҙ дёҚеҸҳпјҢиҒҡз„Ұдә§дёҡж”ҝзӯ–еҸҳеҢ–жҳҜеҗҰдјҡеҜјиҮҙз»ҸжөҺз»“жһңзҡ„еҸҳеҢ–гҖӮеҰӮжһңз»ҸжөҺз»“жһңеҸ‘з”ҹеҸҳеҢ–пјҢиҜҙжҳҺдә§дёҡж”ҝзӯ–дёҺз»ҸжөҺз»“жһңд№Ӣй—ҙеӯҳеңЁеӣ жһңе…ізі»пјӣеҸҚд№ӢпјҢдә§дёҡж”ҝзӯ–дёҺз»ҸжөҺз»“жһңд№Ӣй—ҙе°ұдёҚеӯҳеңЁеӣ жһңе…ізі»гҖӮиҷҪ然з»ҸжөҺзҗҶи®әд»ҺйҖ»иҫ‘дёҠеҸҜжҺЁеҮәеңЁдёҖе®ҡжқЎд»¶дёӢдә§дёҡж”ҝзӯ–жҳҜеҗҰдјҡеҪұе“Қз»ҸжөҺз»“жһңпјҢдҪҶиҝҷз§ҚзҗҶи®әжҺЁжөӢйғҪжҳҜе»әз«ӢеңЁдёҖзі»еҲ—еүҚжҸҗеҒҮи®ҫзҡ„еҹәзЎҖд№ӢдёҠпјҢеӣ жӯӨйңҖиҰҒз»ҸйӘҢйӘҢиҜҒпјҢжүҚиғҪзңҹжӯЈжҲҗдёәдёҖз§ҚеҸҜд»Ҙи§ЈйҮҠзҺ°е®һе’Ңйў„жөӢжңӘжқҘзҡ„з»ҸжөҺзҗҶи®әгҖӮз”ұдәҺзҺ°е®һз»ҸжөҺзҺҜеўғдёҺжқЎд»¶з»ҸеёёеҸ‘з”ҹеҸҳеҢ–пјҢд»»дҪ•з»ҸжөҺзҗҶи®әйғҪйңҖиҰҒз»ҸеёёжҺҘеҸ—з»ҸйӘҢжЈҖйӘҢпјҢжүҚиғҪз”ЁдәҺжҢҮеҜјз»ҸжөҺе®һи·өгҖӮеҰӮжһңдёҖдёӘзҗҶи®әдёҚиғҪи§ЈйҮҠж–°зҡ„з»ҸжөҺзҺ°иұЎпјҢйӮЈе°ұйңҖиҰҒиҝӣиЎҢзҗҶи®әеҲӣж–°гҖӮ
еӣ жһңеҲҶжһҗжңҖйҮҚиҰҒзҡ„еҒҮи®ҫеүҚжҸҗжҳҜдҝқжҢҒе…¶д»–еҸҳйҮҸдёҚеҸҳгҖӮж–°еҸӨе…ёз»ҸжөҺеӯҰд»ЈиЎЁдәәзү©й©¬жӯҮе°”зҡ„вҖңеұҖйғЁеқҮиЎЎвҖқеҲҶжһҗж–№жі•еғҸдёҖз§ҚеҹәдәҺжҖқжғіе®һйӘҢзҡ„еӣ жһңеҲҶжһҗж–№жі•пјҢдҪҶеӣ жһңе…ізі»жңҖз»ҲйңҖиҰҒйҖҡиҝҮз»ҸйӘҢпјҲж•°жҚ®пјүйӘҢиҜҒгҖӮеңЁиҮӘ然科еӯҰдёӯпјҢжҺ§еҲ¶е…¶д»–еӣ зҙ дёҚеҸҳзӣёеҜ№жҜ”иҫғз®ҖеҚ•пјҢеҸҜд»ҘйҖҡиҝҮеҸҜжҺ§е®һйӘҢе®һзҺ°пјҢдҪҶеҜ№дәҺз»ҸжөҺеӯҰд№ғиҮізӨҫдјҡ科еӯҰжқҘиҜҙпјҢе…¶ж•°жҚ®еӨҡдёәи§ӮжөӢж•°жҚ®пјҢ并йқһйҖҡиҝҮеҸҜжҺ§е®һйӘҢиҺ·еҫ—гҖӮз»ҸжөҺзі»з»ҹзҡ„иҝҷз§Қйқһе®һйӘҢжҖ§зү№зӮ№еҜ№еӣ жһңеҲҶжһҗеёҰжқҘе·ЁеӨ§жҢ‘жҲҳпјҢд№ҹжӯЈеӣ еҰӮжӯӨпјҢи®ЎйҮҸз»ҸжөҺеӯҰе’Ңе®һйӘҢз»ҸжөҺеӯҰеңЁиҝҮеҺ» 40 е№ҙеҸ‘еұ•дәҶеҫҲеӨҡеӣ жһңеҲҶжһҗж–№жі•пјҢеҰӮе®һйӘҢз»ҸжөҺеӯҰпјҲExperimental EconomicsпјүгҖҒйҡҸжңәжҺ§еҲ¶е®һйӘҢпјҲRandomized Controlled TrialsпјҢRCTпјүгҖҒиҮӘ然е®һйӘҢпјҲNatural ExperimentпјүгҖҒи§ӮжөӢж–№жі•пјҲObservational MethodпјүгҖҒз»“жһ„жЁЎеһӢпјҲStructural ModelsпјүзӯүгҖӮиҝҷдәӣе®һиҜҒж–№жі•жҳҜдёҚеҗҢеӯҰ科зү№еҲ«жҳҜж–ҮзҗҶеӯҰ科дәӨеҸүзҡ„з»“жһңпјҢе·Іе№ҝжіӣеә”з”ЁдәҺз»ҸжөҺеӯҰгҖҒз®ЎзҗҶеӯҰгҖҒеҝғзҗҶеӯҰгҖҒж”ҝжІ»еӯҰгҖҒзӨҫдјҡеӯҰгҖҒеҺҶеҸІеӯҰгҖҒеҢ»еӯҰгҖҒз”ҹзү©з»ҹи®ЎеӯҰзӯүеӯҰ科гҖӮ
еүҚйқўжҸҗеҲ°пјҢ马е…ӢжҖқзҡ„гҖҠиө„жң¬и®әгҖӢзҡ„дё»иҰҒеҲҶжһҗж–№жі•жҳҜеҺҶеҸІе”Ҝзү©дё»д№үе’Ңиҫ©иҜҒе”Ҝзү©дё»д№үпјҢгҖҠиө„жң¬и®әгҖӢд№ҹдҪҝз”ЁдёҖдәӣж•°еӯҰе·Ҙе…·е’ҢжЎҲдҫӢеҲҶжһҗж–№жі•пјҢдҪҶ马е…ӢжҖқеңЁгҖҠиө„жң¬и®әгҖӢдёӯ并没жңүдҪҝз”Ёд»Ҙж•°жҚ®дёәеҹәзЎҖзҡ„е®ҡйҮҸе®һиҜҒз ”з©¶ж–№жі•гҖӮж—Ҙжң¬й©¬е…ӢжҖқдё»д№үз»ҸжөҺеҸІеӯҰ家е®ҲеҒҘдәҢжӣҫдё“й—Ёз ”з©¶й©¬е…ӢжҖқе…ідәҺгҖҠиө„жң¬и®әгҖӢзҡ„еҶҷдҪңеҸІпјҢд»–еңЁ 2019 е№ҙзҡ„дёҖж®өйҮҮи®ҝдёӯжҸҗеҲ°пјҢ马е…ӢжҖқеңЁеҶҷгҖҠиө„жң¬и®әгҖӢж—¶еҒҡдәҶеӨ§йҮҸиҜ»д№Ұ笔记пјҢе…¶иҖғеҜҹиө„жң¬дё»д№үз»ҸжөҺеҚұжңәзҡ„笔记称дёәгҖҠеҚұжңә笔记гҖӢгҖӮе®ҲеҒҘдәҢиҜҙпјҡвҖңеңЁгҖҠеҚұжңә笔记гҖӢдёӯпјҢ马е…ӢжҖқиҮӘе·ұз»ҳеҲ¶дәҶеӨҡдёӘж—¶й—ҙйЎәеәҸиЎЁпјҢ并且е°ҶжҜҸеӨ©жҲ–жҜҸе‘Ёд»ҺжҠҘзәёе’ҢеҲҠзү©дёҠж‘ҳеҪ•зҡ„ж•°жҚ®еЎ«еҶҷеңЁдёҠйқўгҖӮиҷҪ然жңүдёҖйғЁеҲҶиЎЁж је№¶жІЎжңүеЎ«еҶҷе®Ңж•ҙпјҢиҝҳз•ҷжңүйғЁеҲҶз©әзҷҪпјҢдҪҶжҳҜд»–еҺҹжң¬жғіиҝӣиЎҢз»ҸйӘҢж•°жҚ®еҲҶжһҗзҡ„ж„ҸеӣҫжҳҜдёҚеҸҜеҗҰи®Өзҡ„гҖӮжӯӨеӨ–пјҢд»–иҝҳзј–еҲ¶дәҶе…ідәҺиӮЎзҘЁд»·ж јгҖҒе…¬е…ұеҖәеҲёд»·ж јгҖҒжұҮзҺҮе’Ңе•Ҷе“Ғд»·ж јзҡ„ж—¶й—ҙйЎәеәҸиЎЁгҖӮзү№еҲ«жҳҜеңЁй©¬е…ӢжҖқиҮӘиЎҢзј–еҲ¶зҡ„ 31д»ҪиЎЁж јдёӯпјҢжңү 11 д»ҪиЎЁж јжҳҫзӨәдәҶдё»иҰҒеҺҹж–ҷд»·ж јжҜҸе‘ЁжҲ–жҜҸе№ҙеҸҳеҠЁзҡ„ж•°жҚ®пјҢж¶өзӣ–дәҶгҖҠз»ҸжөҺеӯҰдәәгҖӢпјҲThe EconomistпјүжқӮеҝ—зҡ„е•Ҷе“Ғжё…еҚ•дёӯеҲ—еҮәзҡ„и¶…иҝҮ 400 йЎ№зҡ„е•Ҷе“ҒгҖӮеҫҲжҳҺжҳҫпјҢд»–жҳҜжғіиҰҒиҖғеҜҹиҝҷдәӣе•Ҷе“Ғзҡ„д»·ж јйҡҸзқҖеҚұжңәзҡ„зҲҶеҸ‘究з«ҹжҳҜеҰӮдҪ•дёӢйҷҚзҡ„гҖӮвҖқд»Һе®ҲеҒҘдәҢзҡ„и®ҝи°ҲдёӯеҸҜд»ҘзңӢеҮәпјҢ马е…ӢжҖқзҡ„гҖҠиө„жң¬и®әгҖӢиҷҪ然没жңүеҹәдәҺж•°жҚ®зҡ„е®ҡйҮҸе®һиҜҒз ”з©¶пјҢдҪҶд»–дәӢе®һдёҠеҒҡдәҶиҝҷж–№йқўзҡ„еҮҶеӨҮе·ҘдҪңпјҢеҸӘжҳҜйӮЈдёӘж—¶д»ЈжІЎжңүи®Ўз®—жңәпјҢиҝһж•°жҚ®йғҪйңҖиҰҒд»–жң¬дәәжүӢе·Ҙ收йӣҶзј–еҲ¶пјҢиҝӣиЎҢе®ҡйҮҸе®һиҜҒз ”з©¶зҡ„йҡҫеәҰеҸҜжғіиҖҢзҹҘгҖӮеӣ жӯӨпјҢжҲ‘们дёҚиғҪе°Ҷ马е…ӢжҖқж—¶д»Јд»Ҙе®ҡжҖ§еҲҶжһҗдёәдё»зҡ„з ”з©¶ж–№жі•дёҺзҺ°еңЁзҡ„д»Ҙе®ҡйҮҸеҲҶжһҗдёәдё»зҡ„з ”з©¶ж–№жі•еҜ№з«Ӣиө·жқҘгҖӮд»Ҙе“Әз§ҚеҲҶжһҗж–№жі•дёәдё»пјҢе…¶е®һдёҚд»…дёҺеӯҰ科еҸ‘еұ•зҡ„йҳ¶ж®өеҜҶеҲҮзӣёе…іпјҢд№ҹеҸ—еҲ°ж—¶д»ЈиғҢжҷҜзҡ„еҲ¶зәҰгҖӮдёӢж–ҮжҲ‘们е°ҶзңӢеҲ°пјҢеңЁеӨ§ж•°жҚ®ж—¶д»ЈпјҢе®ҡжҖ§еҲҶжһҗеҸҜд»ҘиҪ¬еҢ–дёәе®ҡйҮҸеҲҶжһҗпјҢдёӨиҖ…еҸҜд»ҘжңүжңәиһҚеҗҲгҖӮ
еңЁеӨ§ж•°жҚ®ж—¶д»ЈпјҢд»Ҙдә’иҒ”зҪ‘е’Ң移еҠЁдә’иҒ”зҪ‘дёәеҹәзЎҖзҡ„з»ҸжөҺжҙ»еҠЁпјҢеҢ…жӢ¬з”ҹдә§гҖҒдәӨжҚўгҖҒеҲҶй…ҚдёҺж¶Ҳиҙ№пјҢеӮ¬з”ҹдәҶдёҖдёӘж–°зҡ„з»ҸжөҺеҪўжҖҒпјҢеҚіж•°еӯ—з»ҸжөҺгҖӮеҮ д№ҺжүҖжңүз»ҸжөҺжҙ»еҠЁйғҪдјҡз•ҷдёӢз—•иҝ№пјҢиҝҷдәӣз—•иҝ№е°ұжҳҜе®һж—¶жҲ–еҮ д№Һе®һж—¶дә§з”ҹзҡ„еҗ„з§ҚеҪўејҸзҡ„еӨ§ж•°жҚ®гҖӮиҝҷдәӣеӨ§ж•°жҚ®еҸҚиҝҮжқҘдјҡй©ұеҠЁеҗ„з§Қз»ҸжөҺжҙ»еҠЁпјҢж•°жҚ®е·Із»ҸжҲҗдёәе…ій”®зҡ„з”ҹдә§иҰҒзҙ гҖӮгҖҠз»ҸжөҺеӯҰдәәгҖӢжқӮеҝ—жӣҫжҸҗеҮәдёҖдёӘж–°зҡ„ GDP жҰӮеҝөпјҢеҚіж•°жҚ®з”ҹдә§жҖ»еҖјпјҲGross DataProductпјүпјҢз”ЁжқҘжөӢеәҰж•°еӯ—з»ҸжөҺж—¶д»ЈдёҖдёӘеӣҪ家жҲ–ең°еҢәзҡ„ж•°жҚ®иҙўеҜҢеӨ§жҰӮжңүеӨҡе°‘пјҢжҲ–иҖ…иҜҙж•°жҚ®иө„жң¬жңүеӨҡеӨ§гҖӮеӨ§ж•°жҚ®е’Ңдәәе·ҘжҷәиғҪпјҲзү№еҲ«жҳҜжңәеҷЁеӯҰд№ пјүжҠҖжңҜжӯЈеңЁж”№еҸҳдәәзұ»зҡ„з”ҹдә§дёҺз”ҹжҙ»ж–№ејҸпјҢеҗҢж—¶д№ҹжӯЈеңЁж”№еҸҳз»ҸжөҺеӯҰзҡ„з ”з©¶еҜ№иұЎгҖҒз ”з©¶иҢғејҸдёҺз ”з©¶ж–№жі•гҖӮеӨ§ж•°жҚ®дёәз»ҸжөҺеӯҰз ”з©¶жҸҗдҫӣдәҶеӨ§йҮҸдё°еҜҢзҡ„ж•…дәӢе’Ңзҙ жқҗгҖӮз»ҸжөҺеӯҰз ”з©¶зҡ„дё»иҰҒзӣ®зҡ„жҳҜйҖҸиҝҮеҗ„з§ҚеӨҚжқӮзҡ„з»ҸжөҺзҺ°иұЎеҺ»жҸӯзӨәз»ҸжөҺиҝҗиЎҢе’ҢеҸ‘еұ•и§„еҫӢгҖӮеңЁж•°еӯ—з»ҸжөҺж—¶д»ЈпјҢеҮ д№ҺжүҖжңүзҡ„з»ҸжөҺзҺ°иұЎйғҪеҸҜз”ЁеӨ§ж•°жҚ®жқҘжҸҸиҝ°гҖӮиҝҷе°ұиҰҒжұӮеҜ№жө·йҮҸеӨ§ж•°жҚ®иҝӣиЎҢз”ұиЎЁеҸҠйҮҢзҡ„ж·ұе…Ҙзі»з»ҹзҡ„е®ҡйҮҸе®һиҜҒеҲҶжһҗпјҢд»ҺдёӯжҸӯзӨәз»ҸжөҺзі»з»ҹзҡ„жң¬иҙЁзү№еҫҒдёҺжң¬иҙЁиҒ”зі»пјҢзү№еҲ«жҳҜз»ҸжөҺеҸҳйҮҸд№Ӣй—ҙзҡ„еӣ жһңе…ізі»гҖӮеӣ жһңе…ізі»еңЁз»ҸжөҺеӯҰз ”з©¶дёӯеҚ жңүдёӯеҝғең°дҪҚпјҢеӣ дёәеӣ жһңе…ізі»жҳҜд»»дҪ•з»ҸжөҺзҗҶи®әе…·жңүеӨҡеӨ§и§ЈйҮҠеҠӣзҡ„еҶіе®ҡжҖ§еӣ зҙ гҖӮ
2016 е№ҙ 5 жңҲ 17 ж—ҘпјҢд№ иҝ‘е№іжҖ»д№Ұи®°еңЁе“ІеӯҰзӨҫдјҡ科еӯҰе·ҘдҪңеә§и°ҲдјҡдёҠжҢҮеҮәпјҡвҖңеҜ№зҺ°д»ЈзӨҫдјҡ科еӯҰз§ҜзҙҜзҡ„жңүзӣҠзҹҘиҜҶдҪ“зі»пјҢиҝҗз”Ёзҡ„жЁЎеһӢжҺЁжј”гҖҒж•°йҮҸеҲҶжһҗзӯүжңүж•ҲжүӢж®өпјҢжҲ‘们д№ҹеҸҜд»Ҙз”ЁпјҢиҖҢдё”еә”иҜҘеҘҪеҘҪз”ЁгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеңЁйҮҮз”ЁиҝҷдәӣзҹҘиҜҶе’Ңж–№жі•ж—¶дёҚиҰҒеҝҳдәҶиҖҒзҘ–е®—пјҢдёҚиҰҒеӨұеҺ»дәҶ科еӯҰеҲӨж–ӯеҠӣгҖӮ马е…ӢжҖқеҶҷзҡ„гҖҠиө„жң¬и®әгҖӢгҖҒеҲ—е®ҒеҶҷзҡ„гҖҠеёқеӣҪдё»д№үи®әгҖӢгҖҒжҜӣжіҪдёңеҗҢеҝ—еҶҷзҡ„зі»еҲ—еҶңжқ‘и°ғжҹҘжҠҘе‘Ҡзӯүи‘—дҪңпјҢйғҪиҝҗз”ЁдәҶеӨ§йҮҸз»ҹи®Ўж•°жҚ®е’Ңз”°йҮҺи°ғжҹҘжқҗж–ҷгҖӮвҖқд№ иҝ‘е№іжҖ»д№Ұи®°иҝҷйҮҢжҸҗеҲ°зҡ„жЁЎеһӢжҺЁжј”гҖҒж•°йҮҸеҲҶжһҗгҖҒз»ҹи®Ўж•°жҚ®е’Ңз”°йҮҺи°ғжҹҘзӯүж–№жі•дёҺжүӢж®өпјҢдёҺзҺ°д»Јз»ҸжөҺеӯҰзҡ„е®ҡйҮҸе®һиҜҒз ”з©¶ж–№жі•зү№еҲ«жҳҜеӣ жһңжҺЁж–ӯж–№жі•жҳҜдёҖиҮҙзҡ„гҖӮжҲ‘们еә”иҜҘеқҡжҢҒй—®йўҳеҜјеҗ‘пјҢеқҡжҢҒжҖқжғідёҺ方法并йҮҚпјҢеқҡжҢҒе®ҡжҖ§еҲҶжһҗдёҺе®ҡйҮҸеҲҶжһҗзӣёз»“еҗҲпјҢ并жү№еҲӨжҖ§ең°еҖҹйүҙеӣҪеӨ–дёҖеҲҮжңүзӣҠзҡ„зҗҶи®әжҲҗжһңе’ҢеҲҶжһҗж–№жі•пјҢжҸҗй«ҳдёӯеӣҪз»ҸжөҺеӯҰзҡ„з ”з©¶ж°ҙе№ідёҺз ”з©¶иҙЁйҮҸгҖӮ
дёүгҖҒз»ҸжөҺеӯҰз ”з©¶иҢғејҸе’Ңз ”з©¶ж–№жі•зҡ„йҮҚиҰҒжҖ§
еҜ№дәҺз»ҸжөҺеӯҰжқҘиҜҙпјҢд»»дҪ•з ”究зҡ„еӯҰжңҜд»·еҖјдё»иҰҒеҸ–еҶідәҺдёӨдёӘеӣ зҙ пјҢдёҖжҳҜз ”з©¶зҡ„科еӯҰй—®йўҳпјҢдёҖжҳҜи§ЈеҶій—®йўҳзҡ„ж–№жі•гҖӮ科еӯҰй—®йўҳзҡ„йҮҚиҰҒжҖ§еҸ–еҶідәҺжҖқжғізҡ„еҺҹеҲӣжҖ§е’Ңж–°йў–жҖ§пјҢиҖҢи§ЈеҶій—®йўҳзҡ„е…ій”®жҳҜж–№жі•пјҢиҝҷеҶіе®ҡеҸҜиғҪиҺ·еҫ—д»Җд№Ҳж ·зҡ„ж–°еҸ‘зҺ°дёҺж–°жҙһи§ҒгҖӮжҖқжғіе’Ңж–№жі•зӣёиҫ…зӣёжҲҗпјҢзјәдёҖдёҚеҸҜпјҲжҙӘж°ёж·јгҖҒжұӘеҜҝйҳіпјҢ2020пјүгҖӮеҫҲеӨҡжғ…еҪўиЎЁжҳҺпјҢдёӯеӣҪз»ҸжөҺеӯҰ家еңЁжһ„е»әдёӯеӣҪз»ҸжөҺеӯҰеҺҹеҲӣжҖ§зҗҶи®әж—¶пјҢиҝ«еҲҮйңҖиҰҒеҲӣж–°ж—ўз¬ҰеҗҲ科еӯҰз ”з©¶иҢғејҸеҸҲйҖӮеҗҲдёӯеӣҪжғ…жҷҜзҡ„еҲҶжһҗж–№жі•гҖӮеңЁдёӢж–Үи®Ёи®әдёӯпјҢжҲ‘们д»ҘдёӨдёӘз»ҸжөҺеӯҰз ”з©¶жЎҲдҫӢиҜҰз»ҶиҜҙжҳҺж–№жі•еңЁжһ„е»әеҺҹеҲӣжҖ§з»ҸжөҺзҗҶи®әдёӯзҡ„йҮҚиҰҒжҖ§гҖӮ
пјҲдёҖпјү收е…ҘдёҚе№ізӯүдёҺжүҳ马ж–Ҝ В· зҡ®еҮҜи’Ӯзҡ„гҖҠ21 дё–зәӘиө„жң¬и®әгҖӢ
дёӯеӣҪж”ҝеәңе°Ҷе…ұеҗҢеҜҢиЈ•и§ҶдёәзӨҫдјҡдё»д№үзҡ„дёҖдёӘжң¬иҙЁзү№еҫҒгҖӮ收е…ҘеҲҶй…ҚдёҖзӣҙжҳҜе…Ёзҗғз»ҸжөҺеӯҰ家й•ҝжңҹе…іжіЁзҡ„дёҖдёӘйҮҚиҰҒй—®йўҳгҖӮ马е…ӢжҖқеңЁгҖҠиө„жң¬и®әгҖӢдёӯд»Ҙеү©дҪҷеҠіеҠЁд»·еҖји®әдёәеҹәзЎҖпјҢиҝҗз”ЁеҺҶеҸІе”Ҝзү©дё»д№үе’Ңиҫ©иҜҒе”Ҝзү©дё»д№үж–№жі•пјҢжҸӯзӨәиө„жң¬дё»д№үз»ҸжөҺеҲ¶еәҰдёӢиө„жң¬дёҺеҠіеҠЁзҡ„еҜ№з«ӢдёҺзҹӣзӣҫпјҢзү№еҲ«жҳҜеҠіеҠЁж”¶е…ҘеҚ жҜ”ж—ҘзӣҠдёӢйҷҚзҡ„еҺҶеҸІи¶ӢеҠҝгҖӮдёӯеӣҪз»ҸжөҺеӯҰ家еҜ№й©¬е…ӢжҖқзҡ„гҖҠиө„жң¬и®әгҖӢйқһеёёзҶҹжӮүпјҢд№ҹжіЁж„ҸеҲ°ж”№йқ©ејҖж”ҫд»ҘжқҘдёӯеӣҪз»ҸжөҺеңЁеҝ«йҖҹеҸ‘еұ•зҡ„еҗҢж—¶пјҢдёҚеҗҢзӨҫдјҡзҫӨдҪ“е’ҢдёҚеҗҢең°еҢәзҡ„收е…ҘдёҚе№ізӯүд№ҹж—ҘзӣҠжү©еӨ§пјҢеӣ жӯӨ收е…ҘдёҚе№ізӯүдёҖзӣҙжҳҜдёӯеӣҪз»ҸжөҺеӯҰ家关注зҡ„дёҖдёӘйҮҚиҰҒй—®йўҳпјҢдёҖдәӣдёӯеӣҪз»ҸжөҺеӯҰ家еңЁиҝҷдёӘз ”з©¶йўҶеҹҹеҒҡеҮәдәҶйҮҚиҰҒзҡ„еӯҰжңҜиҙЎзҢ®пјҲжқҺе®һзӯүпјҢ2013пјүгҖӮ
иҝӣе…Ҙ 21 дё–зәӘд»ҘжқҘпјҢжі•еӣҪз»ҸжөҺеӯҰ家жүҳ马ж–ҜВ·зҡ®еҮҜи’ӮпјҲThomas PikettyпјүеҸҠе…¶еҗҲдҪңиҖ…з”Ёзҝ”е®һзҡ„еҺҶеҸІж•°жҚ®еҲ»з”»дәҶе…Ёдё–з•Ңдё»иҰҒеӣҪ家ж—ҘзӣҠжү©еӨ§зҡ„收е…ҘдёҺиҙўеҜҢдёҚе№ізӯүзҺ°иұЎпјҢиҝҷжҳҜ 10 е№ҙжқҘзҺ°д»Јз»ҸжөҺеӯҰжңҖжңүеҪұе“Қзҡ„е®ҡйҮҸе®һиҜҒз ”з©¶д№ӢдёҖгҖӮ2013 е№ҙпјҢзҡ®еҮҜи’ӮпјҲPikettyпјҢ2013пјүзҡ„гҖҠ21 дё–зәӘиө„жң¬и®әгҖӢжі•иҜӯзүҲеҮәзүҲпјҢиҜҘд№ҰйҖҡиҝҮдј°з®—иҝ‘ 300 е№ҙжқҘеӨҡдёӘеӣҪ家зҡ„иө„жң¬дёҺеҠіеҠЁж”¶е…ҘеҚ жҜ”пјҢеҸ‘зҺ°иҝӣе…Ҙ 21 дё–зәӘд»ҘжқҘпјҢ收е…ҘдёҺеҲҶй…ҚдёҚе№ізӯүе‘ҲзҺ°дёҺ 19 дё–зәӘ马е…ӢжҖқжүҖеӨ„зҡ„йӮЈдёӘж—¶д»Јзӣёдјјзҡ„дёӨжһҒеҲҶеҢ–жғ…еҪўгҖӮиҜҘз»“и®әйӘҢиҜҒдәҶ马е…ӢжҖқзҡ„гҖҠиө„жң¬и®әгҖӢжүҖжҸӯзӨәзҡ„иө„жң¬дё»д№үз»ҸжөҺдёӯиө„жң¬е’ҢеҠіеҠЁж—ҘзӣҠе°–й”җзҡ„еҜ№з«ӢдёҺзҹӣзӣҫпјҢд№ҹеҶІеҮ»дәҶиҘҝж–№дё»жөҒз»ҸжөҺеӯҰе…ідәҺзӨҫдјҡ收е…Ҙе’ҢиҙўеҜҢеҲҶй…Қе°ҶйҡҸзқҖз»ҸжөҺзҡ„е……еҲҶеҸ‘еұ•иҖҢйҖҗжӯҘи¶ӢдәҺе№ізӯүзҡ„и§ӮзӮ№пјҢзү№еҲ«жҳҜиҜәиҙқе°”з»ҸжөҺеӯҰеҘ–еҫ—дё»иҘҝи’ҷВ·еә“е…№ж¶…иҢЁпјҲSimonKuznetsпјүзҡ„вҖңеҖ’ U еһӢжӣІзәҝзҗҶи®әвҖқгҖӮд№ иҝ‘е№іжҖ»д№Ұи®°еңЁе“ІеӯҰзӨҫдјҡ科еӯҰе·ҘдҪңеә§и°ҲдјҡвҖң5В·17вҖқи®ІиҜқдёӯиҝҷж ·иҜ„д»·зҡ®еҮҜи’Ӯзҡ„гҖҠ21 дё–зәӘиө„жң¬и®әгҖӢпјҡвҖңиҜҘд№Ұз”Ёзҝ”е®һзҡ„ж•°жҚ®иҜҒжҳҺпјҢзҫҺеӣҪзӯүиҘҝж–№еӣҪ家зҡ„дёҚе№ізӯүзЁӢеәҰе·Із»ҸиҫҫеҲ°жҲ–и¶…иҝҮдәҶеҺҶеҸІжңҖй«ҳж°ҙе№іпјҢи®ӨдёәдёҚеҠ еҲ¶зәҰзҡ„иө„жң¬дё»д№үеҠ еү§дәҶиҙўеҜҢдёҚе№ізӯүзҺ°иұЎпјҢиҖҢдё”е°Ҷ继з»ӯжҒ¶еҢ–дёӢеҺ»гҖӮдҪңиҖ…зҡ„еҲҶжһҗдё»иҰҒжҳҜд»ҺеҲҶй…ҚйўҶеҹҹиҝӣиЎҢзҡ„пјҢжІЎжңүиҝҮеӨҡж¶үеҸҠжӣҙж №жң¬зҡ„жүҖжңүеҲ¶й—®йўҳпјҢдҪҶдҪҝз”Ёзҡ„ж–№жі•гҖҒеҫ—еҮәзҡ„з»“и®әеҖјеҫ—ж·ұжҖқгҖӮвҖқ
дёәдәҶз ”з©¶ж”¶е…ҘдёҚе№ізӯүзҺ°иұЎпјҢзҡ®еҮҜи’Ӯж•ҙеҗҲдәҶеҢ…жӢ¬еӣҪ民收е…ҘиҙҰжҲ·ж•°жҚ®гҖҒеҫ®и§Ӯи°ғжҹҘж•°жҚ®гҖҒзЁҺ收数жҚ®гҖҒе•Ҷдёҡ银иЎҢжҠҘе‘ҠеңЁеҶ…зҡ„еҗ„з§Қж•°жҚ®пјҢеҜ№ж”¶е…ҘдёҺиҙўеҜҢеҲҶй…ҚиҝӣиЎҢи·ЁеӣҪжҜ”иҫғеҲҶжһҗгҖӮж•ҙеҗҲж•°жҚ®зү№еҲ«жҳҜи·ЁеӣҪеҺҶеҸІж•°жҚ®жң¬иә«жҳҜдёҖйЎ№иү°иҫӣзҡ„е·ҘдҪңпјҢиҝҷжҳҜе®һиҜҒз ”з©¶зҡ„еҹәзЎҖгҖӮж•°жҚ®зҡ„иҙЁйҮҸзӣҙжҺҘеҪұе“Қз ”з©¶зҡ„иҙЁйҮҸз”ҡиҮіз»“и®әгҖӮзҡ®еҮҜи’ӮеҜ№дәҺе®һиҜҒж–№жі•и®әзҡ„дёҖдёӘиҙЎзҢ®жҳҜй’ҲеҜ№еҹәе°јзі»ж•°зҡ„зјәйҷ·пјҢдё»еј йҮҮз”ЁеҲҶй…ҚиЎЁеҲҶжһҗ收е…ҘдёҚе№ізӯүй—®йўҳгҖӮжүҖи°“еҹәе°јзі»ж•°пјҢжҳҜж„ҸеӨ§еҲ©з»ҹи®ЎеӯҰ家дёҺзӨҫдјҡеӯҰ家еҹәе°јпјҲGiniпјҢ1912пјүжҸҗеҮәз”Ёд»ҘжөӢеәҰдёҖдёӘз»ҸжөҺдҪ“жҲ–дёҖдёӘзӨҫдјҡзҡ„收е…ҘдёҚе№ізӯүзЁӢеәҰгҖӮеңЁеӣҫ 1 дёӯпјҢжЁӘиҪҙд»ЈиЎЁдәәеҸЈжҜ”дҫӢпјҲ%пјүпјҢзәөиҪҙ代表收е…ҘжҜ”дҫӢпјҲ%пјүпјҢеҲҷ 45% зӣҙзәҝ代表收е…Ҙз»қеҜ№е№іеқҮпјҢеӣ дёәеҜ№д»»ж„Ҹ x% дәәеҸЈпјҢ其收е…ҘеҚ жҜ”д№ҹжҳҜ x%пјҢеҸҰдёҖжқЎеҮёеҮҪж•°д»ЈиЎЁдёҖдёӘз»ҸжөҺдҪ“зҡ„е®һйҷ…收е…ҘеҲҶй…ҚзҠ¶еҶөпјҢжҳҫ然пјҢиҝҷжқЎжӣІзәҝиЎЁзӨәеӯҳеңЁдёҖе®ҡзЁӢеәҰзҡ„收е…ҘдёҚе№ізӯүзҺ°иұЎпјҢеӣ дёәд»»ж„Ҹx% зҡ„дәәеҸЈе…¶ж”¶е…ҘеҚ жҜ”е°ҸдәҺ x%пјҢдҪҶеҪ“ x% жҺҘиҝ‘ 1 ж—¶пјҢ收е…ҘеҚ жҜ”иҝ…йҖҹжҺҘиҝ‘ 1%пјҢиҝҷиЎЁзӨәй«ҳ收е…ҘдәәеҸЈзҡ„收е…ҘеҚ жҜ”иҫғй«ҳгҖӮдёәдәҶжөӢеәҰ收е…ҘдёҚе№ізӯүзЁӢеәҰпјҢеҸҜдҪҝз”Ёеҹәе°јзі»ж•° G=A/пјҲA+BпјүпјҢе…¶дёӯ A жҳҜ 45% зӣҙзәҝе’ҢеҮёеҮҪж•°жӣІзәҝд№Ӣй—ҙзҡ„йқўз§ҜпјҢB жҳҜеҮёеҮҪж•°жӣІзәҝд»ҘдёӢйқўз§ҜгҖӮжҳҫ然пјҢеҪ“收е…ҘдёәжӯЈж—¶пјҢеҹәе°јзі»ж•°еҸ–еҖјиҢғеӣҙжҳҜ 0 вүӨ G вүӨ 1гҖӮиӢҘG=0пјҢ代表收е…Ҙз»қеҜ№е№іеқҮеҲҶй…ҚпјҢиҖҢиӢҘ G=1пјҢеҲҷж„Ҹе‘ізқҖдёҖдёӘдәәжӢҘжңүж•ҙдёӘз»ҸжөҺдҪ“зҡ„收е…ҘгҖӮеҹәе°јзі»ж•°жңүдёҖдёӘдёҘйҮҚзјәйҷ·пјҢеҚідёӨз§ҚдёҚеҗҢзҡ„收е…ҘеҲҶеёғпјҢеҸҜд»ҘжңүзӣёеҗҢзҡ„еҹәе°јзі»ж•°гҖӮжҚўиЁҖд№ӢпјҢеҹәе°јзі»ж•°дёҚиғҪе”ҜдёҖеҲ»з”»ж”¶е…ҘдёҚе№ізӯүзҺ°иұЎгҖӮиҖҢ收е…ҘеҲҶй…ҚиЎЁжҳҜеҲҶдҪҚж•°пјҢйҖҡиҝҮз ”з©¶ж”¶е…ҘпјҲжҲ–иҙўеҜҢпјүжңҖйЎ¶з«Ҝ 1% зҡ„зҫӨдҪ“е’ҢжңҖеә•з«Ҝ 50% зҡ„зҫӨдҪ“зҡ„收е…ҘеңЁжҖ»ж”¶е…Ҙдёӯзҡ„жҜ”йҮҚпјҢеҸҜд»Ҙжӣҙзӣҙи§Ӯең°еҲ»з”»ж”¶е…ҘеҲҶй…ҚдёҚе№ізӯүзҡ„зЁӢеәҰгҖӮеӣҫ 2 жҳҫзӨәзҫҺеӣҪ收е…ҘеҲҶеёғзҡ„еҸҳеҢ–пјҢеҸҜд»ҘзңӢеҮәпјҢ1978-2014 е№ҙзҫҺеӣҪдәәеқҮ收е…Ҙж•ҙдҪ“е‘ҲзҺ°дёҠеҚҮи¶ӢеҠҝпјҢе…¶дёӯпјҢжңҖйЎ¶з«Ҝ 1% зҡ„зҫӨдҪ“зҡ„收е…ҘеҚ жҜ”жҢҒз»ӯдёҠеҚҮпјҢдҪҶжңҖеә•з«Ҝ 50% зҡ„зҫӨдҪ“зҡ„收е…ҘеҚҙдёҖи·Ҝиө°дҪҺпјҢиҜҘеӣҫзӣҙи§Ӯең°еҲ»з”»дәҶиҝҮеҺ» 40 е№ҙзҫҺеӣҪ收е…Ҙе·®и·қдёҚж–ӯжӢүеӨ§зҡ„и¶ӢеҠҝгҖӮиҝӣе…Ҙ 21дё–зәӘеҗҺпјҢдёӯеӣҪдәәеқҮ收е…Ҙеҝ«йҖҹеўһй•ҝпјҢдҪҶжҳҜ 1% зҡ„й«ҳ收е…ҘзҫӨдҪ“е’Ң 50% зҡ„дҪҺ收е…ҘзҫӨдҪ“д№ҹе‘ҲзҺ°зӣёеҸҚзҡ„иө°еҠҝпјҢиҷҪ然еңЁжңҖиҝ‘ 10 е№ҙпјҢ1% зҡ„й«ҳ收е…ҘзҫӨдҪ“зҡ„收е…ҘеҚ жҜ”з•ҘжңүйҷҚдҪҺпјҢиҖҢ 50% зҡ„дҪҺ收е…ҘзҫӨдҪ“зҡ„收е…ҘеҚ жҜ”дёҚеҶҚдёӢйҷҚпјҢдҝқжҢҒзЁіе®ҡж°ҙе№іпјҲи§Ғеӣҫ 3пјүгҖӮ



зҡ®еҮҜи’Ӯзҡ„ж•°жҚ®ж•ҙеҗҲзңӢдјјеҫҲз®ҖеҚ•пјҢдҪҶд»–дј°з®—иҝ‘ 300 е№ҙжқҘдё–з•Ңдё»иҰҒеӣҪ家зҡ„еҺҶеҸІж•°жҚ®пјҢеҢ…жӢ¬жі•еӣҪгҖҒзҫҺеӣҪгҖҒиӢұеӣҪд»ҘеҸҠдёӯеӣҪеңЁеҶ…пјҢ并计算еҮәиҝҷдәӣеӣҪ家зҡ„иө„жң¬дёҺеҠіеҠЁж”¶е…ҘеҚ жҜ”пјҢиҝҷжң¬иә«жҳҜдёҖдёӘе·ЁеӨ§зҡ„з ”з©¶е·ҘзЁӢгҖӮзҡ®еҮҜи’ӮиҠұдәҶ 20 е№ҙпјҢдёҺеҗҲдҪңиҖ…е…ұеҗҢеҲӣе»әдәҶдё–з•ҢдёҚе№ізӯүж•°жҚ®еә“пјҲWorld Inequality DatabaseпјҢWIDпјүпјҢиҝҷдёӘж•°жҚ®еә“жӯЈеңЁжҺЁеҠЁдёҚе№ізӯүз»ҸжөҺеӯҰйўҶеҹҹзҡ„еҸ‘еұ•гҖӮ2020 е№ҙпјҢзҡ®еҮҜи’ӮеңЁиӢұеӣҪи®°иҖ… Simon Kuperи®ҝи°ҲдёӯжҸҗеҲ°пјҡвҖңжҲ‘жҖқиҖғзҡ„дё»иҰҒзӢ¬еҲ°д№ӢеӨ„жҳҜпјҢжҲ‘зҡ„еҲҶжһҗеҸҜд»ҘеҹәдәҺеҺҶеҸІзӣҙеҲ°д»ҠеӨ©зҡ„ж—¶й—ҙеәҸеҲ—ж•°жҚ®гҖӮвҖқ
пјҲдәҢпјүдёӯеӣҪеҮҸиҙ«жҲҗе°ұдёҺ 2019 е№ҙиҜәиҙқе°”з»ҸжөҺеӯҰеҘ–
иҙ«еӣ°й—®йўҳдёҖзӣҙжҳҜеҸ‘еұ•з»ҸжөҺеӯҰй•ҝжңҹе…іжіЁе’Ңз ”з©¶зҡ„йҮҚиҰҒй—®йўҳгҖӮ2019 е№ҙиҜәиҙқе°”з»ҸжөҺеӯҰеҘ–жҺҲдәҲйҳҝжҜ”еҗүзү№В·е·ҙзәіеҗүпјҲAbhijit BanerjeeпјүгҖҒеҹғдёқзү№В·иҝӘеј—жҙӣпјҲEstherDufloпјүе’ҢиҝҲе…Ӣе°”В·е…Ӣйӣ·й»ҳпјҲMichael KremerпјүдёүдҪҚз»ҸжөҺеӯҰ家пјҢд»ҘиЎЁеҪ°д»–们еҲӣж–°вҖңеҮҸиҪ»е…Ёзҗғиҙ«еӣ°ж–№йқўзҡ„е®һйӘҢж–№жі•вҖқгҖӮ他们зҡ„дё»иҰҒиҙЎзҢ®жҳҜжҸҗеҮәж–°зҡ„йҡҸжңәиҜ•йӘҢж–№жі•вҖ”вҖ”йҡҸжңәжҺ§еҲ¶е®һйӘҢпјҲRandom Control ExperimentпјүпјҢд»ҘжҺўзҙўе…ідәҺж¶ҲйҷӨе…Ёзҗғиҙ«еӣ°зҡ„жңҖдҪіж–№ејҸгҖӮдёӯеӣҪз»ҸжөҺеӯҰ家еӨ§еӨҡж“…й•ҝе®ҸеӨ§еҸҷдәӢпјҢжүҖз ”з©¶зҡ„й—®йўҳжҜ”иҫғе®Ҹи§ӮпјҢдҪҶиҝҷдёүдҪҚз»ҸжөҺеӯҰ家е°Ҷиҙ«еӣ°з ”究иҝҷдёӘеӨ§й—®йўҳз»ҶеҲҶжҲҗжӣҙе°ҸгҖҒжӣҙе®№жҳ“еҲҶжһҗзҡ„еӯҗй—®йўҳпјҢдҫӢеҰӮпјҢд»–д»¬з ”з©¶дәҶж”№иҝӣж•ҷиӮІжҲҗж•ҲжҲ–е„ҝз«ҘеҒҘеә·зҡ„жңҖжңүж•Ҳе№Ійў„жҺӘж–ҪгҖӮиҝҷдәӣжӣҙе°ҸжӣҙзІҫзЎ®зҡ„й—®йўҳпјҢеҫҖеҫҖеҸҜд»ҘйҖҡиҝҮзІҫеҝғи®ҫи®Ўзҡ„е®һйӘҢпјҢеңЁжңҖеҸ—еҪұе“Қзҡ„дәәзҫӨдёӯиҺ·еҫ—жңҖеҘҪзҡ„еӣһзӯ”гҖӮиҝҷжҳҜдёҖз§Қз ”з©¶ж–№жі•зҡ„еҲӣж–°пјҢзү№еҲ«еңЁж¶ҲйҷӨиҙ«еӣ°зҡ„еӣ жһңжҺЁж–ӯж–№йқўгҖӮ他们иҝҳеҲӣе»әйҳҝеҚңжқңеӢ’В·жӢүи’ӮеӨ«В·иҙҫзұіе°”иҙ«еӣ°иЎҢеҠЁе®һйӘҢе®ӨпјҲAbdul Latif Jameel PovertyAction LabпјҢJ-PALпјүпјҢе…¶дё»иҰҒд»»еҠЎжҳҜдёҺеҸ‘еұ•дёӯеӣҪ家зҡ„ж”ҝеәңеҗҲдҪңпјҢжҸҗдҫӣе…ідәҺеҸҚиҙ«зҡ„е’ЁиҜўе»әи®®пјҢзЎ®дҝқжү¶иҙ«ж”ҝзӯ–зҡ„еҲ¶е®ҡеҹәдәҺ科еӯҰдҫқжҚ®пјҢд»ҺиҖҢжңүж•ҲеҮҸе°‘иҙ«еӣ°дәәеҸЈгҖӮJ-PAL е®һйӘҢе®Өзҡ„з ”з©¶жҲҗжһңе·Іиөўеҫ—еӣҪйҷ…и®ӨеҸҜгҖӮ
жҜ«ж— з–‘д№үпјҢдёүдҪҚз»ҸжөҺеӯҰ家еҜ№иҙ«еӣ°з»ҸжөҺеӯҰе’Ңдё–з•ҢеҸҚиҙ«дәӢдёҡеҒҡеҮәдәҶйҮҚиҰҒиҙЎзҢ®гҖӮдҪҶжҳҜпјҢзӣёжҜ”иҖҢиЁҖпјҢиҝҮеҺ» 40 еӨҡе№ҙжқҘпјҢдёӯеӣҪз»ҸжөҺй«ҳйҖҹеўһй•ҝпјҢе…ұжңү 8 дәҝеӨҡдәәе®һзҺ°и„ұиҙ«пјҢеҜ№дё–з•ҢеҮҸиҙ«иҙЎзҢ®зҺҮи¶…иҝҮ 70%гҖӮ2020 е№ҙ 11 жңҲ 23 ж—ҘпјҢиҙөе·һзңҒе®ЈеёғжңҖеҗҺ 9 дёӘеҺҝйҖҖеҮәеӣҪ家зә§иҙ«еӣ°еҺҝеәҸеҲ—пјҢиҮіжӯӨе…ЁеӣҪ 832 дёӘиҙ«еӣ°еҺҝе…ЁйғЁи„ұиҙ«ж‘ҳеёҪпјҢдёӯеӣҪжҸҗеүҚ10 е№ҙе®һзҺ°иҒ”еҗҲеӣҪ 2030 е№ҙеҸҜжҢҒз»ӯеҸ‘еұ•и®®зЁӢж¶ҲйҷӨз»қеҜ№иҙ«еӣ°зӣ®ж ҮпјҢеҸҚиҙ«жҲҗе°ұеҫ—еҲ°иҒ”еҗҲеӣҪгҖҒдё–з•Ң银иЎҢзӯүеӣҪйҷ…з»„з»Үзҡ„жҷ®йҒҚи®ӨеҸҜгҖӮ然иҖҢпјҢдёӯеӣҪз»ҸжөҺеӯҰ家没иғҪеғҸ 2019 е№ҙзҡ„дёүдҪҚиҜәиҙқе°”з»ҸжөҺеӯҰеҘ–еҫ—дё»йӮЈж ·пјҢеҗ‘еӣҪйҷ…еҗҢиЎҢи®ІеҘҪвҖңдёӯеӣҪеҮҸиҙ«ж•…дәӢвҖқпјҢдё»иҰҒжҳҜеӣ дёәжҲ‘们зјәд№ҸеӣҪйҷ…еҗҢиЎҢи®ӨеҸҜзҡ„з ”з©¶иҢғејҸпјҢзү№еҲ«жҳҜйҖӮеҗҲдёӯеӣҪжғ…жҷҜзҡ„е®ҡйҮҸе®һиҜҒз ”з©¶ж–№жі•зҡ„еҲӣж–°дёҺеә”з”ЁпјҢеҜјиҮҙжІЎжңүдә§з”ҹе…·жңүеӣҪйҷ…еӯҰжңҜеҪұе“ҚеҠӣзҡ„еҸҚиҙ«еӣ°еӯҰжңҜзҗҶи®әжҲҗжһңгҖӮеә”иҜҘжҢҮеҮәпјҢдёүдҪҚеҸҚиҙ«еӣ°з»ҸжөҺеӯҰ家жҸҗеҮәзҡ„йҡҸжңәжҺ§еҲ¶иҜ•йӘҢ并дёҚиғҪиў«з…§жҗ¬з…§еҘ—жқҘз ”з©¶дёӯеӣҪзҡ„иҙ«еӣ°й—®йўҳгҖӮдҫӢеҰӮпјҢдёӯеӣҪеҫҲеӨҡжү¶иҙ«жҺӘж–Ҫ并дёҚжҳҜж №жҚ®йҡҸжңәжҺ§еҲ¶иҜ•йӘҢж–№жі•иҖҢи®ҫи®ЎеҮәжқҘзҡ„пјҢеӣ жӯӨиҝҷдәӣж–№жі•еҸҜд»ҘеҖҹйүҙпјҢдҪҶжҳҜйңҖиҰҒж №жҚ®дёӯеӣҪе®һйҷ…жғ…еҶөеҠ д»Ҙж”№йҖ дёҺеҲӣж–°гҖӮ
д»ҘдёҠдёӨдёӘе®һдҫӢиЎЁжҳҺпјҢдёӯеӣҪз»ҸжөҺеӯҰз ”з©¶дёҺдё–з•ҢдёҖжөҒз»ҸжөҺеӯҰз ”з©¶ж°ҙе№ізӣёжҜ”пјҢдёҖдёӘжҜ”иҫғеӨ§зҡ„е·®и·қеңЁдәҺз ”з©¶иҢғејҸдёҺз ”з©¶ж–№жі•пјҢзү№еҲ«жҳҜзјәе°‘з¬ҰеҗҲ科еӯҰз ”з©¶иҢғејҸеҗҢж—¶еҸҲйҖӮеҗҲдәҺдёӯеӣҪжғ…жҷҜзҡ„е®ҡйҮҸе®һиҜҒз ”з©¶ж–№жі•зҡ„еҲӣж–°дёҺеә”з”ЁгҖӮ
еӣӣгҖҒеӨ§ж•°жҚ®зҡ„зү№зӮ№е’ҢжңәеҷЁеӯҰд№ зҡ„жң¬иҙЁ
еңЁеӨ§ж•°жҚ®ж—¶д»ЈпјҢдёҮзү©зҡҶеҸҜдә’иҒ”пјҢд»»дҪ•з»ҸжөҺжҙ»еҠЁйғҪдјҡз•ҷдёӢз—•иҝ№пјҢжүҖжңүз»ҸжөҺзҺ°иұЎйғҪеҸҜз”ЁеӨ§ж•°жҚ®жҸҸиҝ°гҖӮеӨ§ж•°жҚ®еӨ§йғҪдёәй«ҳйў‘з”ҡиҮіе®һж—¶ж•°жҚ®пјҢжқҘжәҗе№ҝжіӣпјҢеҪўејҸеӨҡж ·пјҢз§Қзұ»з№ҒеӨҡпјҢж—ўжңүз»“жһ„еҢ–ж•°жҚ®пјҢд№ҹжңүйқһз»“жһ„еҢ–ж•°жҚ®пјҢеҰӮж–Үжң¬гҖҒеӣҫеҪўгҖҒйҹійў‘гҖҒи§Ҷйў‘зӯүгҖӮиҝҷдәӣж•°жҚ®еҢ…еҗ«еҗ„з§Қдё°еҜҢзҡ„дҝЎжҒҜпјҢжө·йҮҸеӨ§ж•°жҚ®еҸҚиҝҮжқҘеҸҲдјҡй©ұеҠЁж–°зҡ„з»ҸжөҺжҙ»еҠЁгҖӮеӨ§ж•°жҚ®еӣ жӯӨдёәз»ҸжөҺеӯҰе’Ңдәәж–ҮзӨҫдјҡ科еӯҰзҡ„е®һиҜҒз ”з©¶жҸҗдҫӣдәҶеӨ§йҮҸдё°еҜҢзҡ„ж•…дәӢдёҺзҙ жқҗпјҢеҗҢж—¶д№ҹеңЁж”№еҸҳз»ҸжөҺеӯҰе’Ңдәәж–ҮзӨҫдјҡ科еӯҰзҡ„з ”з©¶иҢғејҸдёҺз ”з©¶ж–№жі•гҖӮзӣ®еүҚпјҢеӨ§ж•°жҚ®е’Ңдәәе·ҘжҷәиғҪжҠҖжңҜжӯЈеңЁжҺЁеҠЁз¬¬еӣӣж¬Ўе·Ҙдёҡйқ©е‘Ҫзҡ„蓬еӢғеҸ‘еұ•гҖӮз”ұдәҺдәәеҸЈи§„жЁЎгҖҒз»ҸжөҺ规模д»ҘеҸҠдёӯеӣҪж”ҝеәңвҖңдә’иҒ”зҪ‘ +вҖқзӯүдёҖзі»еҲ—жҺЁеҠЁж•°еӯ—з»ҸжөҺеҸ‘еұ•зҡ„ж”ҝзӯ–пјҢдёӯеӣҪеңЁеӨ§ж•°жҚ®иө„жәҗдёҠе…·жңүдёҖе®ҡдјҳеҠҝгҖӮжҢүз…§ж•°жҚ®з”ҹжҲҗжҖ»еҖјпјҲGross Data ProductпјҢGDPпјүпјҢдёӯеӣҪзӣ®еүҚеңЁе…ЁзҗғжҺ’еҲ—第дёүпјҢж¬ЎдәҺзҫҺеӣҪе’ҢиӢұеӣҪпјҢеҗҢж—¶еўһй•ҝйҖҹеәҰйқһеёёеҝ«пјҲChakravort et al., 2019пјүгҖӮжӯӨеӨ–пјҢдёӯеӣҪж”ҝеәңжӢҘжңүеӨ§йҮҸзҡ„вҖңж”ҝзӯ–ж•°жҚ®еә“вҖқпјҢеҢ…жӢ¬еҗ„з§Қж”ҝеәңж–Үжң¬ж•°жҚ®пјҢиҝҷжҳҜдёӯеӣҪз»ҸжөҺеӯҰе®¶з ”з©¶ж”ҝеәңдёҺеёӮеңәиҝҷдёӘз»ҸжөҺеӯҰеҹәжң¬е…ізі»зҡ„еӨ©з„¶зҡ„зӢ¬зү№зҡ„ж•°жҚ®дјҳеҠҝгҖӮеҰӮдҪ•е°ҶеӨ§ж•°жҚ®иө„жәҗдјҳеҠҝиҪ¬еҢ–дёәз»ҸжөҺеӯҰзҡ„з ”з©¶дјҳеҠҝпјҢжҳҜдёӯеӣҪз»ҸжөҺеӯҰ家йқўдёҙзҡ„дёҖдёӘйҮҚиҰҒй—®йўҳгҖӮ
дј—жүҖе‘ЁзҹҘпјҢеӨ§ж•°жҚ®е…·жңү规模жҖ§пјҲvolumeпјүгҖҒй«ҳйҖҹжҖ§пјҲvelocityпјүгҖҒеӨҡж ·жҖ§пјҲvarietyпјүгҖҒеҮҶзЎ®жҖ§пјҲveracityпјүзӯүзү№зӮ№гҖӮжүҖ谓规模жҖ§дё»иҰҒдҪ“зҺ°еңЁдёӨдёӘз»ҙеәҰпјҡдёҖжҳҜж ·жң¬е®№йҮҸеӨ§пјҢж ·жң¬е®№йҮҸеӨ§еӨ§и¶…иҝҮи§ЈйҮҠеҸҳйҮҸзҡ„ж•°зӣ®пјҢиҝҷз§°дёәй«ҳеӨ§ж•°жҚ®пјӣдәҢжҳҜеҸҳйҮҸж•°зӣ®еӨҡпјҢи§ЈйҮҠеҸҳйҮҸзҡ„ж•°зӣ®и¶…иҝҮж ·жң¬е®№йҮҸзҡ„дёӘж•°пјҢиҝҷз§°дёәиғ–еӨ§ж•°жҚ®пјҢжҳҜдёҖз§Қй«ҳз»ҙжҲ–и¶…й«ҳз»ҙж•°жҚ®гҖӮиҝҷз§Қж•°жҚ®ж—ўз»ҷи®ЎйҮҸз»ҸжөҺе»әжЁЎжҸҗдҫӣдәҶеҫҲеӨ§зҒөжҙ»жҖ§пјҢд№ҹеёҰжқҘдәҶжүҖи°“вҖңз»ҙеәҰзҒҫйҡҫвҖқпјҲcurse of dimensionalityпјүзҡ„жҢ‘жҲҳгҖӮеӨҡж ·жҖ§жҳҜжҢҮеӨ§ж•°жҚ®ж—ўжңүз»“жһ„еҢ–ж•°жҚ®пјҢеҸҲжңүйқһз»“жһ„еҢ–ж•°жҚ®пјҢйқһз»“жһ„еҢ–ж•°жҚ®жҸҗдҫӣдәҶдј з»ҹж•°жҚ®жүҖжІЎжңүзҡ„дё°еҜҢдҝЎжҒҜпјҢиҝҷж ·еҸҜжһҒеӨ§ең°жӢ“еұ•з»ҸжөҺеӯҰз ”з©¶зҡ„иҫ№з•ҢдёҺиҢғеӣҙгҖӮй«ҳйҖҹжҖ§жҳҜжҢҮй«ҳйў‘ж•°жҚ®з”ҡиҮіе®һж—¶ж•°жҚ®зҡ„еҸҜиҺ·еҫ—жҖ§гҖӮиҖҢеҮҶзЎ®жҖ§еҲҷжҳҜжҢҮеӨ§ж•°жҚ®е®№йҮҸеҫҲеӨ§пјҢеҷӘйҹіеҸҜиғҪеҫҲеӨ§пјҢеӣ жӯӨдҝЎжҒҜеҜҶеәҰиҫғдҪҺпјҢиҝҷйҮҢз»ҹи®ЎеӯҰдёҖдәӣеҹәжң¬еҺҹзҗҶпјҢеҰӮе……еҲҶжҖ§еҺҹзҗҶе’ҢйҷҚз»ҙеҺҹеҲҷпјҢеңЁжҖ»з»“гҖҒжҸҗеҸ–ж•°жҚ®дҝЎжҒҜж—¶е°ұжҳҫеҫ—йқһеёёжңүз”ЁгҖӮеҗҢж—¶пјҢз”ұдәҺеӨ§ж•°жҚ®з»“жһ„еӨҚжқӮгҖҒеҪўејҸеӨҡж ·пјҢдҝЎеҸ·еҷӘеЈ°йҖҡеёёжҜ”иҫғдҪҺпјҢдј з»ҹзҡ„з»ҹи®Ўе……еҲҶжҖ§еҺҹзҗҶе’ҢйҷҚз»ҙж–№жі•йңҖиҰҒжңүжүҖеҲӣж–°дёҺеҸ‘еұ•гҖӮ
жңәеҷЁеӯҰд№ ж—©еңЁ 1959 е№ҙе°ұе·ІжҸҗеҮәпјҢдҪҶзңҹжӯЈеӨ§и§„жЁЎеә”з”ЁжҳҜеңЁеӨ§ж•°жҚ®еҮәзҺ°д№ӢеҗҺгҖӮиҝҷжҳҜдёҖй—ЁеӨҡйўҶеҹҹдәӨеҸүеӯҰ科пјҢж¶үеҸҠжҰӮзҺҮи®әгҖҒз»ҹи®ЎеӯҰгҖҒж•°еӯҰпјҲеҰӮйҖјиҝ‘и®әгҖҒеҮёеҲҶжһҗпјүгҖҒеӨҚжқӮз®—жі•зҗҶи®әзӯүеӯҰ科пјҢз ”з©¶и®Ўз®—жңәеҰӮдҪ•еҹәдәҺж•°жҚ®иҮӘеҠЁжЁЎжӢҹжҲ–е®һзҺ°дәәзұ»зҡ„еӯҰд№ иЎҢдёәпјҢд»ҘиҺ·еҸ–ж–°зҡ„зҹҘиҜҶжҲ–жҠҖиғҪгҖӮе®ғжҳҜдәәе·ҘжҷәиғҪзҡ„ж ёеҝғпјҢйҖҡиҝҮеҹәдәҺз»ҸйӘҢпјҲж•°жҚ®пјүиғҪеӨҹиҮӘеҠЁж”№иҝӣзҡ„и®Ўз®—жңәз®—жі•пјҢдҪҝи®Ўз®—жңәе…·жңүдёҖе®ҡзҡ„жҷәиғҪеӯҰд№ иғҪеҠӣпјҢиҝӣиЎҢзІҫеҮҶйў„жөӢдёҺеҶізӯ–гҖӮжңәеҷЁеӯҰд№ еёёи§Ғзҡ„ж–№жі•еҢ…жӢ¬иҙқеҸ¶ж–ҜеӯҰд№ пјҲBayesian LearningпјүгҖҒK- жңҖиҝ‘йӮ»жі•пјҲK-Nearest NeighborпјҢKNNпјүгҖҒеҶізӯ–ж ‘пјҲdecision treeпјүгҖҒйҡҸжңәжЈ®жһ—пјҲrandom forestпјүгҖҒж”ҜжҢҒеҗ‘йҮҸжңәпјҲSupport Vector MachineпјҢSVMпјүгҖҒдәәе·ҘзҘһз»ҸзҪ‘з»ңпјҲArtifi cial Neural NetworkпјҢANNпјүгҖҒж·ұеәҰеӯҰд№ пјҲdeep learningпјүзӯүпјҲйҷҲејәпјҢ2020пјүгҖӮжңәеҷЁеӯҰд№ зҡ„еҫҲеӨҡж–№жі•жң¬иҙЁдёҠжҳҜж•°еӯҰеҮҪж•°еҪўејҸйҷҗеҲ¶е°‘гҖҒжЁЎеһӢзҒөжҙ»жҖ§й«ҳзҡ„йқһеҸӮж•°еҲҶжһҗж–№жі•пјҢеҰӮ k- жңҖиҝ‘йӮ»жі•гҖҒеҶізӯ–ж ‘гҖҒйҡҸжңәжЈ®жһ—гҖҒдәәе·ҘзҘһз»ҸзҪ‘з»ңгҖҒж·ұеәҰеӯҰд№ зӯүгҖӮдҫӢеҰӮпјҢдәәе·ҘзҘһз»ҸзҪ‘з»ңпјҲANNпјүе°ұжҳҜд»ҝз…§и®ӨзҹҘ科еӯҰиҝӣиЎҢдҝЎжҒҜеӨ„зҗҶиҝҮзЁӢзҡ„дёҖдёӘж•°еӯҰжЁЎеһӢпјҲи§Ғеӣҫ 4пјүпјҢе…¶жң¬иә«жҳҜдёҖз§ҚйқһеҸӮж•°з»ҹи®ЎжЁЎеһӢпјҢиҖҢж·ұеәҰеӯҰд№ жҳҜжӣҙй«ҳеұӮж¬Ўзҡ„дәәе·ҘзҘһз»ҸзҪ‘з»ңгҖӮж—©еңЁ 20 дёӘдё–зәӘ 80 е№ҙд»ЈпјҢи‘—еҗҚи®ЎйҮҸз»ҸжөҺеӯҰ家 WhiteпјҲ1989пјүе°ұиҜҒжҳҺдәҶеҸӘиҰҒж ·жң¬е®№йҮҸи¶іеӨҹеӨ§пјҢANN еҸҜд»Ҙж— йҷҗйҖјиҝ‘д»»дҪ•дёҖдёӘжңӘзҹҘзҡ„еӣһеҪ’еҮҪж•°пјҢд»–еңЁдәәе·ҘзҘһз»ҸзҪ‘з»ңжЁЎеһӢйўҶеҹҹеҒҡеҮәдәҶеҺҹеҲӣжҖ§зҡ„зҗҶи®әиҙЎзҢ®гҖӮ20 дё–зәӘ 90 е№ҙд»ЈпјҢANN е№ҝжіӣеә”з”ЁдәҺз»ҸжөҺеӯҰдёҺйҮ‘иһҚеӯҰзҡ„е®һиҜҒз ”з©¶дёӯпјҢдҪҶ ANN йў„жөӢйҮ‘иһҚж•°жҚ®зҡ„ж•Ҳжһң并дёҚзҗҶжғіпјҢиҝҷеҸҜиғҪдёҺеҪ“ж—¶и®Ўз®—жңәзҡ„и®Ўз®—иғҪеҠӣгҖҒиҝҗз®—йҖҹеәҰдёҺз®—жі•зӯүеӣ зҙ жңүе…іпјҢеҪ“然д№ҹеҸҜиғҪдёҺз»ҸжөҺйҮ‘иһҚж—¶й—ҙеәҸеҲ—ж•°жҚ®е…·жңүж—¶еҸҳжҖ§зӯүзү№зӮ№жңүе…ігҖӮйҡҸзқҖжө·йҮҸеӨ§ж•°жҚ®зҡ„еҸҜиҺ·еҫ—жҖ§е’Ңи®Ўз®—иғҪеҠӣзҡ„еӨ§е№…жҸҗеҚҮпјҢANN ж ·жң¬еӨ–йў„жөӢзІҫзЎ®еәҰеӨ§е№…жҸҗеҚҮпјҢе·Іе№ҝжіӣжҲҗеҠҹеә”з”ЁдәҺиҜӯйҹідёҺдәәи„ёиҜҶеҲ«зӯүйўҶеҹҹгҖӮ

еӨ§ж•°жҚ®з”ұдәҺе…¶жө·йҮҸзү№жҖ§еҸҠеҪўејҸеӨҚжқӮеӨҡж ·пјҢж—ўжңүз»“жһ„еҢ–ж•°жҚ®пјҢеҸҲжңүйқһз»“жһ„еҢ–ж•°жҚ®пјҢеӣ жӯӨдҫқйқ дәәе·ҘжҳҜж— жі•иҝӣиЎҢеӨ§ж•°жҚ®еҲҶжһҗзҡ„пјҢеҝ…йЎ»еҖҹеҠ©дәәе·ҘжҷәиғҪжҠҖжңҜгҖӮжңәеҷЁеӯҰд№ жҳҜдёҖз§ҚеҲҶжһҗеӨ§ж•°жҚ®зҡ„дәәе·ҘжҷәиғҪжҠҖжңҜпјҢз”ұдәҺдә‘и®Ўз®—зҡ„еҮәзҺ°иҖҢеңЁе®һйҷ…дёӯиҺ·еҫ—дәҶе№ҝжіӣеә”з”ЁгҖӮе…·дҪ“ең°иҜҙпјҢжңәеҷЁеӯҰд№ еҲ©з”Ёи®Ўз®—жңәз®—жі•зЁӢеәҸиҮӘеҠЁеҲҶжһҗеӨ§ж•°жҚ®пјҢ并еҹәдәҺеӨ§ж•°жҚ®иҝӣиЎҢж ·жң¬еӨ–йў„жөӢпјҲеҢ…жӢ¬еҲҶзұ»пјүгҖӮжң¬иҙЁдёҠпјҢж ·жң¬еӨ–йў„жөӢе’ҢеҲҶзұ»жҳҜдёҖдёӘжіӣеҢ–пјҲgeneralizationпјүиҝҮзЁӢпјҢеҚід»ҺдёҖдёӘи®ӯз»ғж•°жҚ®пјҲtraining dataпјүдёӯеӯҰд№ ж•°жҚ®зҡ„зі»з»ҹзү№еҫҒпјҢзү№еҲ«жҳҜж•°жҚ®дёӯеҸҳйҮҸзү№еҫҒд»ҘеҸҠеҸҳйҮҸд№Ӣй—ҙзҡ„з»ҹи®Ўе…ізі»пјҲеҰӮзӣёе…іжҖ§пјүпјҢ然еҗҺз”ЁдәҺеӨ–жҺЁйў„жөӢеҸҰдёҖдёӘжңӘзҹҘж•°жҚ®гҖӮиҝҷдёҖзү№зӮ№зұ»дјјдәҺз»ҹи®ЎжҺЁж–ӯгҖӮж ·жң¬еӨ–йў„жөӢзҡ„зІҫеҮҶжҖ§пјҢеҸ–еҶідәҺи®ӯз»ғж•°жҚ®дёҺжңӘзҹҘж•°жҚ®зҡ„зі»з»ҹзү№еҫҒпјҲеҰӮз»ҹи®Ўе…ізі»пјүжҳҜеҗҰе…·жңүзӣёдјјжҖ§пјҢиҝҷеҶіе®ҡжіӣеҢ–иғҪеҠӣзҡ„ејәејұгҖӮжңәеҷЁеӯҰд№ з®—жі•еҸҜиЎЁзӨәдёәдёҖдёӘеҹәдәҺж•°жҚ®зҡ„ж•°еӯҰдјҳеҢ–й—®йўҳпјҢйҖҡиҝҮи®Ўз®—жңәз®—жі•зЁӢеәҸи®ҫи®ЎжқҘиҮӘеҠЁе®һзҺ°гҖӮжңәеҷЁеӯҰд№ ж ·жң¬еӨ–еҮҶзЎ®йў„жөӢзҡ„е…ій”®еңЁдәҺйҳІжӯўиҝҮеәҰжӢҹеҗҲпјҲoverfittingпјүгҖӮд»Җд№ҲжҳҜиҝҮеәҰжӢҹеҗҲпјҹдёҖиҲ¬жқҘиҜҙпјҢдёҖдёӘж•°жҚ®еҸҜиў«еҲҶжҲҗдёӨйғЁеҲҶпјҢдёҖйғЁеҲҶжҳҜи®ӯз»ғж•°жҚ®пјҢз”ЁжқҘдј°и®Ўз®—жі•зҡ„з»“жһ„еҸӮж•°жҲ–иҖ…жЁЎеһӢеҸӮж•°пјҢд»ҘеҶіе®ҡз®—жі•зҡ„еӨҚжқӮзЁӢеәҰпјӣеҸҰдёҖйғЁеҲҶжҳҜжөӢиҜ•ж•°жҚ®пјҲtest dataпјүпјҢз”ЁдәҺжөӢиҜ•з”ұи®ӯз»ғж•°жҚ®иҺ·еҫ—зҡ„з®—жі•зҡ„йў„жөӢзІҫзЎ®еәҰгҖӮз®—жі•дё»иҰҒжҳҜжҢ–жҺҳи®ӯз»ғж•°жҚ®дёӯеҸҳйҮҸзү№еҫҒд»ҘеҸҠеҸҳйҮҸд№Ӣй—ҙзҡ„з»ҹи®Ўе…ізі»пјҢ然еҗҺз”ЁдәҺйў„жөӢжөӢиҜ•ж•°жҚ®гҖӮеҰӮжһңз®—жі•еҲ»з”»дәҶеӯҳеңЁдәҺи®ӯз»ғж•°жҚ®дҪҶдёҚдјҡеңЁжңӘзҹҘж•°жҚ®пјҲеҰӮжөӢиҜ•ж•°жҚ®пјүдёӯйҮҚеӨҚеҮәзҺ°зҡ„зі»з»ҹзү№еҫҒдёҺз»ҹи®Ўе…ізі»пјҢе°ұдјҡеҮәзҺ°иҝҮеәҰжӢҹеҗҲгҖӮжӯӨж—¶пјҢиҷҪ然еҜ№и®ӯз»ғж•°жҚ®зҡ„жӢҹеҗҲж•ҲжһңеҫҲеҘҪпјҢдҪҶдёҚдјҡеңЁжңӘжқҘж•°жҚ®дёӯеҮәзҺ°зҡ„иҝҷйғЁеҲҶж•°жҚ®зү№еҫҒпјҢе°ұдјҡжҲҗдёәж— з”Ёзҡ„еҷӘйҹіпјҢйҷҚдҪҺж ·жң¬еӨ–йў„жөӢзҡ„зІҫеҮҶеәҰпјҢеӣ жӯӨйңҖиҰҒе°ҪйҮҸеҮҸе°‘гҖӮдёәжӯӨпјҢжңүеҝ…иҰҒеј•е…Ҙжғ©зҪҡйЎ№пјҢд»ҘжҺ§еҲ¶з®—жі•зҡ„еӨҚжқӮжҖ§зЁӢеәҰгҖӮз”Ёз»ҹи®ЎеӯҰжңҜиҜӯиҜҙпјҢжғ©зҪҡйЎ№е°Ҷжҳҫи‘—еҮҸе°‘йў„жөӢзҡ„ж–№е·®пјҲvarianceпјүпјҢиҷҪ然е®ғдёҖиҲ¬дјҡеўһеҠ йў„жөӢзҡ„еҒҸе·®пјҲbiasпјүгҖӮйҖҡиҝҮдјҳеҢ–еҠ дёҠжғ©зҪҡйЎ№еҗҺзҡ„зӣ®ж ҮеҮҪж•°пјҢдёҚж–ӯеӯҰд№ и®ӯз»ғж•°жҚ®пјҢеҸҜдҪҝз®—жі•еҫ—еҲ°иҝӣдёҖжӯҘдјҳеҢ–пјҢеңЁйў„жөӢж–№е·®дёҺеҒҸе·®д№Ӣй—ҙеҸ–еҫ—е№іиЎЎпјҢжңҖе°ҸеҢ–жіӣеҢ–иҜҜе·®гҖӮйҖҡеёёпјҢдёҖдёӘиҫғе°Ҹзҡ„еҒҸе·®еўһеҠ пјҢеҸҜжҚўжқҘдёҖдёӘиҫғеӨ§зҡ„ж–№е·®еҮҸе°‘гҖӮеңЁе®һйҷ…еә”з”ЁдёӯпјҢеҹәдәҺеӨ§ж•°жҚ®жңәеҷЁеӯҰд№ зҡ„ж ·жң¬еӨ–йў„жөӢеӨ§еӨҡжҜ”иҫғеҮҶзЎ®пјҢиҝҷз§ҚзІҫеҮҶйў„жөӢ并дёҚжҳҜеҹәдәҺз»ҸжөҺеӣ жһңе…ізі»пјҢиҖҢжҳҜеҹәдәҺеӨ§ж•°жҚ®дёӯзҡ„еҸҳйҮҸзү№еҫҒдёҺеҸҳйҮҸд№Ӣй—ҙзҡ„з»ҹи®Ўе…ізі»пјҢжҜ”еҰӮејәзӣёе…іжҖ§ж„Ҹе‘ізқҖеңЁжңӘзҹҘж•°жҚ®дёӯйҮҚеӨҚеҮәзҺ°зҡ„жҰӮзҺҮжҜ”иҫғеӨ§гҖӮиҝҷдәӣз»ҹи®Ўе…ізі»еҜ№дәҺйў„жөӢеҫҲжңүеё®еҠ©пјҢдҪҶз®—жі•жң¬иә«еғҸдёҖдёӘй»‘з®ұпјҢж— жі•иҫЁеҲ«жҳҜи°Ғеј•иө·зҡ„и°Ғзҡ„еҸҳеҢ–пјҢе…¶и§ЈйҮҠеҠӣеҫҲејұпјҢзү№еҲ«жҳҜдёҚеӯҳеңЁеӣ жһңе…ізі»зҡ„и§ЈйҮҠгҖӮеңЁиҝҷдёӘж„Ҹд№үдёҠпјҢиҜәиҙқе°”з»ҸжөҺеӯҰеҘ–еҫ—дё»жүҳ马ж–ҜВ·иҗЁйҮ‘зү№пјҲThomas SargentпјүжҢҮеҮәпјҢвҖңдәәе·ҘжҷәиғҪеҸӘжҳҜдҪҝз”ЁдәҶдёҖдәӣеҚҺдёҪзҡ„иҫһи—»пјҢе…¶е®һе°ұжҳҜз»ҹи®ЎеӯҰвҖқгҖӮ
жңәеҷЁеӯҰд№ е·Іе№ҝжіӣеә”з”ЁдәҺж•°еӯ—з»ҸжөҺжҙ»еҠЁдёӯгҖӮдҫӢеҰӮпјҢз®—жі•дәӨжҳ“пјҲalgorithmictradingпјүпјҢеңЁеӣҪеҶ…д№ҹиҜ‘дёәйҮҸеҢ–дәӨжҳ“пјҢж—©еңЁ 20 дё–зәӘ 90 е№ҙд»Је°ұејҖе§Ӣеә”з”ЁдәҺйҮ‘иһҚеёӮеңәпјҢзҺ°еңЁеӨ–жұҮеёӮеңә 85% д»ҘдёҠзҡ„дәӨжҳ“йғҪжҳҜз®—жі•дәӨжҳ“е®ҢжҲҗзҡ„гҖӮжұҪиҪҰж— дәәй©ҫ驶д№ҹжҳҜеҹәдәҺеӨ§ж•°жҚ®зӣёе…іжҖ§еҲҶжһҗпјҢйҖҡиҝҮжңәеҷЁеӯҰд№ еҜ№еҢ…жӢ¬еҗ„з§ҚдәӨйҖҡиЎҢдёәдёҺзҺ°иұЎзҡ„еӨ§йҮҸз»ҸйӘҢж•°жҚ®иҝӣиЎҢиҮӘеҠЁеӯҰд№ дёҺйў„жөӢпјҢжҢҮеҜјжұҪиҪҰиЎҢ驶гҖӮжңәеҷЁеӯҰд№ д№ҹеңЁеҫҲеӨҡйўҶеҹҹејҖе§Ӣд»Јжӣҝдәәе·ҘпјҢеҢ…жӢ¬йҖҹи®°гҖҒж–Үеӯ—зҝ»иҜ‘гҖҒеҗҢеЈ°дј иҜ‘гҖҒдјҡи®ЎгҖҒж–°й—»еҶҷдҪңз”ҡиҮіеӯҰжңҜи®әж–ҮеҶҷдҪңзӯүгҖӮ

жӯӨеӨ–пјҢжңәеҷЁеӯҰд№ д№ҹеҲӣж–°дәҶдёҖдәӣе•ҶдёҡжЁЎејҸпјҢеҰӮдҝЎз”ЁеҚЎдёҺе°Ҹйўқиҙ·ж¬ҫе®Ўжү№пјҢжңәеҷЁеӯҰд№ йҖҡиҝҮеҜ№дјҒдёҡдёҺдёӘдәәзҡ„еӨ§ж•°жҚ®дҝЎжҒҜеҲҶжһҗпјҢеҸҜд»Ҙйў„жөӢе…¶дҝЎз”ЁйЈҺйҷ©ж°ҙе№іпјҢд»ҺиҖҢеҶіе®ҡжҳҜеҗҰйҖҡиҝҮдҝЎз”ЁеҚЎжҲ–иҙ·ж¬ҫе®Ўжү№гҖӮдәәе·ҘжҷәиғҪеҜ№еҠіеҠЁеёӮеңәд№ҹдә§з”ҹдәҶж·ұеҲ»еҪұе“ҚпјҢе·ІеҮәзҺ°зҡ„жүҖи°“зҡ„вҖңж— дәәз»ҸжөҺвҖқпјҢе…¶е®һе°ұжҳҜдәәе·ҘжҷәиғҪжӣҝд»Је·ҘдәәгҖӮеӨ§ж•°жҚ®е’Ңдәәе·ҘжҷәиғҪиҝҳдјҡеҪұе“ҚиҙўеҜҢ收е…Ҙзҡ„еҲҶй…ҚгҖӮдҫӢеҰӮпјҢеҫ·еӣҪжҖ»зҗҶй»ҳе…Ӣе°”еңЁ 2018 е№ҙ 6 жңҲе…Ёзҗғз»ҸжөҺи®әеқӣдёҠжҸҗеҲ°пјҢвҖңж•°жҚ®зҡ„е®ҡд»·пјҢе°Өе…¶жҳҜж¶Ҳиҙ№иҖ…ж•°жҚ®е®ҡд»·пјҢжҳҜжңӘжқҘдё»иҰҒзҡ„е…¬е№ій—®йўҳгҖӮеҗҰеҲҷдҪ е°Ҷдјҡз»ҸеҺҶдёҖдёӘйқһеёёдёҚе…¬е№ізҡ„дё–з•ҢпјҢдәә们е…Қиҙ№жҸҗдҫӣж•°жҚ®пјҢиҖҢе…¶д»–дәәеҲҷеҲ©з”Ёж•°жҚ®иөҡй’ұгҖӮж•°жҚ®жҳҜжңӘжқҘзҡ„еҺҹжқҗж–ҷгҖӮвҖҰвҖҰдё–з•ҢдёҠеӯҳеңЁе·ЁеӨ§зҡ„дёҚе…¬е№ійЈҺйҷ©пјҢжҲ‘们еҝ…йЎ»е°Ҷе…¶зәіе…ҘжҲ‘们зҡ„зЁҺ收дҪ“зі»гҖӮвҖқж•°жҚ®дҪңдёәдёҖз§Қе…ій”®зҡ„з”ҹдә§иҰҒзҙ пјҢзү№еҲ«жҳҜеӨ§ж•°жҚ®е’Ңдәәе·ҘжҷәиғҪеҜ№з»ҸжөҺзҡ„еҪұе“ҚпјҢеҢ…жӢ¬еҜ№з”ҹдә§еҠӣе’Ңз”ҹдә§е…ізі»зҡ„еҪұе“ҚпјҢиҝҷж— з–‘жҳҜз»ҸжөҺеӯҰзҡ„йҮҚиҰҒз ”з©¶еҶ…е®№пјҲжҙӘж°ёж·јгҖҒеј жҳҺпјҢ2020пјүгҖӮдёҺжӯӨеҗҢж—¶пјҢз”ұдәҺз»ҸжөҺеӯҰе®һиҜҒз ”з©¶д»Ҙж•°жҚ®дёәеҹәзЎҖпјҢж•°жҚ®зү№зӮ№зҡ„ж”№еҸҳд»ҘеҸҠж•°жҚ®еҲҶжһҗжҠҖжңҜзҡ„еҸҳеҢ–пјҢд№ҹдёҚеҸҜйҒҝе…Қең°еҪұе“ҚдәҶз»ҸжөҺеӯҰзҡ„з ”з©¶иҢғејҸдёҺз ”з©¶ж–№жі•гҖӮжҙӘж°ёж·јгҖҒжұӘеҜҝйҳіпјҲ2021пјүжҺўи®ЁдәҶеӨ§ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ еҜ№з»ҹи®ЎеӯҰзҡ„еҪұе“ҚпјҢдёӢж–Үе°ҶиҒҡз„Ұи®Ёи®әеңЁж•°еӯ—з»ҸжөҺж—¶д»ЈпјҢеӨ§ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ еҜ№з»ҸжөҺеӯҰзҡ„з ”з©¶иҢғејҸдёҺз ”з©¶ж–№жі•жүҖеёҰжқҘзҡ„жңәйҒҮе’ҢжҢ‘жҲҳгҖӮ
дә”гҖҒеӨ§ж•°жҚ®е’Ңдәәж–Үз»ҸжөҺеӯҰз ”з©¶
еңЁеӨ§ж•°жҚ®ж—¶д»ЈпјҢзү№еҲ«жҳҜжңүдәҶеӨ§йҮҸзҡ„ж–Үжң¬ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ з®—жі•пјҢж–Үжң¬еҸӘиғҪе®ҡжҖ§еҲҶжһҗзҡ„зҠ¶еҶөеӣ жӯӨеҫ—д»Ҙж”№еҸҳпјҢжҜ”иҫғзІҫзЎ®зҡ„е®ҡйҮҸе®һиҜҒеҲҶжһҗеҸҜд»Ҙеј•е…ҘпјҢиҖҢдё”з»ҸжөҺеӯҰд№ҹеҸҜд»ҺеҺҹжқҘдё»иҰҒз ”з©¶з»ҸжөҺй—®йўҳжң¬иә«пјҢжӢ“еұ•дёәз ”з©¶з»ҸжөҺеӣ зҙ дёҺж”ҝжІ»гҖҒжі•еҫӢгҖҒзӨҫдјҡгҖҒеҺҶеҸІгҖҒж–ҮеҢ–гҖҒдјҰзҗҶгҖҒеҝғзҗҶгҖҒз”ҹжҖҒзҺҜеўғгҖҒеҚ«з”ҹеҒҘеә·зӯүеӣ зҙ д№Ӣй—ҙзҡ„зӣёдә’иҒ”зі»дёҺзӣёдә’еҪұе“ҚпјҢд»ҺиҖҢжҺЁеҠЁз»ҸжөҺеӯҰе’Ңдәәж–ҮзӨҫдјҡ科еӯҰе…¶д»–йўҶеҹҹд№Ӣй—ҙзҡ„дәӨеҸүиһҚеҗҲе’Ңи·ЁеӯҰз§‘з ”з©¶гҖӮиҝҷз§Қз»ҸжөҺеӯҰдёҺдәәж–ҮзӨҫдјҡ科еӯҰдәӨеҸүиһҚеҗҲзҡ„з ”з©¶иҢғејҸе…·жңүжһҒе…¶йҮҚиҰҒзҡ„ж„Ҹд№үпјҢеӣ дёәз»ҸжөҺеҸӘжҳҜдәәзұ»зӨҫдјҡзҡ„дёҖдёӘз»„жҲҗйғЁеҲҶпјҲеҪ“然пјҢжҳҜйқһеёёйҮҚиҰҒзҡ„з»„жҲҗйғЁеҲҶпјүпјҢз»ҸжөҺе’Ңе…¶д»–дәәж–ҮзӨҫдјҡеӣ зҙ жҳҜеҜҶеҲҮзӣёе…ігҖҒзӣёдә’еҪұе“Қзҡ„гҖӮеӣ жӯӨпјҢеҜ№з»ҸжөҺзҡ„з ”з©¶пјҢеә”иҜҘж”ҫеҲ°дёҖдёӘжӣҙе№ҝжіӣзҡ„зӨҫдјҡз»ҸжөҺеҲҶжһҗжЎҶжһ¶дёӯеҠ д»Ҙзі»з»ҹз ”з©¶гҖӮиҝҷж ·зҡ„и·ЁйўҶеҹҹгҖҒи·ЁеӯҰ科зҡ„дәәж–Үз»ҸжөҺеӯҰзҡ„е®ҡйҮҸе®һиҜҒз ”з©¶иҢғејҸпјҢе°ҶжңүеҠ©дәҺжҲ‘们жӣҙж·ұеҲ»жӣҙзі»з»ҹең°зҗҶ解马е…ӢжҖқгҖҒжҒ©ж јж–Ҝе…ідәҺз»ҸжөҺеҹәзЎҖе’ҢдёҠеұӮе»әзӯ‘д№Ӣй—ҙгҖҒзӨҫдјҡеӯҳеңЁе’ҢзӨҫдјҡж„ҸиҜҶд№Ӣй—ҙпјҢд»ҘеҸҠдәәзұ»зӨҫдјҡдёҺз”ҹжҖҒзҺҜеўғд№Ӣй—ҙзҡ„иҫ©иҜҒе…ізі»пјҢ并д»ҺдёӯжүҫеҮәи§ЈеҶідәәзұ»йқўдёҙзҡ„йҮҚеӨ§з»ҸжөҺзӨҫдјҡй—®йўҳзҡ„зі»з»ҹеҠһжі•гҖӮ
е…ідәҺеӨ§ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ еҰӮдҪ•дҝғиҝӣдәәж–Үз»ҸжөҺеӯҰзҡ„е®ҡйҮҸе®һиҜҒз ”з©¶пјҢе…·дҪ“ең°иҜҙпјҢжҲ‘们е°Ҷйҳҗиҝ°еӨ§ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ еҰӮдҪ•еҪұе“Қз»ҸжөҺеӯҰе…ідәҺеҝғзҗҶжғ…ж„ҹгҖҒж”ҝжІ»жі•еҫӢгҖҒеҺҶеҸІж–ҮеҢ–гҖҒз”ҹжҖҒзҺҜеўғгҖҒеҚ«з”ҹеҒҘеә·зӯүеӣ зҙ зҡ„з ”з©¶гҖӮиҝҷдәӣз ”з©¶йўҶеҹҹжңүдёҚе°‘д№ӢеүҚе°ұе·Із»ҸеӯҳеңЁпјҢеҰӮжі•дёҺз»ҸжөҺеӯҰгҖҒж–°ж”ҝжІ»з»ҸжөҺеӯҰгҖҒж–ҮеҢ–з»ҸжөҺеӯҰгҖҒзҺҜеўғз»ҸжөҺеӯҰд»ҘеҸҠеҒҘеә·з»ҸжөҺеӯҰзӯүдәӨеҸүеӯҰ科пјҢдҪҶжҳҜжңүдәҶеӨ§ж•°жҚ®зү№еҲ«жҳҜж–Үжң¬ж•°жҚ®д№ӢеҗҺпјҢзҺ°еңЁеҸҜд»Ҙз”Ёж–Үжң¬еӣһеҪ’зӯүи®ЎйҮҸз»ҸжөҺеӯҰж–№жі•пјҢиҝӣиЎҢе®ҡйҮҸе®һиҜҒеҲҶжһҗгҖӮиҝҷж ·пјҢз»ҸжөҺеӯҰйҷӨдәҶе®ҡжҖ§еҲҶжһҗд№ӢеӨ–пјҢиҝҳеҸҜд»ҘеўһеҠ жӣҙеҠ дёҘи°Ёзҡ„е®ҡйҮҸе®һиҜҒеҲҶжһҗпјҢиҖҢдё”з ”з©¶зҡ„е№ҝеәҰгҖҒж·ұеәҰеӣ дёәдәӨеҸүеӯҰ科е’Ңи·ЁеӯҰз§‘з ”з©¶иҖҢеҸҜеҫ—еҲ°жһҒеӨ§жӢ“еұ•гҖӮ
з»ҸжөҺеӯҰе…ідәҺеҝғзҗҶжғ…ж„ҹзӯүдәәж–Үеӣ зҙ еҜ№з»ҸжөҺзҡ„еҪұе“Қзҡ„з ”з©¶пјҢе·ІжңүзӣёеҪ“й•ҝзҡ„еҺҶеҸІгҖӮеңЁгҖҠеӣҪеҜҢи®әгҖӢеҮәзүҲд№ӢеүҚпјҢдәҡеҪ“В·ж–ҜеҜҶпјҲSmithпјҢ1759пјүзҡ„еҸҰдёҖжң¬йҮҚиҰҒи‘—дҪңгҖҠйҒ“еҫ·жғ…ж“Қи®әгҖӢпјҲThe Theory of Moral SentimentsпјүпјҢе°ұжҸҗеҮәиҝҪжұӮдјҳеҢ–иЎҢдёәж—¶иҝҳйңҖиҰҒжңүдёҖе®ҡзҡ„йҒ“еҫ·жғ…ж“ҚгҖӮ19 дё–зәӘ 70 е№ҙд»Јзҡ„иҫ№йҷ…йқ©е‘ҪйҖҡиҝҮиҫ№йҷ…ж•Ҳз”ЁиҝҷдёӘйҮҚиҰҒжҰӮеҝөе°ҶеҝғзҗҶеӣ зҙ еј•е…Ҙз»ҸжөҺеӯҰзҡ„еҲҶжһҗжЎҶжһ¶д№ӢдёӯпјҢжүҖи°“зҡ„иҫ№йҷ…ж•Ҳз”Ёе°ұжҳҜз ”з©¶еҝғзҗҶеҒҸеҘҪеҜ№йңҖжұӮзҡ„еҪұе“ҚгҖӮеҮҜжҒ©ж–Ҝз»ҸжөҺеӯҰзҡ„иҫ№йҷ…ж¶Ҳиҙ№еҖҫеҗ‘е’ҢвҖңжөҒеҠЁжҖ§йҷ·йҳұвҖқгҖҒзҗҶжҖ§йў„жңҹпјҲRational ExpectationsпјүеӯҰжҙҫзҡ„вҖңеҚўеҚЎж–Ҝжү№еҲӨвҖқпјҲLucasпјҢ1976пјүпјҢеҚізҗҶжҖ§з»ҸжөҺдәәиғҪеӨҹжӯЈзЎ®йў„жөӢж”ҝеәңж”ҝзӯ–е№Ійў„зҡ„зӣ®зҡ„пјҢеӣ жӯӨж”№еҸҳиҮӘиә«зҡ„з»ҸжөҺиЎҢдёәпјҢд»ҺиҖҢеҜјиҮҙж”ҝзӯ–еӨұж•ҲпјҢжүҖжңүиҝҷдәӣйғҪдёҺз»ҸжөҺдё»дҪ“пјҲеҰӮж¶Ҳиҙ№иҖ…е’Ңз”ҹдә§иҖ…пјүзҡ„еҝғзҗҶеӣ зҙ еҜҶеҲҮзӣёе…ігҖӮйў„жңҹиҝҷдёӘз»ҸжөҺеӯҰеҹәжң¬еҝғзҗҶжҰӮеҝөпјҢе·Із»ҸжҲҗдёәе®Ҹи§Ӯз»ҸжөҺеӯҰз ”з©¶е’Ңе®Ҹи§Ӯз»ҸжөҺз®ЎзҗҶзҡ„йҮҚиҰҒжҰӮеҝөдёҺе·Ҙе…·гҖӮз»ҸжөҺдё»дҪ“дёәд»Җд№ҲдјҡеҪўжҲҗйў„жңҹпјҹе…¶е®һжҳҜеӣ дёәз»ҸжөҺеӯҳеңЁеҗ„з§ҚдёҚзЎ®е®ҡжҖ§пјҢеҰӮз»ҸжөҺеўһй•ҝдёҚзЎ®е®ҡжҖ§гҖҒйҖҡиҙ§иҶЁиғҖдёҚзЎ®е®ҡжҖ§гҖҒз»ҸжөҺж”ҝзӯ–дёҚзЎ®е®ҡжҖ§пјҲEconomicPolicy UncertaintyпјүзӯүпјҢз»ҸжөҺдё»дҪ“еңЁиҝӣиЎҢеҶізӯ–ж—¶пјҢйңҖиҰҒиҖғиҷ‘иҝҷдәӣдёҚзЎ®е®ҡжҖ§зҡ„еҪұе“ҚпјҢйҖҡиҝҮеҪўжҲҗдёҖе®ҡзҡ„жңҹжңӣпјҢеҶіе®ҡеҪ“дёӢзҡ„з»ҸжөҺиЎҢдёәгҖӮеӣ жӯӨпјҢз»ҸжөҺдёҚзЎ®е®ҡжҖ§йҖҡиҝҮз»ҸжөҺдё»дҪ“зҡ„йў„жңҹиҖҢеҜ№з»ҸжөҺпјҲеҰӮжҠ•иө„гҖҒж¶Ҳиҙ№пјүдә§з”ҹеҪұе“ҚгҖӮеңЁжҠ—з–«жңҹй—ҙпјҢдёӯеӣҪе®һж–Ҫзҡ„вҖңе…ӯзЁівҖқе’ҢвҖңе…ӯдҝқвҖқж”ҝзӯ–пјҢе…¶дёӯвҖңе…ӯзЁівҖқд№ӢдёҖжҳҜзЁійў„жңҹпјҢйҖҡиҝҮдёҖзі»еҲ—ж”ҝзӯ–е·Ҙе…·зЁіе®ҡз»ҸжөҺдё»дҪ“зҡ„еҝғзҗҶйў„жңҹпјҢеҮҸе°‘з–«жғ…дёҚзЎ®е®ҡжҖ§еҜ№з»ҸжөҺзҡ„еҶІеҮ»гҖӮ
еҸҰдёҖж–№йқўпјҢиЎҢдёәз»ҸжөҺеӯҰе’Ңе®һйӘҢз»ҸжөҺеӯҰз ”з©¶еҫ®и§Ӯдё»дҪ“еҝғзҗҶеҜ№з»ҸжөҺиЎҢдёәе’Ңз»ҸжөҺеҶізӯ–зҡ„еҪұе“ҚпјҢеҰӮзҘһз»Ҹз»ҸжөҺеӯҰпјҲNeuroeconomicsпјүиҝҗз”ЁзҘһз»Ҹ科еӯҰжҠҖжңҜжқҘз ”з©¶дёҺз»ҸжөҺеҶізӯ–зӣёе…ізҡ„зҘһз»ҸжңәеҲ¶пјҢз»јеҗҲдәҶз»ҸжөҺеӯҰгҖҒеҝғзҗҶеӯҰгҖҒ脑科еӯҰд»ҘеҸҠзҘһз»Ҹз”ҹзү©еӯҰзӯүиҜёеӨҡеӯҰ科方法жқҘз ”з©¶з»ҸжөҺеҶізӯ–иЎҢдёәзӯүгҖӮеҫҲд№…д»ҘеүҚпјҢи‘—еҗҚеҝғзҗҶеӯҰ家弗жҙӣдјҠеҫ·жӣҫжңҹжңӣеҝғзҗҶеӯҰиғҪеӨҹеҸ‘еұ•жҲҗдёәиҝҷж ·зҡ„дёҖ门科еӯҰпјҢеҚідәәзұ»зҡ„еҝғзҗҶжҙ»еҠЁи§„еҫӢиғҢеҗҺйғҪжңүдёҖе®ҡзҡ„з”ҹзү©еӯҰеҹәзЎҖгҖӮзҺ°д»ЈеҝғзҗҶеӯҰе’ҢзҘһз»Ҹз»ҸжөҺеӯҰйғҪе·Із»ҸиҫҫеҲ°иҝҷж ·дёҖз§Қеўғз•ҢгҖӮ
иҜәиҙқе°”з»ҸжөҺеӯҰеҘ–еҫ—дё»зҪ—дјҜзү№В·еёҢеӢ’пјҲShillerпјҢ2019пјүеҶҷдәҶдёҖжң¬д№ҰпјҢеҗҚдёәгҖҠеҸҷдәӢз»ҸжөҺеӯҰгҖӢпјҲNarrative Economics: How Stories Go Viral and Drive Major Economic EventsпјүпјҢдё»иҰҒз ”з©¶йҮҚиҰҒз»ҸжөҺеҸҷдәӢзҡ„дј ж’ӯжңәеҲ¶еҸҠе…¶еҜ№з»ҸжөҺзҡ„еҪұе“ҚгҖӮзңӢдјјжҳҜдёҖдёӘдёӘз»ҸжөҺж•…дәӢпјҢдҪҶе…¶дј ж’ӯзҡ„е№ҝеәҰгҖҒж·ұеәҰдёҺйҖҹеәҰйғҪдјҡеҜ№зӨҫдјҡзҫӨдҪ“еҝғзҗҶдә§з”ҹеҪұе“ҚпјҢиҝӣиҖҢеҪұе“Қз»ҸжөҺгҖӮд№ҰдёӯжҸҗеҲ°зҪ—ж–ҜзҰҸжҖ»з»ҹвҖңзӮүиҫ№и°ҲиҜқвҖқгҖҒжӢүеј—жӣІзәҝгҖҒжҜ”зү№еёҒзӯүзҫҺеӣҪз»ҸжөҺеҸҷдәӢгҖӮд»–и®ӨдёәжҜ”зү№еёҒд№ӢжүҖд»Ҙд»·ж јйЈһж¶ЁпјҢ并йқһе…¶иҮӘиә«д»·еҖјй«ҳпјҢиҖҢжҳҜе®ғеЎ‘йҖ зҡ„ж•…дәӢеҸ—еҲ°дәҶдәә们зҡ„зғӯжғ…иҝҪжҚ§гҖӮдёӯеӣҪеҗҢж ·жңүеҸҷдәӢз»ҸжөҺеӯҰгҖӮ20 дё–зәӘ 80 е№ҙд»ЈвҖңи®©дёҖйғЁеҲҶдәәе…ҲеҜҢиө·жқҘвҖқзҡ„еҸҷдәӢжҝҖеҠұеҠіеҠЁиҮҙеҜҢпјӣж·ұеңі 80 е№ҙд»Је’Ң 90 е№ҙд»Јзҡ„еҲӣдёҡж•…дәӢпјҢзү№еҲ«жҳҜвҖңж—¶й—ҙе°ұжҳҜйҮ‘й’ұпјҢж•ҲзҺҮе°ұжҳҜз”ҹе‘ҪвҖқпјҢйј“еҠұеҫҲеӨҡдәәдёӢжө·з»Ҹе•ҶпјҢзӯүзӯүгҖӮеҸҰеӨ–пјҢз»ҸжөҺжҙ»еҠЁе’ҢйҮ‘иһҚеёӮеңәдёӯзҡ„еёӮеңәжғ…з»ӘпјҲеҰӮжӮІи§ӮгҖҒжҒҗж…ҢпјүгҖҒиө„дә§жіЎжІ«гҖҒйҮ‘иһҚдј жҹ“з—…гҖҒзҫҠзҫӨж•Ҳеә”гҖҒ银иЎҢжҢӨе…‘зӯүз»ҸжөҺзҺ°иұЎпјҢйғҪдҪ“зҺ°дәҶзӨҫдјҡзҫӨдҪ“еҝғзҗҶеҜ№з»ҸжөҺжҲ–йҮ‘иһҚеёӮеңәзҡ„йҮҚиҰҒеҪұе“ҚгҖӮзӣ®еүҚеҸҷдәӢз»ҸжөҺеӯҰиҝҳеӨ„дәҺе©ҙе„ҝжңҹпјҢеёӯеӢ’еӢҫеӢ’дәҶдёҖдёӘеҲқжӯҘзҡ„еҲҶжһҗжЎҶжһ¶пјҢдҪҶе…¶з ”з©¶иҢғејҸиҝҳжңүеҫ…е®Ңе–„пјҢзү№еҲ«е®ҡжҖ§еҲҶжһҗеҠ дёҠз¬ҰеҗҲ科еӯҰз ”з©¶иҢғејҸзҡ„е®ҡйҮҸе®һиҜҒеҲҶжһҗпјҢеңЁиҝҷж–№йқўпјҢж–Үжң¬ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ еҸҜеҸ‘жҢҘйҮҚиҰҒдҪңз”ЁпјҢдҪҝеҸҷдәӢз»ҸжөҺеӯҰзҡ„е®ҡйҮҸе®һиҜҒз ”з©¶жҲҗдёәеҸҜиғҪгҖӮ
дёҖж®өж—¶й—ҙд»ҘжқҘпјҢе·ІжңүдёҚе°‘з»ҸжөҺеӯҰе®¶з ”з©¶жҠ•иө„иҖ…зҡ„жғ…з»ӘеҜ№йҮ‘иһҚеёӮеңәзҡ„еҪұе“ҚпјҢеҚіжүҖи°“зҡ„жҠ•иө„иҖ…жғ…з»ӘпјҲInvestor SentimentпјүеҜ№иө„дә§е®ҡд»·е’ҢйҮ‘иһҚеёӮеңәжіўеҠЁзҡ„еҪұе“ҚгҖӮж–ҮеҢ–еӣ зҙ еҜ№з»ҸжөҺгҖҒйҮ‘иһҚзҡ„еҪұе“ҚпјҢеҰӮж–ҮеҢ–дјҰзҗҶеҜ№е…¬еҸёжІ»зҗҶе’Ңз»ҸжөҺеўһй•ҝзҡ„еҪұе“ҚпјҢиҝҷдәӣж–№йқўзҡ„з ”з©¶д№ҹеҫҲеӨҡгҖӮеҸҲеҰӮдјҠж–Ҝе…°йҮ‘иһҚпјҲIslamic FinanceпјүпјҢж №жҚ®дјҠж–Ҝе…°ж•ҷд№үпјҢдјҠж–Ҝе…°йҮ‘иһҚеҖҹиҙ·дёҚд»ҳеҲ©жҒҜпјҢдҪҶеҖҹиҙ·иҖ…иӢҘжҠ•иө„жҲҗеҠҹпјҢеҲҷйңҖиҰҒеҲҶдә«еҲ©ж¶ҰгҖӮиҝҷз§ҚзӢ¬зү№зҡ„еҖҹиҙ·ж–ҮеҢ–еҰӮдҪ•еҪұе“Қиө„йҮ‘й…ҚзҪ®д»ҘеҸҠйҮ‘иһҚеёӮеңәиҝҗиЎҢпјҢеҖјеҫ—и®Өзңҹз ”з©¶гҖӮвҖңдёҖеёҰдёҖи·ҜвҖқеҖЎи®®жІҝзәҝеӣҪ家жңүдёҚе°‘жҳҜдјҠж–Ҝе…°еӣҪ家пјҢеҜ№дјҠж–Ҝе…°йҮ‘иһҚзҡ„з ”з©¶е°ҶжңүеҠ©дәҺжҲ‘们жӣҙеҘҪең°зҶҹжӮүиҝҷдәӣеӣҪ家зҡ„жҠ•иө„зҺҜеўғгҖӮиҝҳжңүйҮҸеҢ–з»ҸжөҺеҸІеӯҰпјҢжҳҜеҹәдәҺдёҖдәӣеҺҶеҸІж•°жҚ®зҡ„жһ„е»әпјҢиҝҗз”Ёи®ЎйҮҸз»ҸжөҺеӯҰж–№жі•з ”з©¶еҲ¶еәҰгҖҒж–ҮеҢ–еӣ зҙ еҜ№з»ҸжөҺзҡ„еӣ жһңеҪұе“ҚгҖӮеӨ§ж•°жҚ®зү№еҲ«жҳҜеҺҶеҸІж–Үжң¬ж•°жҚ®зҡ„ж•°еӯ—еҢ–пјҢи®©жһ„йҖ еҺҶеҸІеҸҳйҮҸеҸҳеҫ—жӣҙдёәж–№дҫҝдёҺе®№жҳ“гҖӮ
еӨ§ж•°жҚ®зҡ„еҮәзҺ°пјҢдҪҝз»ҸжөҺеӯҰеңЁдёҖдёӘжӣҙеӨ§зҡ„еҲҶжһҗжЎҶжһ¶дёӯиҝҗз”Ёе®ҡйҮҸзҡ„е®һиҜҒж–№жі•з ”з©¶з»ҸжөҺдёҺеҝғзҗҶжғ…ж„ҹгҖҒж”ҝжІ»жі•еҫӢгҖҒеҺҶеҸІж–ҮеҢ–гҖҒз”ҹжҖҒзҺҜеўғгҖҒеҚ«з”ҹеҒҘеә·зӯүеӣ зҙ д№Ӣй—ҙзҡ„зӣёдә’е…ізі»пјҢзү№еҲ«жҳҜжҺЁж–ӯе…¶еӣ жһңе…ізі»гҖӮдҫӢеҰӮпјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁеӨ§ж•°жҚ®зү№еҲ«жҳҜж–Үжң¬ж•°жҚ®пјҢжһ„е»әеҗ„з§ҚеҝғзҗҶеҸҳйҮҸпјҢеҰӮжҠ•иө„иҖ…жғ…ж„ҹжҢҮж•°гҖҒж¶Ҳиҙ№иҖ…е№ёзҰҸж„ҹжҢҮж•°гҖҒз»ҸжөҺж”ҝзӯ–дёҚзЎ®е®ҡжҖ§жҢҮж•°гҖҒз»ҸжөҺж”ҝзӯ–еҸҳеҢ–жҢҮж•°пјҢзӨҫдјҡиҲҶжғ…жҢҮж•°зӯүгҖӮиҝҷдәӣеҝғзҗҶеҸҳйҮҸжһ„йҖ еҮәжқҘд»ҘеҗҺпјҢе°ұеҸҜд»Ҙз”Ёж–Үжң¬еӣһеҪ’ж–№жі•пјҢе®ҡйҮҸз ”з©¶зӨҫдјҡзҫӨдҪ“зҡ„еҝғзҗҶжғ…ж„ҹзӯүеӣ зҙ дёҺз»ҸжөҺд№Ӣй—ҙзҡ„зӣёдә’е…ізі»гҖӮиҝҷз§Қж–°зҡ„дәәж–Үз»ҸжөҺеӯҰе®ҡйҮҸе®һиҜҒзҡ„з ”з©¶иҢғејҸпјҢиғҪеӨҹе°Ҷз»ҸжөҺеӯҰз ”з©¶зҪ®дәҺдёҖдёӘжӣҙе№ҝжіӣзҡ„зӨҫдјҡз»ҸжөҺеҲҶжһҗжЎҶжһ¶дёӯпјҢиҝҷжҳҜз»ҸжөҺеӯҰжңӘжқҘзҡ„дёҖдёӘж–°е…ҙз ”з©¶ж–№еҗ‘гҖӮ
д»ҘдёӢдёҫдҫӢиҜҙжҳҺеҰӮдҪ•дҪҝз”ЁеӨ§ж•°жҚ®зү№еҲ«жҳҜж–Үжң¬ж•°жҚ®жһ„е»әйҮҚиҰҒзҡ„еҝғзҗҶжғ…ж„ҹеҸҳйҮҸгҖӮжҲ‘们д»Ҙжһ„е»әжҠ•иө„иҖ…жғ…з»ӘжҢҮж•°дёәдҫӢгҖӮзӨҫдәӨеӘ’дҪ“е№іеҸ°пјҢеҰӮж–°жөӘеҫ®еҚҡгҖҒи…ҫи®Ҝ QQгҖҒжҺЁзү№пјҲTwitterпјүгҖҒи„ёд№ҰпјҲFacebookпјүзӯүпјҢжүҖдә§з”ҹзҡ„еӨ§ж•°жҚ®жҜ”д»»дҪ•з»ҹи®Ўи°ғжҹҘж•°жҚ®йғҪ
иҰҶзӣ–жӣҙеӨ§иҢғеӣҙзҡ„жҠ•иө„иҖ…пјҢеӣ жӯӨжӣҙе…·жңүд»ЈиЎЁжҖ§гҖӮзҺ°еңЁиҖғиҷ‘еҲ©з”ЁжҺЁзү№е№іеҸ°зҡ„жө·йҮҸеӨ§ж•°жҚ®жһ„е»әжҠ•иө„иҖ…жғ…з»ӘжҢҮж•°пјҢйҰ–е…ҲпјҢеҜ№зү№е®ҡжңҹй—ҙеҶ…зҡ„жҜҸдёҖжқЎжҺЁзү№иҝӣиЎҢвҖңеӯ—з¬ҰеҲҶжһҗвҖқпјҢеҲӨж–ӯжҺЁзү№дҝЎжҒҜжҳҜеҗҰдёҺйҮ‘иһҚеёӮеңәжіўеҠЁжҖ§пјҲеҰӮ CBOE VIXпјүжңүе…іпјҢеҰӮжһңжҳҜжңүе…іжіўеҠЁжҖ§зҡ„дҝЎжҒҜпјҢеҶҚ继з»ӯеҲӨж–ӯиҜҘжқЎжҺЁзү№дҝЎжҒҜеҸ‘еёғиҖ…зҡ„жғ…з»ӘпјҲд№җи§ӮгҖҒжӮІи§ӮгҖҒжҝҖеҠЁгҖҒе№іе’ҢзӯүпјүпјҢиҝҷеҸҜд»Ҙз”ұдәәе·ҘжҷәиғҪиҮӘ然иҜӯиЁҖеӨ„зҗҶжҠҖжңҜжқҘе®ҢжҲҗгҖӮ然еҗҺпјҢж №жҚ®вҖңеӯ—з¬ҰеҲҶжһҗвҖқзҡ„з»“жһңеҜ№жҜҸдёҖжқЎжҺЁзү№дҝЎжҒҜиөӢеҖјпјҢ并еҠ жқғе№іеқҮгҖӮеҠ жқғе№іеқҮзҡ„жқғйҮҚжңүдёӨдёӘз»ҙеәҰпјҡдёҖжҳҜеҜ№жҺЁзү№дҝЎжҒҜеҸ‘еёғиҖ…зҡ„иҝҮеҺ»еҺҶеҸІиҝӣиЎҢж·ұеәҰеӯҰд№ пјҢеҲӨж–ӯе…¶еҪұе“ҚеҠӣиҝӣиҖҢиөӢдәҲзӣёеә”зҡ„жқғйҮҚпјҢеҰӮзү№жң—жҷ®жҖ»з»ҹгҖҒиө„ж·ұиӮЎиҜ„家жқғйҮҚиөӢеҖјй«ҳпјҢжҷ®йҖҡжҠ•иө„иҖ…жқғйҮҚиөӢеҖјдҪҺпјӣдәҢжҳҜеңЁжҠҪж ·жңҹй—ҙиҫғй•ҝзҡ„жғ…еҶөдёӢпјҢдёҚеҗҢж—¶ж®өеә”иөӢдәҲдёҚеҗҢзҡ„жқғйҮҚгҖӮBaker andWurglerпјҲ2007пјүеҹәдәҺ 1966-2005 е№ҙзҡ„еҺҶеҸІж•°жҚ®пјҲдёҘж јең°иҜҙпјҢиҝҷдәӣж•°жҚ®дёҚжҳҜеӨ§ж•°жҚ®пјүпјҢйҖүеҸ– 6 дёӘжҢҮж Үжһ„е»әжҠ•иө„иҖ…жғ…ж„ҹжҢҮж•°пјҢ他们еҸ‘зҺ°жҠ•жңәйңҖжұӮпјҲspeculativedemandпјүдёҺжҠ•иө„иҖ…жғ…ж„ҹе‘ҲзҺ°еҫҲејәзҡ„зӣёе…іжҖ§гҖӮ
жҲ‘们зҺ°еңЁз»ҸеёёиҜҙдё–з•ҢдёҚзЎ®е®ҡжҖ§еӣ зҙ еңЁеўһеҠ пјҢеҰӮиҝҮеҺ»еҮ е№ҙзҡ„дёӯзҫҺиҙёжҳ“ж‘©ж“ҰеҜјиҮҙдёӯеӣҪз»ҸжөҺдёҺдё–з•Ңз»ҸжөҺдёҚзЎ®е®ҡжҖ§жҳҺжҳҫеўһеҠ гҖӮдә§з”ҹз»ҸжөҺдёҚзЎ®е®ҡжҖ§зҡ„еӣ зҙ еҫҲеӨҡпјҢе…¶дёӯж”ҝеәңж”ҝзӯ–зҡ„ж”№еҸҳжҳҜеј•иө·дёҚзЎ®е®ҡжҖ§еўһеҠ зҡ„дёҖдёӘйҮҚиҰҒеҺҹеӣ гҖӮйӮЈд№ҲпјҢеҰӮдҪ•жөӢеәҰж”ҝзӯ–дёҚзЎ®е®ҡжҖ§еҸҠе…¶еҪұе“ҚпјҹеңЁз»ҸжөҺеӯҰе®һиҜҒз ”з©¶дёӯпјҢз»ҸжөҺж”ҝзӯ–дёҚзЎ®е®ҡжҖ§жңҖеёёз”Ёзҡ„жөӢеәҰжҳҜеҹәдәҺжҠҘзәёзҡ„ж–Үжң¬ж•°жҚ®гҖӮBaker et al.пјҲ2016пјүеҹәдәҺзҫҺеӣҪеҚҒеӨ§дё»жөҒжҠҘзәёеңЁдёҖдёӘжңҲеҶ…дёҺз»ҸжөҺдёҚзЎ®е®ҡжҖ§зӣёе…ізҡ„иҜҚжұҮеҮәзҺ°зҡ„йў‘зҺҮпјҢжһ„е»әдәҶдёҖдёӘз»ҸжөҺж”ҝзӯ–дёҚзЎ®е®ҡжҖ§жңҲеәҰжҢҮж•°гҖӮйҷӨжҠҘзәёж–Үжң¬ж•°жҚ®еӨ–пјҢиҝҷдёӘз»ҸжөҺж”ҝзӯ–дёҚзЎ®е®ҡжҢҮж•°иҝҳеҢ…жӢ¬дёүдёӘжҢҮж ҮпјҡзЁҺжі•жі•жқЎеӨұж•ҲжҢҮж•°пјҢйҖҡиҝҮз»ҹи®ЎжҜҸе№ҙеӨұж•Ҳзҡ„зЁҺжі•жі•жқЎж•°зӣ®жқҘиЎЎйҮҸзЁҺжі•еҸҳеҠЁзҡ„дёҚзЎ®е®ҡжҖ§пјӣз»ҸжөҺйў„жөӢе·®еҖјжҢҮж•°пјҢйҖҡиҝҮиҖғеҜҹдёҚеҗҢйў„жөӢжңәжһ„еҜ№йҮҚиҰҒз»ҸжөҺжҢҮж ҮпјҲеҢ…жӢ¬ж¶Ҳиҙ№иҖ…д»·ж јжҢҮж•°пјҢCPIпјүзҡ„йў„жөӢе·®еҖјжқҘиЎЎйҮҸз»ҸжөҺж”ҝзӯ–зҡ„дёҚзЎ®е®ҡжҖ§пјӣд»ҘеҸҠиҒ”йӮҰ / ең°ж–№е·һж”ҝеәңж”ҜеҮәйў„жөӢе·®еҖјгҖӮеӣӣйЎ№жҢҮж Үзҡ„жқғйҮҚеҲҶеҲ«дёә 1/2гҖҒ1/6гҖҒ1/6 е’Ң 1/6гҖӮе…ідәҺжқғйҮҚзҡ„зЎ®е®ҡжІЎжңүе”ҜдёҖзҡ„ж ҮеҮҶпјҢиҝҷж–№йқўжңүеҫҲеӨ§зҡ„з ”з©¶з©әй—ҙпјҢиҝҷеұһдәҺз»ҸжөҺз»ҹи®ЎеӯҰзҡ„иҢғз•ҙгҖӮз»ҸжөҺж”ҝзӯ–дёҚзЎ®е®ҡжҖ§жҢҮж•°еҸҜи§Ҷдёәж–°й—»и®°иҖ…иҝҷдёӘзҫӨдҪ“еҜ№з»ҸжөҺж”ҝзӯ–дёҚзЎ®е®ҡзҡ„еҝғзҗҶж„ҹеҸ—дёҺеҝғзҗҶеҸҚжҳ пјҢжң¬иҙЁдёҠжҳҜдёҖдёӘзү№е®ҡзӨҫдјҡзҫӨдҪ“зҡ„еҝғзҗҶжҢҮж•°гҖӮ
д»Һ Baker et al.пјҲ2016пјүзҡ„е®һиҜҒз ”з©¶еҸҜд»ҘзңӢеҮәпјҢдёҚзЎ®е®ҡжҖ§жҢҮж•°дёҺзҫҺеӣҪе’Ңдё–з•ҢйҮҚиҰҒж”ҝжІ»з»ҸжөҺдәӢ件еӯҳеңЁеҫҲејәзҡ„зӣёе…іжҖ§гҖӮ他们зҡ„з ”з©¶иҝҳиЎЁжҳҺпјҢж”ҝзӯ–дёҚзЎ®е®ҡжҖ§жҢҮж•°дёҺдёҖдәӣе®Ҹи§Ӯз»ҸжөҺеҸҳйҮҸпјҢеҰӮз»ҸжөҺеўһй•ҝжңүжҳҫи‘—зҡ„еҸҚеҗ‘е…ізі»пјҢдёҺеӨұдёҡзҺҮе‘ҲзҺ°жӯЈеҗ‘е…ізі»пјҢд№ҹе°ұжҳҜиҜҙпјҢдёҚзЎ®е®ҡжҖ§жҢҮж•°и¶Ҡй«ҳпјҢз»ҸжөҺеўһй•ҝи¶Ҡж…ўпјҢеӨұдёҡзҺҮд№ҹи¶Ҡй«ҳгҖӮеҪ“然пјҢиҝҷдәӣзӣёе…іе…ізі»жҳҜдёҚжҳҜеӣ жһңе…ізі»пјҢйңҖиҰҒиҝӣдёҖжӯҘеҲҶжһҗгҖӮChan and ZhongпјҲ2019пјүеҹәдәҺгҖҠдәәж°‘ж—ҘжҠҘгҖӢ1946 е№ҙеҲӣеҲҠд»ҘжқҘзҡ„жүҖжңүдёӯж–Үж–Үжң¬ж•°жҚ®пјҲзәҰ 100 еӨҡдёҮзҜҮдёӯж–Үж–Үз« пјҢе…ұи®Ў 20 дәҝжұүеӯ—пјүпјҢйҮҮз”Ёдәәе·ҘзҘһз»ҸзҪ‘з»ңж·ұеәҰеӯҰд№ ж–№жі•йў„жөӢдёӯеӣҪз»ҸжөҺж”ҝзӯ–еҸҳеҢ–пјҢ并жҚ®жӯӨжһ„е»әдәҶдёҖдёӘдёӯеӣҪз»ҸжөҺж”ҝзӯ–еҸҳеҢ–жҢҮж•°пјҲEconomic Policy Change IndexпјүгҖӮ他们еҸ‘зҺ°пјҢжүҖжһ„йҖ зҡ„дёӯеӣҪж”ҝзӯ–еҸҳеҢ–жҢҮж•°дёҺж–°дёӯеӣҪжҲҗз«ӢеҗҺеҸ‘з”ҹзҡ„йҮҚеӨ§ж”ҝжІ»з»ҸжөҺдәӢ件еҹәжң¬еҗ»еҗҲгҖӮ
еӨ§ж•°жҚ®йқ©е‘ҪеӮ¬з”ҹдәҶзҺ°д»ЈзӨҫдјҡ科еӯҰдёҖдёӘж–°зҡ„еӯҰ科пјҢеҸ«еҒҡи®Ўз®—зӨҫдјҡ科еӯҰпјҲComputational Social ScienceпјүпјҢжһҒеӨ§ең°ж”№еҸҳдәҶдәәж–ҮзӨҫдјҡ科еӯҰзҡ„з ”з©¶иҢғејҸпјҢзү№еҲ«жҳҜд»Һе®ҡжҖ§еҲҶжһҗеҲ°е®ҡйҮҸе®һиҜҒеҲҶжһҗпјҲиғЎе®үе®ҒзӯүпјҢ2021пјүгҖӮдҪҝз”ЁеӨ§ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ з ”з©¶дәәж–ҮзӨҫдјҡ科еӯҰзҡ„е®ҡйҮҸе®һиҜҒз ”з©¶ж—ҘзӣҠеўһеҠ пјҢеӣ жӯӨпјҢеә”иҜҘйҖӮж—¶жҺЁеҠЁз»ҸжөҺеӯҰе’Ңдәәж–ҮзӨҫдјҡ科еӯҰе…¶д»–йўҶеҹҹд№Ӣй—ҙзҡ„дәӨеҸүиһҚеҗҲе’Ңи·ЁеӯҰз§‘з ”з©¶гҖӮ
е…ӯгҖҒеӨ§ж•°жҚ®гҖҒжңәеҷЁеӯҰд№ е’Ңз»ҸжөҺеӯҰе®һиҜҒз ”з©¶ж–№жі•еҲӣж–°
дёҠж–Үйҳҗиҝ°дәҶеңЁеӨ§ж•°жҚ®ж—¶д»ЈпјҢеӨ§ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ еҜ№з»ҸжөҺеӯҰз ”з©¶иҢғејҸзҡ„ж·ұеҲ»еҪұе“ҚпјҢзү№еҲ«жҳҜж–Үжң¬ж•°жҚ®зҡ„еҸҜиҺ·еҫ—жҖ§пјҢдҪҝз»ҸжөҺеӯҰиғҪеӨҹеңЁдёҖдёӘжӣҙеӨ§зҡ„з»ҹдёҖеҲҶжһҗжЎҶжһ¶дёӯпјҢзі»з»ҹең°з ”究з»ҸжөҺдёҺеҝғзҗҶгҖҒеҺҶеҸІгҖҒж–ҮеҢ–гҖҒзӨҫдјҡгҖҒж”ҝжІ»гҖҒжі•еҫӢгҖҒз”ҹжҖҒгҖҒеҒҘеә·зӯүдәәж–ҮзӨҫдјҡеӣ зҙ д№Ӣй—ҙзҡ„зӣёдә’еҪұе“ҚпјҢд»ҺиҖҢдҝғиҝӣз»ҸжөҺеӯҰдёҺдәәж–ҮзӨҫдјҡ科еӯҰе…¶д»–еӯҰ科д№Ӣй—ҙзҡ„дәӨеҸүиһҚеҗҲе’Ңи·ЁеӯҰз§‘з ”з©¶гҖӮеңЁиҝҷдёҖйғЁеҲҶдёӯпјҢжҲ‘们дёҫдҫӢи®әиҝ°еӨ§ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ еҜ№з»ҸжөҺеӯҰзҡ„е®һиҜҒз ”з©¶ж–№жі•зҡ„еҪұе“ҚгҖӮеңЁе®һиҜҒйқ©е‘Ҫж—¶д»ЈпјҢи®ЎйҮҸз»ҸжөҺеӯҰдҪңдёәз»ҸжөҺеӯҰе®һиҜҒз ”з©¶жңҖйҮҚиҰҒзҡ„ж–№жі•и®әпјҢеңЁжҺЁеҠЁз»ҸжөҺеӯҰз ”з©¶ж–№йқўеҸ‘жҢҘдәҶиҮіе…ійҮҚиҰҒзҡ„дҪңз”ЁпјҲжҙӘж°ёж·јпјҢ2007пјүгҖӮз»ҸжөҺи§ӮжөӢж•°жҚ®йқһе®һйӘҢжҖ§зҡ„зү№еҫҒпјҢдҪҝи®ЎйҮҸз»ҸжөҺеӯҰж–№жі•зҡ„йҮҚиҰҒжҖ§жӣҙеҠ еҮёжҳҫпјҢиҖҢеӨ§ж•°жҚ®зӣёеҜ№дәҺдј з»ҹж•°жҚ®зҡ„ж–°зү№зӮ№пјҢе®ўи§ӮдёҠиҰҒжұӮеҜ№и®ЎйҮҸз»ҸжөҺеӯҰж–№жі•дёҺе·Ҙе…·иҝӣиЎҢеҲӣж–°е’ҢеҸ‘еұ•гҖӮеӨ§ж•°жҚ®йҷӨдәҶйқһз»“жһ„еҢ–ж•°жҚ®д№ӢеӨ–пјҢиҝҳжңүеӨ§йҮҸзҡ„з»“жһ„еҢ–ж•°жҚ®пјҢеҢ…жӢ¬й«ҳйў‘з”ҡиҮіе®һж—¶з»“жһ„еҢ–ж•°жҚ®пјҢеҰӮйҮ‘иһҚеёӮеңәдёҠжҜҸ笔дәӨжҳ“ж•°жҚ®пјҲtick-by-tick dataпјүгҖӮеңЁз»“жһ„еҢ–ж•°жҚ®дёӯпјҢеҮәзҺ°дәҶдёҚе°‘ж–°еһӢж•°жҚ®пјҢеҰӮеҮҪж•°ж•°жҚ®гҖҒеҢәй—ҙж•°жҚ®е’Ңз¬ҰеҸ·ж•°жҚ®зӯүгҖӮиҝҷдәӣж–°еһӢж•°жҚ®жҜ”зӮ№ж•°жҚ®еҢ…еҗ«жӣҙдё°еҜҢзҡ„дҝЎжҒҜпјҢ并且呼е”Өж–°зҡ„и®ЎйҮҸз»ҸжөҺеӯҰжЁЎеһӢпјҢи®ЎйҮҸз»ҸжөҺеӯҰзҗҶи®әдёҺж–№жі•д№ҹеӣ жӯӨеңЁеӨ§ж•°жҚ®ж—¶д»ЈжңүеҸ–еҫ—еҺҹеҲӣжҖ§зӘҒз ҙзҡ„еҸҜиғҪжҖ§гҖӮдәӢе®һдёҠпјҢиҝҮеҺ» 20 е№ҙпјҢд»…д»…з”ұдәҺз»ҸжөҺйҮ‘иһҚж•°жҚ®зҡ„е®һж—¶жҲ–й«ҳйў‘еҢ–е°ұе·Із»Ҹдә§з”ҹдәҶеҫҲеӨҡж–°зҡ„и®ЎйҮҸз»ҸжөҺеӯҰжЁЎеһӢдёҺж–№жі•гҖӮдҫӢеҰӮпјҢEngle and RussellпјҲ1998пјүе’ҢEngleпјҲ2000пјүеҹәдәҺжҜҸ笔дәӨжҳ“ж•°жҚ®жҸҗеҮәдәҶдёҖдёӘзұ»дјјдәҺ GARCH жіўеҠЁжЁЎеһӢзҡ„ж–°жЁЎеһӢвҖ”вҖ”иҮӘеӣһеҪ’жқЎд»¶д№…жңҹпјҲAutoregressive Conditional DurationпјҢACDпјүжЁЎеһӢпјҢеҜ№йҮ‘иһҚдәӢ件зҡ„жҢҒз»ӯж—¶й—ҙй•ҝзҹӯпјҢеҰӮдёӨ笔дәӨжҳ“жҲ–дёӨдёӘд»·ж јеҸҳеҠЁзҡ„ж—¶й—ҙй—ҙйҡ”пјҢиҝӣиЎҢе»әжЁЎпјҢиҝҷдёӘжЁЎеһӢеҸҜд»ҘеҲ©з”ЁеҺҶеҸІж•°жҚ®йў„жөӢйҮ‘иһҚдәӢ件пјҲеҰӮд»·ж јеҸҳеҠЁпјүеҸ‘з”ҹзҡ„ж—¶й—ҙпјҢеҜ№зҗҶи§ЈйҮ‘иһҚеёӮеңәеҫ®и§Ӯз»“жһ„е’ҢиЎҚз”ҹдә§е“Ғе®ҡд»·еҫҲжңүеё®еҠ©гҖӮеҗҢж ·пјҢжңүдәҶж—ҘеҶ…й«ҳйў‘ж•°жҚ®пјҲintraday dataпјүпјҢе°ұеҸҜд»Ҙи®Ўз®—жүҖи°“зҡ„е®һзҺ°жіўеҠЁзҺҮпјҲrealized volatilityпјүпјҢд»Ҙдј°и®Ўж—ҘжіўеҠЁзҺҮпјҲdaily volatilityпјүгҖӮе®һзҺ°жіўеҠЁзҺҮзҡ„е…¬ејҸдёә
 е…¶дёӯпјҢi жҢҮжҹҗдёҖеӨ©жҜҸеҮ еҲҶй’ҹпјҲеҰӮ 5 еҲҶй’ҹеҶ…пјүзҡ„йҮ‘иһҚиө„дә§д»·ж јеҸҳеҠЁгҖӮе°ҶиҝҷдёҖеӨ©ж—ҘеҶ…д»·ж јеҸҳеҠЁзҡ„е№іж–№еҠ жҖ»иө·жқҘпјҢж №жҚ®еӨ§ж•°е®ҡеҫӢпјҢе°ұеҸҜд»ҘдёҖиҮҙдј°и®ЎеҪ“еӨ©зҡ„жіўеҠЁзҺҮгҖӮиҝҷдёӘж–№жі•е…¶е®һйқһеёёеҸӨиҖҒпјҢд»ҘеүҚдј°и®ЎжҹҗдёҖдёӘйҮ‘иһҚеҸҳйҮҸзҡ„е№ҙжіўеҠЁзҺҮпјҢе°ұжҳҜжҠҠжҜҸеӨ©зҡ„д»·ж јеҸҳеҠЁе№іж–№еҠ иө·жқҘгҖӮзҺ°еңЁжңүдәҶж—ҘеҶ…й«ҳйў‘ж•°жҚ®пјҢе°ұеҸҜд»ҘдёҖиҮҙдј°и®Ўж—ҘжіўеҠЁзҺҮгҖӮеҪ“然пјҢиҝҷйҮҢйңҖиҰҒиҖғиҷ‘еёӮеңәеҫ®и§Ӯз»“жһ„еҷӘеЈ°пјҲmarket microstructure noisesпјүеҜ№ж—ҘжіўеҠЁзҺҮдј°и®Ўзҡ„еҪұе“ҚпјҲAit-Sahalia and YuпјҢ2009пјүпјҢиҝҷжҳҜд»ҘеүҚдҪҺйў‘йҮ‘иһҚж•°жҚ®жүҖжІЎжңүйҒҮеҲ°зҡ„й—®йўҳгҖӮ
е…¶дёӯпјҢi жҢҮжҹҗдёҖеӨ©жҜҸеҮ еҲҶй’ҹпјҲеҰӮ 5 еҲҶй’ҹеҶ…пјүзҡ„йҮ‘иһҚиө„дә§д»·ж јеҸҳеҠЁгҖӮе°ҶиҝҷдёҖеӨ©ж—ҘеҶ…д»·ж јеҸҳеҠЁзҡ„е№іж–№еҠ жҖ»иө·жқҘпјҢж №жҚ®еӨ§ж•°е®ҡеҫӢпјҢе°ұеҸҜд»ҘдёҖиҮҙдј°и®ЎеҪ“еӨ©зҡ„жіўеҠЁзҺҮгҖӮиҝҷдёӘж–№жі•е…¶е®һйқһеёёеҸӨиҖҒпјҢд»ҘеүҚдј°и®ЎжҹҗдёҖдёӘйҮ‘иһҚеҸҳйҮҸзҡ„е№ҙжіўеҠЁзҺҮпјҢе°ұжҳҜжҠҠжҜҸеӨ©зҡ„д»·ж јеҸҳеҠЁе№іж–№еҠ иө·жқҘгҖӮзҺ°еңЁжңүдәҶж—ҘеҶ…й«ҳйў‘ж•°жҚ®пјҢе°ұеҸҜд»ҘдёҖиҮҙдј°и®Ўж—ҘжіўеҠЁзҺҮгҖӮеҪ“然пјҢиҝҷйҮҢйңҖиҰҒиҖғиҷ‘еёӮеңәеҫ®и§Ӯз»“жһ„еҷӘеЈ°пјҲmarket microstructure noisesпјүеҜ№ж—ҘжіўеҠЁзҺҮдј°и®Ўзҡ„еҪұе“ҚпјҲAit-Sahalia and YuпјҢ2009пјүпјҢиҝҷжҳҜд»ҘеүҚдҪҺйў‘йҮ‘иһҚж•°жҚ®жүҖжІЎжңүйҒҮеҲ°зҡ„й—®йўҳгҖӮ
еңЁе®Ҹи§Ӯз»ҸжөҺеӯҰз ”з©¶дёӯпјҢеӨ§еӨҡж•°е®Ҹи§Ӯз»ҸжөҺеҸҳйҮҸзҡ„жңҖй«ҳйў‘ж•°жҚ®жҳҜжңҲеәҰж•°жҚ®пјҢеҰӮж¶Ҳиҙ№иҖ…д»·ж јжҢҮж•°пјҲConsumer Price IndexпјҢCPIпјүгҖҒз”ҹдә§иҖ…д»·ж јжҢҮж•°пјҲProducerPrice IndexпјҢPPIпјүзӯүгҖӮGDP жІЎжңүжңҲеәҰж•°жҚ®пјҢеӣ жӯӨеёёз”Ёе·Ҙдёҡз”ҹдә§жҢҮж•°пјҲIndustrialProduction IndexпјүжқҘд»ЈиЎЁгҖӮеңЁеӨ§ж•°жҚ®ж—¶д»ЈпјҢеҸҜд»Ҙжһ„йҖ жӣҙй«ҳйў‘зҡ„е®Ҹи§Ӯз»ҸжөҺеҸҳйҮҸж•°жҚ®пјҢеҰӮжҜҸе‘Ёз”ҡиҮіжҜҸеӨ©зҡ„ CPIгҖҒPPI зӯүпјҢйў„и®Ўй«ҳйў‘е®һиҜҒе®Ҹи§Ӯз»ҸжөҺеӯҰиҝҷж ·зҡ„ж–°еӯҰ科е°ҶдјҡиҜһз”ҹпјҢиҝҷе°ҶдҪҝжҲ‘们иғҪеӨҹжӣҙеҠ зІҫзЎ®ең°з ”究е®Ҹи§Ӯз»ҸжөҺеҸҳйҮҸд№Ӣй—ҙзҡ„ж•°йҮҸе…ізі»пјҢжӣҙеҠ еҸҠж—¶жҠҠжҸЎе®Ҹи§Ӯз»ҸжөҺеҸҳеҠЁи¶ӢеҠҝгҖӮдҫӢеҰӮпјҢж је…°жқ°еӣ жһңе…ізі»пјҲGrangerпјҢ1969пјүжҳҜжҢҮдёӨдёӘж—¶й—ҙеәҸеҲ—еҸҳйҮҸеңЁж—¶й—ҙз»ҙеәҰдёҠзҡ„зӣёдә’е…ізі»жҲ–йў„жөӢе…ізі»пјҢеҚідёҖдёӘж—¶й—ҙеәҸеҲ—еҸҳйҮҸзҡ„еҺҶеҸІдҝЎжҒҜжҳҜеҗҰеҜ№еҸҰдёҖдёӘж—¶й—ҙеәҸеҲ—еҸҳйҮҸе…·жңүйў„жөӢиғҪеҠӣгҖӮз”ұдәҺе®Ҹи§Ӯз»ҸжөҺеҸҳйҮҸеӨ§еӨҡйҖҡиҝҮеҠ жҖ»пјҲaggregationпјүжһ„е»әиҖҢжҲҗпјҢеҜјиҮҙж је…°жқ°еӣ жһңе…ізі»дёҺжҠҪж ·ж—¶й—ҙй—ҙйҡ”й•ҝеәҰжңүе…ігҖӮжҜ”еҰӮпјҢдёӨдёӘж—¶й—ҙеәҸеҲ—еҸҳйҮҸпјҲеҰӮеӨұдёҡзҺҮе’ҢйҖҡиҙ§иҶЁиғҖзҺҮпјүеҸҜиғҪеңЁй«ҳйў‘ж—¶й—ҙй—ҙйҡ”еӯҳеңЁж је…°жқ°еӣ жһңе…ізі»пјҢдҪҶеңЁдҪҺйў‘ж—¶й—ҙй—ҙйҡ”з”ұдәҺеҸҳйҮҸеңЁж—¶й—ҙз»ҙеәҰдёҠзҡ„еҠ жҖ»пјҲtemporal aggregationпјүиҖҢеҸҜиғҪеҸӘеү©дёӢеҚіж—¶зӣёе…іжҖ§гҖӮжӯӨеӨ–пјҢй«ҳйў‘ж—¶й—ҙеәҸеҲ—еҸҳйҮҸеҸҜиғҪеӯҳеңЁйқһзәҝжҖ§е…ізі»пјҢдҪҶеңЁдҪҺйў‘ж—¶еҸҜиғҪдјҡеҸҳжҲҗзәҝжҖ§е…ізі»пјӣй«ҳйў‘ж—¶й—ҙеәҸеҲ—еҸҳйҮҸд»ҘеҸҠеҸҳйҮҸд№Ӣй—ҙзҡ„е…ізі»еҸҜиғҪеӯҳеңЁз»“жһ„зӘҒеҸҳпјҢдҪҶеңЁдҪҺйў‘ж—¶еҸҜиғҪдјҡе‘ҲзҺ°зј“ж…ўз»“жһ„еҸҳеҢ–гҖӮеҸҰдёҖж–№йқўпјҢй•ҝжңҹд»ҘжқҘпјҢз”ұдәҺйҮ‘иһҚеёӮеңәзһ¬жҒҜдёҮеҸҳпјҢеҹәдәҺдҪҺйў‘е®Ҹи§Ӯз»ҸжөҺж•°жҚ®з ”究е®Ҹи§Ӯз»ҸжөҺдёҺйҮ‘иһҚеёӮеңәд№Ӣй—ҙзҡ„дә’еҠЁпјҢдёҖзӣҙеӯҳеңЁеҫҲеӨҡеӣ°йҡҫгҖӮзҺ°еңЁпјҢе®Ҹи§Ӯз»ҸжөҺж—¶й—ҙеәҸеҲ—ж•°жҚ®зҡ„й«ҳйў‘еҢ–пјҢе°ҶдҪҝз ”з©¶е®Ҹи§Ӯе®һдҪ“з»ҸжөҺе’ҢйҮ‘иһҚеёӮеңәд№Ӣй—ҙеңЁиҫғй«ҳйў‘зҺҮдёҠзҡ„зӣёдә’еҪұе“ҚжҲҗдёәеҸҜиғҪгҖӮжҖ»д№ӢпјҢй«ҳйў‘е®Ҹи§ӮеӨ§ж•°жҚ®е°Ҷдёәз ”з©¶е®Ҹи§Ӯз»ҸжөҺеҸҳйҮҸзҡ„еҠЁжҖҒзү№еҫҒдёҺжҖ§иҙЁжҸҗдҫӣж–°зҡ„жҙһи§ҒгҖӮ
д»ҘдёӢпјҢжҲ‘们йҖҡиҝҮеҮ дёӘе…·дҪ“жЎҲдҫӢпјҢиҜҰз»ҶиҜҙжҳҺеӨ§ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ еҰӮдҪ•еҪұе“Қз»ҸжөҺеӯҰе®һиҜҒз ”з©¶зҡ„ж–№жі•еҲӣж–°гҖӮ
пјҲдёҖпјүеҢәй—ҙж•°жҚ®е»әжЁЎдёҺе®Ҹи§Ӯз»ҸжөҺеҢәй—ҙз®ЎзҗҶ
ж–°еһӢеӨ§ж•°жҚ®еҢ…жӢ¬йҮ‘иһҚеӯҰзҡ„ж—ҘеҶ…ж•°жҚ®гҖҒжҜҸ笔дәӨжҳ“ж•°жҚ®гҖҒеҮҪж•°ж•°жҚ®гҖҒеҢәй—ҙж•°жҚ®д»ҘеҸҠз¬ҰеҸ·ж•°жҚ®зӯүгҖӮдҪ•и°“еҢәй—ҙж•°жҚ®пјҹжҜ”еҰӮпјҢгҖҠзәҪзәҰж—¶жҠҘгҖӢе’ҢгҖҠеҚҺе°”иЎ—ж—ҘжҠҘгҖӢжҜҸеӨ©йғҪдјҡжҠҘйҒ“иӮЎзҘЁеёӮеңәејҖзӣҳд»·гҖҒ收зӣҳд»·гҖҒжңҖй«ҳд»·гҖҒжңҖдҪҺд»·зӯүдҝЎжҒҜпјҢз”ұжңҖй«ҳд»·гҖҒжңҖдҪҺд»·жүҖжһ„жҲҗзҡ„ж•°жҚ®йӣҶеҗҲе°ұжҳҜдёҖдёӘеҢәй—ҙж•°жҚ®гҖӮйҷӨдәҶиӮЎзҘЁд»·ж јж•°жҚ®еӨ–пјҢйҮ‘иһҚеёӮеңәдёҠзҡ„д№°еҚ–д»·е·®пјҲbid-ask spreadпјүпјҢе•Ҷдёҡ银иЎҢзҡ„еӯҳиҙ·ж¬ҫеҲ©зҺҮгҖҒеҢ»еӯҰзҡ„й«ҳдҪҺиЎҖеҺӢеҺӢе·®гҖҒеӨ©ж°”й«ҳдҪҺж°”жё©гҖҒеҠіеҠЁз»ҸжөҺеӯҰзҡ„з”·еҘіж”¶е…Ҙе·®и·қзӯүйғҪжһ„жҲҗеҢәй—ҙж•°жҚ®гҖӮзӣ®еүҚи®ЎйҮҸз»ҸжөҺеӯҰе»әжЁЎеҮ д№ҺйғҪжҳҜеҹәдәҺзӮ№ж•°жҚ®пјҢеҰӮеә”з”Ё GARCH жЁЎеһӢеҜ№иӮЎзҘЁеёӮеңәжіўеҠЁзҺҮзҡ„е»әжЁЎпјҢеӨ§йғҪд»ҘжҜҸж—Ҙ收зӣҳд»·ж•°жҚ®дёәеҹәзЎҖгҖӮжҳҫ然пјҢжҜҸж—Ҙ收зӣҳ价并дёҚиғҪеҸҚжҳ еҪ“ж—Ҙд»·ж јжіўеҠЁзҡ„дҝЎжҒҜпјҢдҪҶеҰӮжһңдҪҝз”Ёз”ұжҜҸж—ҘжңҖй«ҳд»·е’ҢжңҖдҪҺд»·жһ„жҲҗзҡ„ж—ҘеҢәй—ҙж•°жҚ®пјҢйӮЈд№ҲиҝҷдёӘеҢәй—ҙж•°жҚ®жҜ”жҜҸж—Ҙ收зӣҳд»·еҢ…еҗ«жӣҙеӨҡзҡ„дҝЎжҒҜпјҢдёҚ仅收зӣҳд»·иҗҪе…ҘеҢәй—ҙеҶ…пјҢиҖҢдё”еҢәй—ҙж•°жҚ®иҝҳеҢ…еҗ«д»·ж јж°ҙе№іпјҲд»·ж јдёӯзӮ№пјүе’Ңд»·ж јжіўеҠЁиҢғеӣҙзҡ„дҝЎжҒҜгҖӮй•ҝжңҹд»ҘжқҘпјҢеҢәй—ҙж•°жҚ®жүҖеҢ…еҗ«зҡ„дҝЎжҒҜеңЁи®ЎйҮҸз»ҸжөҺеӯҰе»әжЁЎдёӯжІЎжңүеҫ—еҲ°жңүж•ҲеҲ©з”ЁгҖӮ
зҺ°жңүи®ЎйҮҸз»ҸжөҺеӯҰзҗҶи®әдёҺж–№жі•дёҚиғҪзӣҙжҺҘз”ЁдәҺеҲҶжһҗеҢәй—ҙж•°жҚ®гҖӮеҜ№еҢәй—ҙж•°жҚ®е»әжЁЎпјҢйңҖиҰҒдёҖеҘ—йҖӮеҗҲеҢәй—ҙж•°жҚ®зҡ„жҰӮзҺҮи®әдёҺж•°еӯҰж–№жі•пјҢзү№еҲ«жҳҜйҡҸжңәйӣҶжҰӮзҺҮи®әпјҲProbability Theory of Random SetsпјүеҸҠе…¶еә”з”ЁгҖӮдёҖз»ҙйҡҸжңәйӣҶе°ұжҳҜеҢәй—ҙйҡҸжңәеҸҳйҮҸпјҢиҖҢдәҢз»ҙйҡҸжңәйӣҶе°ұжҳҜйҡҸжңәе№ійқўеҢәеҹҹгҖӮеҜ№дёҖз»ҙйҡҸжңәйӣҶпјҢеҚіеҢәй—ҙж•°жҚ®зҡ„е№ізЁіжҖ§гҖҒзӣёе…іжҖ§гҖҒи·қзҰ»зӯүеҹәжң¬жҰӮеҝөпјҢд»ҘеҸҠеҠ еҮҸд№ҳйҷӨзӯүиҝҗз®—жі•еҲҷйғҪиҰҒйҮҚж–°е®ҡд№үпјҢиҝҷзүөж¶үеҲ°еҫҲеӨҡж–°зҡ„ж•°еӯҰж–№жі•дёҺе·Ҙе…·пјҲHanпјҢet al., 2018; Sun et al., 2018пјүгҖӮ

еҢәй—ҙе»әжЁЎеҸҜеә”з”ЁдәҺе®Ҹи§Ӯз»ҸжөҺи°ғжҺ§гҖӮж—©еңЁ 2013 е№ҙдёӯеӣҪз»ҸжөҺиҝӣе…Ҙж–°еёёжҖҒж—¶пјҢдёӯеӣҪж”ҝеәңе°ұжҸҗеҮәе®Ҹи§Ӯз»ҸжөҺеҢәй—ҙи°ғжҺ§ж–°жҖқз»ҙгҖӮд»Җд№ҲеҸ«еҒҡе®Ҹи§Ӯз»ҸжөҺеҢәй—ҙи°ғжҺ§пјҹе°ұжҳҜйҒҝе…Қз»ҸжөҺеӨ§иө·еӨ§иҗҪпјҢдҪҝз»ҸжөҺиҝҗиЎҢйҖҹеәҰдҝқжҢҒеңЁеҗҲзҗҶеҢәй—ҙгҖӮе…¶вҖңдёӢйҷҗвҖқе°ұжҳҜзЁіеўһй•ҝгҖҒдҝқе°ұдёҡпјҢвҖңдёҠйҷҗвҖқе°ұжҳҜйҳІиҢғйҖҡиҙ§иҶЁиғҖгҖӮжңҖиҝ‘еҮ е№ҙпјҢеӣҪеҠЎйҷўгҖҠж”ҝеәңе·ҘдҪңжҠҘе‘ҠгҖӢе’Ңи¶ҠжқҘи¶ҠеӨҡзҡ„зңҒд»ҪгҖҠж”ҝеәңе·ҘдҪңжҠҘе‘ҠгҖӢпјҢи®ҫе®ҡзҡ„жҜҸе№ҙеўһй•ҝзӣ®ж ҮйғҪдёҚжҳҜдёҖдёӘзӮ№ж•°еӯ—пјҢиҖҢжҳҜдёҖдёӘеҢәй—ҙгҖӮзӣёеҜ№дәҺеҺҹжқҘзҡ„зӮ№еўһй•ҝзӣ®ж ҮпјҢеҢәй—ҙз®ЎзҗҶжҳҜдёӯеӣҪе®Ҹи§Ӯз»ҸжөҺи°ғжҺ§е®һи·өзҡ„дёҖдёӘеҲӣж–°пјҢе®ғж—ўиғҪеӨҹдҝқиҜҒжңҖдҪҺз»ҸжөҺеўһй•ҝйҖҹеәҰзҡ„иҰҒжұӮпјҢеҸҲз»ҷдәҲе®Ҹи§Ӯз»ҸжөҺи°ғжҺ§дёҖе®ҡзҡ„зҒөжҙ»еәҰпјҢйҒҝе…ҚеҺҹжқҘдёәдәҶиҫҫжҲҗзӮ№еўһй•ҝзӣ®ж ҮиҖҢйҮҮеҸ–зҡ„дёҖдәӣзҹӯжңҹиЎҢдёәпјҢжңүеҲ©дәҺдёӯй•ҝжңҹз»ҸжөҺе№ізЁіжҢҒз»ӯеҒҘеә·еҸ‘еұ•гҖӮ
еҢәй—ҙж•°жҚ®е»әжЁЎеҸҜд»ҘжӣҙеҘҪең°жөӢеәҰе’Ңйў„жөӢз»ҸжөҺйҮ‘иһҚзҡ„дёҚзЎ®е®ҡжҖ§гҖӮжҲ‘们д»Ҙ He et al.пјҲ2021пјүйў„жөӢеҺҹжІ№жңҹиҙ§д»·ж јдёәдҫӢгҖӮд»Ө Ft = [Lt,Ht ] иЎЁзӨәеҺҹжІ№жңҹиҙ§жңҲд»·ж јеҢәй—ҙпјҢе…¶дёҠдёӢз•ҢдёәжңҲеҶ…жҜҸж—ҘеҺҹжІ№жңҹиҙ§зҡ„жңҖдҪҺеҖј Lt е’ҢжңҖй«ҳеҖј HtпјҢе…¶дёӯLtе’Ң HtдёәеҜ№ж•°еһӢд»·ж јпјҢжңҲеәҰеҺҹжІ№д»·ж јеҸҳеҠЁиҢғеӣҙпјҲrangeпјүдёә Rt =Ht ? Lt пјҢжңҲеәҰеҺҹжІ№д»·ж јдёӯзӮ№пјҲmidpointпјүдёә Mt = пјҲ Lt + Ht пјү/ 2 гҖӮд»ҺеҺҹжІ№д»·ж јеҢәй—ҙж—¶й—ҙеәҸеҲ—ж•°жҚ®еҸҜд»ҘзңӢеҮәпјҢд»·ж јдёӯзӮ№зҡ„еҸҳеҢ–еӯҳеңЁиҙҹиҮӘзӣёе…іпјҢиҖҢд»·ж јиҢғеӣҙзҡ„еҸҳеҢ–еҲҷеӯҳеңЁжӯЈиҮӘзӣёе…ігҖӮ

дёәдәҶйў„жөӢеҺҹжІ№д»·ж јеҢәй—ҙпјҢHe et al.пјҲ2021пјүдҪҝз”Ёд»ҘдёӢиҮӘеӣһеҪ’еҢәй—ҙж—¶й—ҙеәҸеҲ—жЁЎеһӢпјҡ

е…¶ дёӯ

ECt жҳҜй•ҝжңҹеқҮиЎЎе…ізі»жһ„жҲҗзҡ„иҜҜе·®ж»һеҗҺйЎ№пјҢSPEt жҳҜеҢәй—ҙеһӢжҠ•жңәеӣ зҙ пјҢе…¶дёҠдёӢз•ҢжҳҜз”ұ NYMEX еёӮеңәзҹіжІ№жңҹиҙ§йқһе•ҶдёҡжҢҒд»“зҡ„еӨҡеӨҙеӨҙеҜёе‘ЁеәҰж•°жҚ®зҡ„жңҖеӨ§еҖје’ҢжңҖе°ҸеҖјжһ„жҲҗпјҢиҖҢ ut жҳҜдёҖдёӘеҢәй—ҙйҡҸжңәжү°еҠЁйЎ№пјҢе…¶еқҮеҖјдёәйӣ¶пјҲеқҮеҖјдёҠдёӢз•ҢеқҮдёәйӣ¶пјүгҖӮиҝҷдёӘжЁЎеһӢеҸҜи§Ҷдёәж—¶й—ҙеәҸеҲ—еҲҶжһҗдёӯ ARMAX жЁЎеһӢзҡ„еҢәй—ҙзүҲжң¬пјҢз”ұ Han et al.пјҲ2018пјүйҰ–е…ҲжҸҗеҮәгҖӮжЁЎеһӢдёӯжүҖжңүжңӘзҹҘеҸӮж•°еқҮдёәж ҮйҮҸгҖӮ
д»ҺеҢәй—ҙжЁЎеһӢеҸҜеҲҶеҲ«жҺЁеҮәеҺҹжІ№д»·ж јдёӯзӮ№жЁЎеһӢе’Ңд»·ж јиҢғеӣҙжЁЎеһӢпјҢиЎЁзӨәеҰӮдёӢпјҡ


иҝҷж ·пјҢеҹәдәҺеҺҹжІ№жңҹиҙ§д»·ж јеҢәй—ҙж•°жҚ®пјҢжҲ‘们еҸҜд»Ҙдј°и®ЎиҮӘеӣһеҪ’еҢәй—ҙжЁЎеһӢпјҲ1пјүзҡ„жүҖжңүжңӘзҹҘеҸӮж•°еҖјгҖӮжңүдәҶиҝҷдәӣеҸӮж•°дј°и®ЎеҖјпјҢжҲ‘们дҫҝеҸҜж №жҚ®д»·ж јеҢәй—ҙжЁЎеһӢгҖҒд»·ж јдёӯзӮ№жЁЎеһӢе’Ңд»·ж јиҢғеӣҙжЁЎеһӢеҲҶеҲ«йў„жөӢд»·ж јеҢәй—ҙгҖҒд»·ж јдёӯзӮ№е’Ңд»·ж јиҢғеӣҙгҖӮChouпјҲ2005пјүйҮҮз”ЁдёҺ Engle and RussellпјҲ1998пјүзӣёдјјзҡ„е»әжЁЎж–№жі•пјҢеҒҮи®ҫд»·ж јиҢғеӣҙзҡ„жқЎд»¶еқҮеҖјйҒөд»Һзұ»дјј GARCH зҡ„з»“жһ„пјҢдҪҝз”Ёд»·ж јиҢғеӣҙзҡ„еҺҶеҸІж•°жҚ®йў„жөӢе°ҶжқҘзҡ„д»·ж јиҢғеӣҙгҖӮиҝҷдёӘжЁЎеһӢз§°дёәжқЎд»¶еӣһеҪ’иҢғеӣҙпјҲConditional Autoregressive RangeпјҢCARRпјүжЁЎеһӢгҖӮз”ұдәҺд»·ж јиҢғеӣҙжҳҜжңҖй«ҳд»·еҮҸжңҖдҪҺд»·пјҢеҢәй—ҙж•°жҚ®зҡ„дёӯзӮ№дҝЎжҒҜиў«е·®еҲҶжҺүдәҶпјҢеӣ жӯӨеңЁдј°и®Ў CARR жЁЎеһӢзҡ„жңӘзҹҘеҸӮж•°ж—¶еҸӘеҲ©з”ЁдәҶд»·ж јиҢғеӣҙзҡ„дҝЎжҒҜпјҢжІЎжңүе……еҲҶеҲ©з”ЁеҢәй—ҙж•°жҚ®зҡ„дҝЎжҒҜгҖӮдёҚеҗҢдәҺ ChouпјҲ2005пјүе’Ң He et al.пјҲ2021пјүзӣҙжҺҘйҮҮз”ЁеҢәй—ҙж•°жҚ®дј°и®ЎеҢәй—ҙжЁЎеһӢзҡ„жңӘзҹҘеҸӮж•°пјҢз”ұдәҺжҜ”иҫғжңүж•Ҳең°еҲ©з”ЁеҢәй—ҙж•°жҚ®дҝЎжҒҜпјҢжүҖдј°и®Ўзҡ„еҸӮж•°жӣҙеҮҶзЎ®гҖӮHe et al.пјҲ2021пјүеҸ‘зҺ°пјҢд»ҺеҢәй—ҙжЁЎеһӢиЎҚз”ҹеҮәжқҘзҡ„д»·ж јиҢғеӣҙжЁЎеһӢеҜ№жіўеҠЁзҺҮзҡ„ж ·жң¬еӨ–йў„жөӢжҜ”еҹәдәҺд»·ж јиҢғеӣҙж•°жҚ®зҡ„ CARR жЁЎеһӢжӣҙзІҫеҮҶгҖӮ
пјҲдәҢпјүжңәеҷЁеӯҰд№ дёҺй«ҳз»ҙи®ЎйҮҸз»ҸжөҺеӯҰжЁЎеһӢ
з»ҹи®ЎеӯҰжңүдёҖдёӘиҜҚеҸ«з»ҙж•°зҒҫйҡҫпјҢж„ҸжҖқжҳҜдёҖдёӘз»ҹи®ЎжЁЎеһӢдёӯзҡ„и§ЈйҮҠеҸҳйҮҸзҡ„ж•°зӣ® pзӣёеҜ№дәҺж ·жң¬е®№йҮҸ n жҳҫеҫ—еҫҲеӨ§пјҢз”ҡиҮіи¶…иҝҮж ·жң¬е®№йҮҸгҖӮеҰӮжһңи§ЈйҮҠеҸҳйҮҸзҡ„ж•°зӣ® p еӨ§дәҺж ·жң¬е®№йҮҸ n зҡ„иҜқпјҢйӮЈд№ҲпјҢеҜ№дәҺй«ҳз»ҙзәҝжҖ§еӣһеҪ’жЁЎеһӢжқҘиҜҙпјҢйҰ–е…Ҳи§ЈйҮҠеҸҳйҮҸжһ„жҲҗзҡ„йҖҶзҹ©йҳөпјҲX'Xпјү-1 е°ұдёҚеӯҳеңЁгҖӮи§ЈеҶіиҝҷдёӘй—®йўҳзҡ„дёҖдёӘеҹәжң¬еҠһжі•е°ұжҳҜйҷҚз»ҙгҖӮз»ҹи®ЎеӯҰжңүеҫҲеӨҡйҷҚз»ҙж–№жі•пјҢеҢ…жӢ¬дё»жҲҗеҲҶеҲҶжһҗе’Ңеӣ еӯҗжЁЎеһӢгҖӮиҝҳжңүдёҖдёӘеҺӢзј©дј°и®Ўж–№жі•пјҲLeastAbsolute Shrinkage Selection OperatorпјҢLASSOпјүпјҢз”ұз»ҹи®ЎеӯҰ家 TibshiraniпјҲ1996пјүжҸҗеҮәгҖӮиҜҘж–№жі•жңүдёҖдёӘеҹәжң¬еҒҮи®ҫеҸ«зЁҖз–ҸжҖ§пјҢеҚіеҒҮи®ҫеӯҳеңЁеҫҲеӨҡжҪңеңЁзҡ„и§ЈйҮҠеҸҳйҮҸпјҢдҪҶе…¶дёӯеҸӘжңүе°‘ж•°еҮ дёӘжңӘзҹҘеҸҳйҮҸзҡ„зі»ж•°дёҚдёәйӣ¶пјҢе…¶д»–еҸҳйҮҸзҡ„зі»ж•°йғҪзӯүдәҺйӣ¶гҖӮеңЁиҝҷз§Қжғ…еҪўдёӢпјҢеҸҜд»Ҙеј•е…ҘдёҖдёӘжғ©зҪҡйЎ№пјҢеҚіжүҖжңүжңӘзҹҘеҸӮж•°з»қеҜ№еҖјд№Ӣе’Ңе°ҸдәҺжҹҗдёӘеёёж•°йҳҲеҖјгҖӮеҰӮжһңжҳҜдәҢз»ҙзҡ„иҜқпјҢиҝҷдёӘйҷҗеҲ¶е°ұжҳҜ |ОІ1+ОІ2| е°ҸдәҺжҹҗдёӘеёёж•°пјҢиҝҷеңЁеҮ дҪ•дёҠеҸҜиЎЁзӨәдёәдёҖдёӘиҸұеҪўгҖӮLASSO еҮҶеҲҷжңүдёҖдёӘзү№зӮ№пјҢдјҡдә§з”ҹи§’зӮ№и§ЈпјҲcorner solutionпјүпјҢеҚіжҜҸдёӘзі»ж•°дј°и®ЎиҰҒд№Ҳз»ҷдёҖдёӘдёҚзӯүдәҺйӣ¶зҡ„еҖјпјҢиҰҒд№ҲеҰӮжһңе…¶дј°и®ЎеҖјеҫҲе°Ҹж—¶пјҢзӣҙжҺҘжҠҠе®ғеҪ’йӣ¶гҖӮеҸҜд»ҘиҜҒжҳҺпјҢеҪ“ж ·жң¬е®№йҮҸи¶ӢдәҺж— з©·еӨ§ж—¶пјҢиў«зӣҙжҺҘеҪ’йӣ¶зҡ„йӮЈдәӣзі»ж•°жҒ°еҘҪе°ұжҳҜе…¶еҖјдёәйӣ¶зҡ„зңҹе®һзі»ж•°гҖӮиҝҷж ·пјҢйҖҡиҝҮйҷҚз»ҙпјҢLASSO еӨ§е№…еәҰеҮҸе°‘дј°и®ЎеҖјж–№е·®пјҢеңЁйў„жөӢж–№е·®е’ҢеҒҸе·®д№Ӣй—ҙеҸ–еҫ—е№іиЎЎпјҢе®һзҺ°зІҫеҮҶйў„жөӢгҖӮиҝҷдёӘж–№жі•еҸ«еҒҡз»ҹи®ЎеӯҰд№ пјҢдёҺжңәеҷЁеӯҰд№ зҡ„еҺҹзҗҶйқһеёёзұ»дјјпјҢд№ҹжңүдәәе°Ҷе®ғз§°дёәжңәеҷЁеӯҰд№ пјҢдҪҶеӨ§йғЁеҲҶжңәеҷЁеӯҰд№ ж–№жі•е№¶дёҚеұҖйҷҗдәҺдҪҝз”ЁзәҝжҖ§еӣһеҪ’жЁЎеһӢгҖӮ
LASSO ж–№жі•еҸҜжҺЁе№ҝеҲ°и§ЈеҶіи®ЎйҮҸз»ҸжөҺеӯҰзҡ„е…¶д»–й—®йўҳдёҠпјҢеҰӮиҜҶеҲ«еӣ жһңе…ізі»гҖӮиҜҶеҲ«з»ҸжөҺеӣ жһңе…ізі»жңҖеҹәжң¬зҡ„и®ЎйҮҸз»ҸжөҺеӯҰе·Ҙе…·жҳҜдёӨйҳ¶ж®өжңҖе°ҸдәҢд№ҳжі•пјҲTwo-StageLeast SquaresпјҢ2SLSпјүгҖӮдҪңиҖ…д№ӢдёҖеңЁ 20 дё–зәӘ 90 е№ҙд»Јж”»иҜ»еҚҡеЈ«жңҹй—ҙпјҢжӣҫеҸӮдёҺдёҖдёӘиҜҫйўҳз ”з©¶пјҲGroves et al., 1994пјүпјҢз ”з©¶ 20 дё–зәӘ 80 е№ҙд»ЈдёӯеӣҪзҡ„дёӯе°ҸеӣҪжңүдјҒдёҡеҘ–йҮ‘е’Ңдә§еҮәд№Ӣй—ҙзҡ„е…ізі»гҖӮеңЁ 80 е№ҙд»ЈпјҢеӣҪжңүдјҒдёҡеј•е…ҘеҘ–йҮ‘еҲ¶еәҰпјҢж”№йқ©д№ӢеүҚе·Ҙдәәзҡ„е·Ҙиө„收е…Ҙеӣәе®ҡпјҢж”№йқ©д№ӢеҗҺе»әз«ӢдәҶеҘ–йҮ‘еҲ¶еәҰпјҢеҰӮжһңе№Іеҫ—еӨҡе№Іеҫ—еҘҪпјҢе°ұиғҪеӨҹеҫ—еҲ°зӣёеә”зҡ„еҘ–йҮ‘пјӣеҰӮжһңиҝҹеҲ°ж—©йҖҖе№ІдёҚеҘҪпјҢеҘ–йҮ‘е°ұжІЎжңүдәҶгҖӮж №жҚ®з®ЎзҗҶз»ҸжөҺеӯҰзҡ„еҺҹзҗҶпјҢеҘ–йҮ‘е°ҶжҝҖеҠұе·Ҙдәәзҡ„еҠіеҠЁз§ҜжһҒжҖ§пјҢд»ҺиҖҢжҸҗй«ҳдјҒдёҡз”ҹдә§зҺҮгҖӮеӣ жӯӨпјҢеҸҜд»Ҙз”ЁдёҖдёӘж–№зЁӢиЎЁзӨәеҘ–йҮ‘дјҡжҸҗеҚҮеҠіеҠЁз”ҹдә§зҺҮпјҢиҝҷжҳҜд»ҺеҘ–йҮ‘еҲ°еҠіеҠЁз”ҹдә§зҺҮзҡ„еӣ жһңе…ізі»гҖӮдҪҶеҜ№дәҺдёҖдәӣеһ„ж–ӯиЎҢдёҡгҖҒзү№ж®ҠиЎҢдёҡзҡ„дјҒдёҡпјҢе…¶жң¬иә«еҲ©ж¶Ұе°ұжҜ”иҫғй«ҳпјҢд»ҳз»ҷе·Ҙдәәзҡ„еҘ–йҮ‘д№ҹе°ұжҜ”иҫғеӨҡгҖӮиҝҷе°ұеӯҳеңЁеҸҰеӨ–дёҖдёӘж–№зЁӢпјҢеҚіеҲ©ж¶Ұиҫғй«ҳзҡ„дјҒдёҡпјҢд»ҳз»ҷе·Ҙдәәзҡ„еҘ–йҮ‘д№ҹжҜ”иҫғеӨҡпјҢиҝҷжҳҜд»ҺеҠіеҠЁз”ҹдә§зҺҮеҲ°еҘ–йҮ‘зҡ„йҖҶеҗ‘еӣ жһңе…ізі»гҖӮз”ұдәҺдә§еҮәдёҺеҘ–йҮ‘д№Ӣй—ҙеӯҳеңЁеҸҢеҗ‘еӣ жһңе…ізі»пјҢеҜјиҮҙд»ҺеҘ–йҮ‘еҲ°дә§еҮәзҡ„жЁЎеһӢеӯҳеңЁжүҖи°“зҡ„еҶ…еңЁжҖ§пјҢеҚіеңЁз¬¬дёҖдёӘж–№зЁӢдёӯпјҢеҘ–йҮ‘дёҺйҡҸжңәжү°еҠЁйЎ№д№Ӣй—ҙеӯҳеңЁзӣёе…іжҖ§пјҢеӣ жӯӨжңҖе°ҸдәҢд№ҳжі•дј°и®ЎеӯҳеңЁеҒҸе·®гҖӮдёҖдёӘеёёз”Ёзҡ„и§ЈеҶіеҠһжі•жҳҜйҮҮз”Ё 2SLS жі•пјҢе…¶е…ій”®жҳҜйҖүжӢ©еҗҲйҖӮзҡ„е·Ҙе…·еҸҳйҮҸгҖӮжүҖи°“е·Ҙе…·еҸҳйҮҸ Zt йңҖиҰҒж»Ўи¶ідёүдёӘжқЎд»¶пјҡ第дёҖпјҢZtдёҺ第дёҖдёӘж–№зЁӢзҡ„и§ЈйҮҠеҸҳйҮҸ Xt д№Ӣй—ҙй«ҳеәҰзӣёе…іпјҢеҚі EпјҲ XtZtвҖІпјүвү 0пјӣ第дәҢпјҢZtдёҺ第дёҖдёӘж–№зЁӢзҡ„йҡҸжңәжү°еҠЁйЎ№ Оөt дёҚзӣёе…іпјҢеҚіEпјҲ Оөt|Ztпјү = 0пјӣ第дёүпјҢZtзҡ„дёӘж•°дёҚе°‘дәҺи§ЈйҮҠеҸҳйҮҸ Xtзҡ„дёӘж•°гҖӮ
еңЁз¬¬дёҖйҳ¶ж®өпјҢйҖҡиҝҮиҫ…еҠ©зәҝжҖ§еӣһеҪ’ Xt=ОівҖІ Zt + П…t пјҢеҸҜеҫ—еҲ°жӢҹеҗҲеҖј
 гҖӮеңЁз¬¬дәҢйҳ¶ж®өпјҢе°ҶеҺҹжқҘзҡ„еӣ еҸҳйҮҸ Yt еҜ№жӢҹеҗҲеҖј
гҖӮеңЁз¬¬дәҢйҳ¶ж®өпјҢе°ҶеҺҹжқҘзҡ„еӣ еҸҳйҮҸ Yt еҜ№жӢҹеҗҲеҖј
 иҝӣиЎҢеӣһеҪ’пјҢиҝҷдёӘ第дәҢйҳ¶ж®өзҡ„жңҖе°ҸдәҢд№ҳжі•дј°и®ЎйҮҸдҫҝеҸҜд»ҘдёҖиҮҙдј°и®ЎеҘ–йҮ‘зі»ж•°пјҡ
иҝӣиЎҢеӣһеҪ’пјҢиҝҷдёӘ第дәҢйҳ¶ж®өзҡ„жңҖе°ҸдәҢд№ҳжі•дј°и®ЎйҮҸдҫҝеҸҜд»ҘдёҖиҮҙдј°и®ЎеҘ–йҮ‘зі»ж•°пјҡ

е·Ҙе…·еҸҳйҮҸиө·дәҶд»Җд№ҲдҪңз”Ёе‘ўпјҹе®ғе®һйҷ…дёҠе°Ҷд»ҺеҠіеҠЁз”ҹдә§зҺҮеҲ°еҘ–йҮ‘зҡ„еӣ жһңе…ізі»еҲҮж–ӯпјҢеҸӘз•ҷдёӢд»ҺеҘ–йҮ‘еҲ°еҠіеҠЁз”ҹдә§зҺҮзҡ„еӣ жһңе…ізі»пјҢеӣ жӯӨеҸҜеҫ—еҲ°дёҖиҮҙеҸӮж•°дј°и®ЎгҖӮ
еҫҲеӨҡе®һиҜҒз ”з©¶еҸ‘зҺ°пјҢжүҖйҖүжӢ©зҡ„е·Ҙе…·еҸҳйҮҸ ZtдёҺи§ЈйҮҠеҸҳйҮҸXt д№Ӣй—ҙзҡ„зӣёе…іжҖ§еёёеёёеҫҲе°ҸпјҢеҚіеӯҳеңЁејұзӣёе…іпјҢеҜјиҮҙ 2SLS дј°и®ЎдёҚзІҫзЎ®пјҢз”ҡиҮідёҚиғҪдёҖиҮҙдј°и®Ўзңҹе®һеҘ–йҮ‘еҸӮж•°гҖӮиҝҷз§Қжғ…еҶөз§°дёәвҖңејұе·Ҙе…·еҸҳйҮҸвҖқпјҲStaiger and StockпјҢ1997пјүгҖӮиҰҒи§ЈеҶіејұе·Ҙе…·еҸҳйҮҸй—®йўҳпјҢеҸҜд»ҘеўһеҠ е·Ҙе…·еҸҳйҮҸдёӘж•°пјҢдҪҶжҳҜдёҖж—Ұе·Ҙе…·еҸҳйҮҸзҡ„дёӘж•°зү№еҲ«еӨҡж—¶пјҢйңҖиҰҒдј°и®Ўзҡ„жңӘзҹҘзі»ж•°д№ҹдјҡеўһеӨҡпјҢе°ҶеҜјиҮҙзұ»дјјвҖңз»ҙж•°зҒҫйҡҫвҖқзҡ„й—®йўҳгҖӮзҺ°еңЁпјҢеҸҜд»Ҙз”ЁеӨ§ж•°жҚ®еҠ жңәеҷЁеӯҰд№ зҡ„ж–№жі•пјҢеӨ§ж•°жҚ®еҸҜд»ҘжҸҗдҫӣй«ҳз»ҙжҪңеңЁзҡ„е·Ҙе…·еҸҳйҮҸпјҢе…¶дёӯеҸҜиғҪеҸӘжңүе°‘ж•°еҮ дёӘеҸҳйҮҸжҜ”иҫғжңүж•ҲпјҢеҚідёҺи§ЈйҮҠеҸҳйҮҸзӣёе…іжҖ§иҫғй«ҳпјҢдҪҶжҲ‘们并дёҚзҹҘйҒ“жҳҜе“ӘдәӣеҸҳйҮҸгҖӮжҲ‘们еңЁз¬¬дёҖйҳ¶ж®өеӣһеҪ’пјҲXt=ОівҖІ Zt + П…tпјүж—¶пјҢеҸҜд»ҘйҮҮз”Ёзұ»дјј LASSO ж–№жі•пјҢе°ҶжңҖйҮҚиҰҒзҡ„йӮЈдәӣе·Ҙе…·еҸҳйҮҸиҜҶеҲ«еҮәжқҘпјҢд»ҺиҖҢж”№иҝӣ 2SLS дј°и®Ўзҡ„зІҫеҮҶжҖ§гҖӮ
пјҲдёүпјүжңәеҷЁеӯҰд№ дёҺж”ҝзӯ–иҜ„дј°
ж”№йқ©ејҖж”ҫд»ҘжқҘпјҢдёӯеӣҪйҖҡиҝҮе®һи·өжҺўзҙўпјҢе»әз«ӢдәҶдёӯеӣҪзү№иүІзӨҫдјҡдё»д№үеёӮеңәз»ҸжөҺдҪ“еҲ¶пјҢеёӮеңәеңЁиө„жәҗй…ҚзҪ®дёӯеҸ‘жҢҘеҶіе®ҡжҖ§дҪңз”ЁпјҢеҗҢж—¶ж”ҝеәңд№ҹеҸ‘жҢҘзқҖйҮҚиҰҒдҪңз”ЁгҖӮж–°дёӯеӣҪ 70 еӨҡе№ҙзҡ„з»ҸжөҺе®һи·өиҜҒжҳҺпјҢеёӮеңәиҝҷеҸӘвҖңзңӢдёҚи§Ғзҡ„жүӢвҖқе’Ңж”ҝеәңиҝҷеҸӘвҖңзңӢеҫ—и§Ғзҡ„жүӢвҖқдёӨжүӢ并用пјҢжҜ”еҚ•зӢ¬дёҖеҸӘжүӢеҸ‘жҢҘдҪңз”ЁиҰҒжңүж•Ҳеҫ—еӨҡгҖӮеңЁдёӯеӣҪпјҢж”ҝеәңеҸ‘жҢҘдҪңз”Ёзҡ„дёҖдёӘйҮҚиҰҒж–№ејҸжҳҜйҖҡиҝҮеҲ¶е®ҡгҖҒе®һж–Ҫеҗ„з§Қз»ҸжөҺж”ҝзӯ–пјҢеҰӮдә”е№ҙи®ЎеҲ’пјҲ规еҲ’пјүгҖҒдә§дёҡж”ҝзӯ–гҖҒеҢәеҹҹеҸ‘еұ•ж”ҝзӯ–гҖҒиҙёжҳ“жҠ•иө„ж”ҝзӯ–гҖҒзІҫеҮҶжү¶иҙ«ж”ҝзӯ–д»ҘеҸҠиҙўж”ҝйҮ‘иһҚж”ҝзӯ–зӯүгҖӮиҝҷдәӣж”ҝзӯ–еңЁдёӯеӣҪз»ҸжөҺеҸ‘еұ•дёӯеҸ‘жҢҘдәҶе·ЁеӨ§дҪңз”ЁгҖӮдҪҶжҳҜпјҢй•ҝжңҹд»ҘжқҘпјҢдёҖдәӣйғЁй—ЁгҖҒдёҖдәӣең°ж–№зҡ„ж”ҝзӯ–пјҢжІЎжңүз»ҸиҝҮи®Өзңҹзҡ„и°ғз ”гҖҒи®ҫи®ЎдёҺи®әиҜҒпјҢдҫҝд»“дҝғеҮәеҸ°е®һж–ҪпјҢеҜјиҮҙж•ҲжһңдёҚзҗҶжғіпјҢз”ҡиҮіеҮәзҺ°ж”ҝзӯ–д»ҺеҮәеҸ°еҲ°еҸ–ж¶ҲдёҚи¶…иҝҮдёҖиҮідёӨе‘ЁеҜҝе‘Ҫзҡ„ж”ҝзӯ–д№ұиұЎгҖӮдҫӢеҰӮпјҢ2002 е№ҙ 8 жңҲе®һж–Ҫ 9 еӨ©еҚіеҸ«еҒңзҡ„вҖңдёӘжҖ§еҢ–иҪҰзүҢвҖқж”ҝзӯ–пјӣ2013 е№ҙ 1 жңҲе®һж–Ҫ 5 еӨ©еҚіеҸ«еҒңзҡ„вҖңиҝқеҸҚй»„зҒҜдҝЎеҸ·жүЈеҲҶж”ҝзӯ–вҖқпјӣ2015 е№ҙ 3 жңҲж–ҪиЎҢ 7 еӨ©еҚіе‘ҠеӨұиҙҘзҡ„вҖңйҮҚеәҶеҢ»ж”№вҖқпјӣ2016 е№ҙ 1 жңҲе®һж–Ҫ 4 дёӘдәӨжҳ“ж—ҘеҚіеҸ«еҒңзҡ„вҖңиӮЎеёӮзҶ”ж–ӯжңәеҲ¶вҖқпјӣ2016 е№ҙ 3 жңҲдёӢеҸ‘еҪ“жҷҡеҚіе®ЈеёғдёҚе…·еӨҮеҮәеҸ°жқЎд»¶зҡ„вҖңйӣ¶йҰ–д»ҳвҖқиҙӯжҲҝж”ҝзӯ–пјӣ2018 е№ҙ 5 жңҲ 4 еӨ©еҶ… 3ж¬ЎеўһиЎҘжқЎж¬ҫзҡ„вҖңдәәжүҚиҗҪжҲ·ж”ҝзӯ–вҖқпјӣ2018 е№ҙ 12 жңҲеҚ°еҸ‘ 8 еӨ©еҚіе®Јеёғж’Өй”Җзҡ„вҖңеҸ–ж¶Ҳйҷҗд»·д»ӨвҖқйҖҡзҹҘпјӣ2020 е№ҙ 2 жңҲеҚҠеӨ©еҶ…зҙ§жҖҘж’Өй”ҖгҖҠе…ідәҺеҠ ејәиҝӣеҮәжӯҰжұүеёӮиҪҰиҫҶе’Ңдәәе‘ҳз®ЎзҗҶзҡ„йҖҡе‘ҠгҖӢпјҲ第 17 еҸ·пјүпјӣ2020 е№ҙ 3 жңҲ 6 е°Ҹж—¶еҶ…дҫҝзҙ§жҖҘж’Өй”Җе…ідәҺвҖңжҪңжұҹдјҳеҢ–и°ғж•ҙеёӮеҶ…дәӨйҖҡз®ЎжҺ§гҖҒдәәе‘ҳз®ЎзҗҶе’ҢеӨҚе·ҘеӨҚдә§жҺӘж–ҪвҖқзҡ„йҖҡе‘ҠзӯүгҖӮ
дёӯеӣҪжӯЈеңЁжҺЁеҠЁз»ҸжөҺй«ҳиҙЁйҮҸеҸ‘еұ•пјҢиҝ«еҲҮйңҖиҰҒжҸҗй«ҳеҗ„з§Қж”ҝеәңз»ҸжөҺз®ЎзҗҶзІҫз»ҶеҢ–ж°ҙе№іпјҢзү№еҲ«жҳҜжҸҗеҚҮж”ҝзӯ–еҲ¶е®ҡзҡ„科еӯҰжҖ§гҖҒж”ҝзӯ–е®һж–Ҫзҡ„жңүж•ҲжҖ§гҖҒзІҫеҮҶжҖ§е’Ңж—¶ж•ҲжҖ§гҖӮе®ҡйҮҸиҜ„дј°ж”ҝзӯ–ж•Ҳеә”жҳҜдёҖдёӘйҮҚиҰҒзҺҜиҠӮгҖӮдёӯеӣҪжӯЈеңЁйҖҗжӯҘжҺЁиЎҢ第дёүж–№иҜ„дј°пјҢиҝҷеңЁдёҖе®ҡзЁӢеәҰдёҠеҸҜд»Ҙи§ЈеҶіж”ҝзӯ–иҜ„дј°зӢ¬з«ӢжҖ§зҡ„й—®йўҳпјҢдҪҶиҝҳйңҖиҰҒи§ЈеҶіж”ҝзӯ–иҜ„дј°зҡ„科еӯҰжҖ§й—®йўҳгҖӮ
жүҖи°“ж”ҝзӯ–иҜ„дј°пјҢжң¬иҙЁдёҠжҳҜз»ҸжөҺеӣ жһңе…ізі»еҲҶжһҗгҖӮеүҚж–ҮжҸҗеҲ°пјҢеҪұе“Қз»ҸжөҺз»“жһңYзҡ„еӣ зҙ йҷӨдәҶж”ҝзӯ–еҸҳйҮҸXд№ӢеӨ–пјҢиҝҳжңүеҫҲеӨҡе…¶д»–еӣ зҙ пјҲжңүдәӣеҸҜи§ӮжөӢпјҢжңүдәӣдёҚеҸҜи§ӮжөӢпјүгҖӮиҰҒиҜ„дј°ж”ҝзӯ–XеҜ№з»ҸжөҺз»“жһңY жңүж— ж•ҲжһңпјҢйңҖиҰҒжҺ§еҲ¶е…¶д»–еӣ зҙ дёҚеҸҳпјҢйҖҡиҝҮе®һж–Ҫж”ҝзӯ–XпјҢи§ӮжөӢз»ҸжөҺз»“жһңYжҳҜеҗҰж”№еҸҳпјҢеҰӮжһңж”№еҸҳдәҶпјҢйӮЈд№ҲиҝҷиЎЁжҳҺж”ҝзӯ–жҳҜжңүж•Ҳзҡ„гҖӮдҪҶжҳҜпјҢ з”ұдәҺз»ҸжөҺзі»з»ҹзҡ„йқһе®һйӘҢжҖ§пјҢжҲ‘们дёҚеҸҜиғҪжҺ§еҲ¶вҖңе…¶д»–еӣ зҙ вҖқдёҚеҸҳпјҢеңЁиҝҷз§Қжғ…еҶөдёӢпјҢеҰӮдҪ•иҜ„дј°ж”ҝзӯ–ж•Ҳеә”е‘ўпјҹ
既然вҖңе…¶д»–еӣ зҙ вҖқж— жі•жҺ§еҲ¶жҲ–иҖ…иҷҪеҸҜжҺ§еҲ¶дҪҶжңүеҫҲеӨ§еӣ°йҡҫпјҢжҲ‘们еҸҜд»Ҙи®©иҝҷдәӣеӣ зҙ 继з»ӯеҸҳеҢ–пјҢдҪҶжҳҜеҒҮи®ҫдёҚе®һж–Ҫж”ҝзӯ–е№Ійў„пјҢеҚіи®©ж”ҝзӯ–еҸҳйҮҸXдҝқжҢҒдёҚеҸҳгҖӮеңЁе·Із»Ҹе®һж–Ҫж”ҝзӯ–зҡ„зҺ°е®һжқЎд»¶дёӢеҒҮи®ҫж”ҝзӯ–жІЎжңүе®һж–ҪпјҢжҳҫ然жҳҜдёҖдёӘиҷҡжӢҹеҒҮи®ҫгҖӮжҲ‘们еҸҜи§ӮжөӢеҲ°ж”ҝзӯ–е®һж–ҪеҗҺзҡ„зҺ°е®һз»ҸжөҺз»“жһңYпјҢдҪҶж— жі•и§ӮжөӢиҷҡжӢҹеҒҮи®ҫжқЎд»¶дёӢзҡ„з»ҸжөҺз»“жһңY*пјҢз§°дёәиҷҡжӢҹдәӢе®һпјҲcounterfactualsпјүгҖӮеҰӮжһңеҸҜд»Ҙдј°и®ЎиҷҡжӢҹдәӢе®һY*пјҢйӮЈд№Ҳе°ұеҸҜд»ҘиҜ„дј°ж”ҝзӯ–ж•Ҳеә”дёә Y-Y*гҖӮеӣ жӯӨпјҢж”ҝзӯ–иҜ„дј°зҡ„е…ій”®еҸҳжҲҗеҰӮдҪ•зІҫеҮҶдј°и®ЎиҷҡжӢҹдәӢе®һY*гҖӮдёәдәҶдј°и®ЎY*пјҢеҸҜд»ҘеҹәдәҺж”ҝзӯ–еҮәеҸ°еүҚз»ҸжөҺеҸҳйҮҸд№Ӣй—ҙеӯҳеңЁзҡ„ж•°йҮҸе…ізі»пјҲиҝҷдәӣж•°йҮҸе…ізі»дёҚдёҖе®ҡжҳҜеӣ жһңе…ізі»пјүиҝӣиЎҢжӢҹеҗҲпјҢ然еҗҺеҶҚеҒҮи®ҫиҝҷдәӣж•°йҮҸе…ізі»дёҚеҸҳпјҲзү№еҲ«жҳҜдёҚеҸ—ж”ҝзӯ–е®һж–Ҫзҡ„еҪұе“ҚпјүпјҢеӨ–жҺЁпјҲж ·жң¬еӨ–пјүйў„жөӢиҷҡжӢҹдәӢе®һ Y*гҖӮдёҫдёҖдёӘдҫӢеӯҗпјҢи‘—еҗҚи®ЎйҮҸз»ҸжөҺеӯҰ家иҗ§ж”ҝеҸҠе…¶еҗҲдҪңиҖ…пјҲHsiao et al., 2012пјүжҸҗеҮәдәҶдёҖдёӘеҹәдәҺйқўжқҝж•°жҚ®жЁЎеһӢзҡ„ж”ҝзӯ–иҜ„дј°жі•пјҢиҜ„дј°еҶ…ең°дёҺйҰҷжёҜзү№еҲ«иЎҢеҢәпјҲд»ҘдёӢз®Җз§°вҖңйҰҷжёҜвҖқпјүдәҺ 2003 е№ҙзӯҫи®ўзҡ„гҖҠеҶ…ең°дёҺйҰҷжёҜе…ідәҺе»әз«Ӣжӣҙзҙ§еҜҶз»Ҹиҙёе…ізі»зҡ„е®үжҺ’гҖӢпјҲCEPAпјүеҚҸе®ҡеҜ№йҰҷжёҜз»ҸжөҺзҡ„еҪұе“ҚгҖӮдёәдәҶдј°и®ЎеҒҮи®ҫ 2003 е№ҙжІЎжңүзӯҫи®ў CEPA зҡ„жғ…еҪўдёӢпјҢйҰҷжёҜз»ҸжөҺжҜҸе№ҙзҡ„иҷҡжӢҹеўһй•ҝзҺҮпјҢиҗ§ж”ҝзӯүеҹәдәҺ CEPA зӯҫи®ўеүҚйҰҷжёҜе’Ңе…ЁзҗғеҗҲдҪңдјҷдјҙзҡ„з»ҸиҙёеҫҖжқҘж•°жҚ®пјҢйҖҡиҝҮдёҖдёӘеҠЁжҖҒеӣ еӯҗжЁЎеһӢдј°и®ЎйҰҷжёҜз»ҸжөҺеўһй•ҝпјҢиҝҷдёӘжЁЎеһӢ并дёҚжҳҜеӣ жһңе…ізі»жЁЎеһӢпјҢиҖҢжҳҜеҹәдәҺйў„жөӢе…ізі»пјҢеҸҜз”ЁдәҺеӨ–жҺЁйў„жөӢ 2003 е№ҙеҗҺеҒҮи®ҫжІЎжңүе®һж–Ҫ CEPA зҡ„жғ…еҪўдёӢпјҢйҰҷжёҜиҷҡжӢҹз»ҸжөҺеўһй•ҝзҺҮY*гҖӮиҗ§ж”ҝзӯүдј°и®Ў CEPA зӯҫи®ўз»ҷйҰҷжёҜеёҰжқҘ 4% е·ҰеҸізҡ„з»ҸжөҺеўһй•ҝгҖӮ
иҷҡжӢҹдәӢе®һдј°и®Ўжң¬иҙЁдёҠжҳҜдёҖз§Қж ·жң¬еӨ–йў„жөӢгҖӮеңЁиҝҷж–№йқўпјҢеҹәдәҺеӨ§ж•°жҚ®зҡ„жңәеҷЁеӯҰд№ еҸҜд»ҘеҸ‘жҢҘе…¶дјҳеҠҝпјҢзІҫеҮҶйў„жөӢиҷҡжӢҹдәӢе®һY*пјҢд»ҺиҖҢзІҫеҮҶиҜ„дј°ж”ҝзӯ–ж•Ҳеә”гҖӮйңҖиҰҒејәи°ғпјҢжңәеҷЁеӯҰд№ зҡ„зІҫеҮҶйў„жөӢдёҚжҳҜеҹәдәҺеӣ жһңе…ізі»иҖҢжҳҜеҹәдәҺеӨ§ж•°жҚ®дёӯзҡ„еҸҳйҮҸзү№еҫҒдёҺеҸҳйҮҸд№Ӣй—ҙзҡ„з»ҹи®Ўе…ізі»пјҢдҪҶжҳҜжңәеҷЁеӯҰд№ йў„жөӢеҸҜд»ҘжӣҙзІҫеҮҶиҜҶеҲ«дёҺжөӢеәҰж”ҝзӯ–е№Ійў„зҡ„еӣ жһңж•Ҳеә”гҖӮзӣ®еүҚпјҢеҹәдәҺжңәеҷЁеӯҰд№ зҡ„еӣ жһңжҺЁж–ӯж–№жі•еҢ…жӢ¬еӣ жһңйҡҸжңәжЈ®жһ—пјҲcasualrandom forestsпјүж–№жі•пјҲWager and AtheyпјҢ2018; Athey et al., 2019пјүе’ҢиҙқеҸ¶ж–ҜзҙҜеҠ еӣһеҪ’ж ‘пјҲBayesian additive regression treeпјүж–№жі•пјҲChipman et al., 2010; Hillet al., 2020пјүгҖӮ
дёғгҖҒз»“жқҹиҜӯ
з»ҸжөҺеӯҰзҡ„з ”з©¶иҢғејҸе’Ңз ”з©¶ж–№жі•е№¶йқһеӣәе®ҡдёҚеҸҳпјҢиҖҢжҳҜйҡҸж—¶д»Јзҡ„еҸҳиҝҒиҖҢдёҚж–ӯеҸҳеҢ–пјҢдё”и¶ҠжқҘи¶Ҡз¬ҰеҗҲ科еӯҰз ”з©¶иҢғејҸпјҢеҚіжҜҸдёӘз»ҸжөҺзҗҶи®әжҲ–еҒҮиҜҙпјҢйғҪеҝ…йЎ»иҝӣиЎҢз»ҸйӘҢпјҲж•°жҚ®пјүжЈҖйӘҢгҖӮеңЁж•°еӯ—з»ҸжөҺж—¶д»ЈпјҢеӨ§ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ зҡ„еҮәзҺ°пјҢдёәз»ҸжөҺеӯҰзҡ„з ”з©¶иҢғејҸе’Ңз ”з©¶ж–№жі•еёҰжқҘеҫҲеӨҡжңәйҒҮе’ҢжҢ‘жҲҳгҖӮ
еӨ§ж•°жҚ®зү№еҲ«жҳҜж–Үжң¬ж•°жҚ®з»ҷз»ҸжөҺеӯҰз ”з©¶иҢғејҸеёҰжқҘзҡ„дёҖдёӘйҮҚиҰҒеҸҳеҢ–жҳҜдҪҝдәәж–Үз»ҸжөҺеӯҰзҡ„е®ҡйҮҸе®һиҜҒз ”з©¶жҲҗдёәеҸҜиғҪгҖӮдҪңдёәдәәзұ»зӨҫдјҡзҡ„дёҖдёӘйҮҚиҰҒз»„жҲҗйғЁеҲҶпјҢз»ҸжөҺе’Ңдәәзұ»зӨҫдјҡзҡ„е…¶д»–ж–№йқўпјҢеҢ…жӢ¬ж”ҝжІ»гҖҒжі•еҫӢгҖҒзӨҫдјҡгҖҒеҺҶеҸІгҖҒж–ҮеҢ–гҖҒдјҰзҗҶгҖҒеҝғзҗҶгҖҒжғ…ж„ҹгҖҒз”ҹжҖҒзҺҜеўғгҖҒеҚ«з”ҹеҒҘеә·зӯүеӣ зҙ пјҢйғҪзҙ§еҜҶиҒ”зі»еңЁдёҖиө·пјҢзү№еҲ«жҳҜж–°зҡ„жҠҖжңҜйқ©е‘Ҫе’Ңдә§дёҡйқ©е‘ҪжӯЈеңЁж·ұеҲ»ж”№йқ©дәәзұ»з”ҹдә§дёҺз”ҹжҙ»ж–№ејҸпјҢж”№еҸҳзӨҫдјҡз”ҹдә§еҠӣдёҺз”ҹдә§е…ізі»пјҢж”№еҸҳз»ҸжөҺеҹәзЎҖдёҺдёҠеұӮе»әзӯ‘гҖӮеӣ жӯӨпјҢйңҖиҰҒйҮҮз”Ёзі»з»ҹж–№жі•пјҢеңЁдёҖдёӘжӣҙеӨ§зҡ„дәәж–Үз»ҸжөҺеӯҰеҲҶжһҗжЎҶжһ¶дёӯз ”з©¶з»ҸжөҺй—®йўҳпјҢжҺЁеҠЁз»ҸжөҺеӯҰе’Ңдәәж–ҮзӨҫдјҡ科еӯҰе…¶д»–йўҶеҹҹзҡ„дәӨеҸүиһҚеҗҲе’Ңи·ЁеӯҰз§‘з ”з©¶пјҢд»ҘеҜ»жүҫи§ЈеҶіеҗ„з§ҚзӨҫдјҡз»ҸжөҺй—®йўҳзҡ„зі»з»ҹж–№жі•гҖӮиҝҷжҳҜд»ҠеҗҺз»ҸжөҺеӯҰз ”з©¶зҡ„дёҖдёӘйҮҚиҰҒж–№еҗ‘гҖӮеҸҰдёҖдёӘйҮҚиҰҒеҸҳеҢ–жҳҜпјҢеӨ§ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ е°ҶеёҰжқҘз»ҸжөҺеӯҰе®һиҜҒз ”з©¶зҡ„ж–№жі•еҲӣж–°гҖӮз”ұдәҺеҲҶжһҗеҜ№иұЎвҖ”вҖ”ж•°жҚ®зҡ„зү№зӮ№еҸ‘з”ҹдәҶйҮҚеӨ§еҸҳеҢ–пјҢз»ҸжөҺеӯҰзҡ„е®һиҜҒз ”з©¶ж–№жі•пјҢеҚіеҹәдәҺж•°жҚ®зҡ„жҺЁж–ӯж–№жі•д№ҹйҡҸд№Ӣж”№еҸҳпјҢиҝҷдёәи®ЎйҮҸз»ҸжөҺеӯҰзҗҶи®әдёҺж–№жі•еҲӣж–°жҸҗдҫӣдәҶеҗ„з§ҚеҸҜиғҪжҖ§пјҢзү№еҲ«жҳҜз»ҸжөҺеӨ§ж•°жҚ®дә§з”ҹдәҶеҫҲеӨҡж–°еһӢж•°жҚ®пјҢдёҚдҪҶжңүз»“жһ„еҢ–ж•°жҚ®пјҢиҖҢдё”иҝҳжңүйқһз»“жһ„еҢ–ж•°жҚ®пјҢз»“жһ„еҢ–ж•°жҚ®д№ҹеҢ…жӢ¬дёҚе°‘ж–°еһӢж•°жҚ®пјҢеҰӮеҢәй—ҙж•°жҚ®гҖҒз¬ҰеҸ·ж•°жҚ®гҖҒеҮҪж•°ж•°жҚ®зӯүгҖӮж–°еһӢж•°жҚ®е‘је”ӨеҲӣж–°и®ЎйҮҸз»ҸжөҺеӯҰжЁЎеһӢдёҺж–№жі•пјҢиҝҷдәӣж–°еһӢжЁЎеһӢдёҺж–№жі•е°Ҷжӣҙжңүж•ҲеҲ©з”Ёж•°жҚ®дҝЎжҒҜпјҢдҪҝз»ҹи®ЎжҺЁж–ӯдј°и®Ўж–№жі•жӣҙдёәжңүж•ҲпјҢеҒҮи®ҫжЈҖйӘҢжӣҙжңүж•ҲзҺҮпјҢйў„жөӢжӣҙзІҫеҮҶгҖӮжңәеҷЁеӯҰд№ еҸҜд»ҘеҜ№й«ҳз»ҙжҲ–и¶…й«ҳз»ҙж•°жҚ®е®һзҺ°йҷҚз»ҙпјҢеҫ—еҲ°жӣҙдёәжңүж•Ҳзҡ„з»ҹи®ЎжҺЁж–ӯе’ҢжӣҙзІҫеҮҶзҡ„йў„жөӢгҖӮз»ҙж•°зҒҫйҡҫдёҖзӣҙжҳҜи®ЎйҮҸз»ҸжөҺеӯҰе»әжЁЎйқўдёҙзҡ„дёҖдёӘдёӨйҡҫй—®йўҳпјҢеҚіжЁЎеһӢдёӯеҫ…дј°и®Ўзҡ„жңӘзҹҘеҸӮж•°ж•°зӣ®зӣёеҜ№дәҺж ·жң¬е®№йҮҸжҳҫеҫ—еҫҲеӨ§пјҢз”ҡиҮіжҜ”ж ·жң¬е®№йҮҸиҝҳиҰҒеӨ§гҖӮдёҖж–№йқўпјҢжҲ‘们еёҢжңӣи®ЎйҮҸз»ҸжөҺеӯҰжЁЎеһӢиғҪеӨҹе°ҪйҮҸеҢ…жӢ¬еҜ№з»ҸжөҺеҸҜиғҪжңүеҪұе“Қзҡ„еҗ„з§Қеӣ зҙ пјҢд»ҘжҸҗй«ҳжЁЎеһӢзҡ„и§ЈйҮҠиғҪеҠӣжҲ–йў„жөӢиғҪеҠӣпјӣдҪҶеҸҰдёҖж–№йқўпјҢеҪ“и§ЈйҮҠеҸҳйҮҸжҲ–йў„жөӢеҸҳйҮҸзҡ„з»ҙж•°еҫҲй«ҳж—¶пјҢйңҖиҰҒдј°и®Ўзҡ„жңӘзҹҘеҸӮж•°з»ҙж•°д№ҹдјҡеҫҲеӨ§пјҢз”ҡиҮіи¶…иҝҮж ·жң¬е®№йҮҸгҖӮеңЁиҝҷз§Қжғ…еҪўдёӢпјҢзІҫзЎ®дј°и®Ўй«ҳз»ҙжңӘзҹҘеҸӮж•°жҳҜеҚҒеҲҶеӣ°йҡҫз”ҡиҮіжҳҜдёҚеҸҜиғҪзҡ„гҖӮдҪҶжҳҜпјҢеҰӮжһңй«ҳз»ҙи§ЈйҮҠеҸҳйҮҸжҲ–йў„жөӢеҸҳйҮҸдёӯеҸӘжңүдёҖе°ҸйғЁеҲҶжңӘзҹҘеҸҳйҮҸеҜ№еӣ еҸҳйҮҸжңүеҪұе“ҚпјҢеҲҷеҸҜд»ҘйҖҡиҝҮжңәеҷЁеӯҰд№ жӯЈеҲҷжі•е®һзҺ°йҷҚз»ҙпјҢеү”йҷӨеӨ§йҮҸж— е…ізҡ„еҸҳйҮҸгҖӮиҝҷж ·пјҢе°ұеҸҜд»ҘиҺ·еҫ—дёҖдёӘз®ҖзәҰжЁЎеһӢпјҢе…·жңүиҫғејәзҡ„зЁіеҒҘжҖ§е’ҢиҫғеҘҪзҡ„еҸҜи§ЈйҮҠжҖ§пјҢе…¶ж ·жң¬еӨ–йў„жөӢиғҪеҠӣе°ҶжҜ”иҫғзІҫеҮҶгҖӮжӯӨеӨ–пјҢеӨ§ж•°жҚ®е’ҢжңәеҷЁеӯҰд№ д№ҹжңүеҠ©дәҺжӣҙзІҫзЎ®е®ҡйҮҸиҜ„дј°ж”ҝзӯ–ж•Ҳеә”пјҢд»ҺиҖҢжӣҙеҘҪеҸ‘жҢҘж”ҝеәңдҪңз”ЁгҖӮ
| 
 й«ҳз‘һдёңзӯүпјҡ2025е№ҙиө„дә§
й«ҳз‘һдёңзӯүпјҡ2025е№ҙиө„дә§ еҶңдёҡж–°иҙЁз”ҹдә§еҠӣпјҡеҶ…ж¶ө
еҶңдёҡж–°иҙЁз”ҹдә§еҠӣпјҡеҶ…ж¶ө еҲҳдҝҠжқ°зӯүпјҡжһ„е»әйҖӮеә”еҶң
еҲҳдҝҠжқ°зӯүпјҡжһ„е»әйҖӮеә”еҶң 11жңҲе…Ёзҗғи°·зү©еёӮеңәдёҺиҙё
11жңҲе…Ёзҗғи°·зү©еёӮеңәдёҺиҙё з®Ўж¶ӣзӯүпјҡпјҡдәәж°‘еёҒжұҮзҺҮ
з®Ўж¶ӣзӯүпјҡпјҡдәәж°‘еёҒжұҮзҺҮ й’ҹжӯЈз”ҹпјҡеҗ‘е®ҢжҲҗйў„з®—зӣ®
й’ҹжӯЈз”ҹпјҡеҗ‘е®ҢжҲҗйў„з®—зӣ® жқҺиҝ…йӣ·пјҡжҳҺе№ҙиҙўж”ҝиөӨеӯ—
жқҺиҝ…йӣ·пјҡжҳҺе№ҙиҙўж”ҝиөӨеӯ— еј зәўе®Үпјҡжһ„е»әе…·жңүдёӯеӣҪ
еј зәўе®Үпјҡжһ„е»әе…·жңүдёӯеӣҪ ж—әеӯЈдёҚж—ә еҪ“еүҚз”ҹзҢӘеёӮ
ж—әеӯЈдёҚж—ә еҪ“еүҚз”ҹзҢӘеёӮ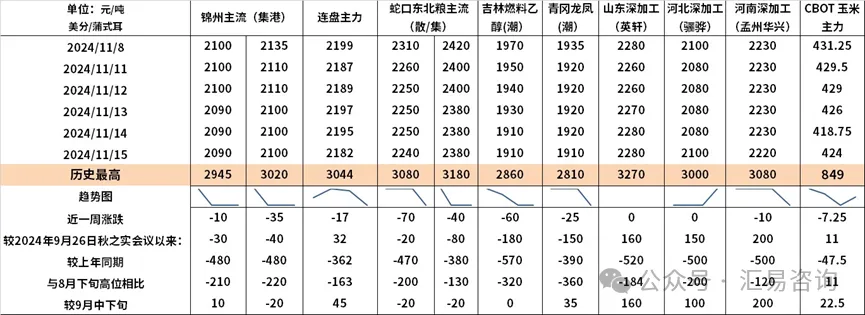 д»ҺеҪ“еүҚеӣҪеҶ…зҺүзұіеёӮеңәең°
д»ҺеҪ“еүҚеӣҪеҶ…зҺүзұіеёӮеңәең° з®Ўж¶ӣпјҡзү№жң—жҷ®еӣһеҪ’еҜ№дёӯ
з®Ўж¶ӣпјҡзү№жң—жҷ®еӣһеҪ’еҜ№дёӯ







 еҸ‘иЎЁдәҺ 2021-3-31 09:36:34
еҸ‘иЎЁдәҺ 2021-3-31 09:36:34
 жҸҗеҚҮеҚЎ
жҸҗеҚҮеҚЎ зҪ®йЎ¶еҚЎ
зҪ®йЎ¶еҚЎ
 еҰӮдҪ•жһ„е»әејҳжү¬ж•ҷиӮІе®¶зІҫзҘһзҡ„жңәеҲ¶дҪ“зі»пјҹжҠҠжҸЎеҘҪ
еҰӮдҪ•жһ„е»әејҳжү¬ж•ҷиӮІе®¶зІҫзҘһзҡ„жңәеҲ¶дҪ“зі»пјҹжҠҠжҸЎеҘҪ иҙўж”ҝйғЁпјҡжҸҗеүҚдёӢиҫҫ566дәҝе…ғпјҒ
иҙўж”ҝйғЁпјҡжҸҗеүҚдёӢиҫҫ566дәҝе…ғпјҒ зҺӢдәҡеҚҺпјҡд»Ҙжңүж•ҲжІ»зҗҶжҺЁиҝӣд№Ўжқ‘е…ЁйқўжҢҜе…ҙ
зҺӢдәҡеҚҺпјҡд»Ҙжңүж•ҲжІ»зҗҶжҺЁиҝӣд№Ўжқ‘е…ЁйқўжҢҜе…ҙ еҘҪз”ҹжҖҒдәҰжңүвҖңеҘҪд»·й’ұвҖқ зӨҫдјҡиө„жң¬йҰ–ж¬ЎеҸӮдёҺж°ҙ
еҘҪз”ҹжҖҒдәҰжңүвҖңеҘҪд»·й’ұвҖқ зӨҫдјҡиө„жң¬йҰ–ж¬ЎеҸӮдёҺж°ҙ


