马дёҠжіЁеҶҢе…ҘдјҡпјҢз»“дәӨ专家еҗҚжөҒпјҢдә«еҸ—иҙөе®ҫеҫ…йҒҮпјҢи®©дәӢдёҡз”ҹжҙ»еҸҢиөўгҖӮ
жӮЁйңҖиҰҒ зҷ»еҪ• жүҚеҸҜд»ҘдёӢиҪҪжҲ–жҹҘзңӢпјҢжІЎжңүеёҗеҸ·пјҹз«ӢеҚіжіЁеҶҢ


x
жІҲиүіпјҲеҢ—дә¬еӨ§еӯҰеӣҪ家еҸ‘еұ•з ”究йҷўж•ҷжҺҲпјү вҖңеӨ§ж•°жҚ®иҮӘеӨ§вҖқзҡ„жҸҗеҮә
вҖңеӨ§ж•°жҚ®иҮӘеӨ§пјҲBig Data HubrisпјүвҖқй—®йўҳжңҖж—©з”ұLazerзӯүеӯҰиҖ…еңЁ2014е№ҙеҸ‘ж–Үи®Ёи®әи°·жӯҢе…¬еҸёйў„жөӢзҫҺеӣҪжөҒж„ҹеҸ‘з—…зҺҮйЎ№зӣ®ж—¶жҸҗеҮәгҖӮ2008е№ҙ11жңҲпјҢи°·жӯҢе…¬еҸёеҗҜеҠЁдәҶGFTпјҲи°·жӯҢжөҒж„ҹи¶ӢеҠҝпјүйЎ№зӣ®д»Ҙйў„жөӢзҫҺеӣҪз–ҫжҺ§дёӯеҝғжҠҘе‘Ҡзҡ„жөҒж„ҹеҸ‘з—…зҺҮгҖӮ2009е№ҙпјҢGFTеӣўйҳҹеңЁгҖҠиҮӘ然гҖӢеҸ‘ж–Үз§°пјҢеҸӘйңҖеҲҶжһҗж•°еҚҒдәҝжҗңзҙўдёӯ45дёӘдёҺжөҒж„ҹзӣёе…ізҡ„е…ій”®иҜҚпјҢGFTе°ұиғҪжҜ”зҫҺеӣҪз–ҫжҺ§дёӯеҝғжҸҗеүҚдёӨе‘Ёйў„жҠҘ2007вҖ”2008еӯЈжөҒж„ҹзҡ„еҸ‘з—…зҺҮгҖӮ2014е№ҙ, LazerзӯүеӯҰиҖ…еңЁгҖҠ科еӯҰгҖӢеҸ‘ж–ҮжҢҮеҮәпјҢ2009е№ҙGFTжІЎжңүиғҪйў„жөӢеҲ°йқһеӯЈиҠӮжҖ§жөҒж„ҹA-H1N1пјӣд»Һ2011е№ҙ8жңҲејҖе§Ӣзҡ„108е‘ЁйҮҢпјҢGFTжңү100е‘Ёй«ҳдј°дәҶзҫҺеӣҪз–ҫжҺ§дёӯеҝғжҠҘе‘Ҡзҡ„жөҒж„ҹеҸ‘з—…зҺҮпјҢй«ҳдј°зЁӢеәҰиҫҫ1.5еҖҚвҖ”2еҖҚеӨҡгҖӮ
LazerзӯүеӯҰиҖ…и®ӨдёәпјҢвҖңеӨ§ж•°жҚ®иҮӘеӨ§вҖқжҳҜиҝҷдёҖйў„жөӢй”ҷиҜҜзҡ„дё»иҰҒеҺҹеӣ д№ӢдёҖгҖӮиҝҷйҮҢпјҢе®ғжҳҜжҢҮдёҖ家жңәжһ„и®ӨдёәиҮӘе·ұжӢҘжңүзҡ„вҖңжө·йҮҸж•°жҚ®вҖқе°ұжҳҜвҖңе…ЁйҮҸж•°жҚ®вҖқпјҢеӣ жӯӨеңЁеҲҶжһҗе®ҡдҪҚдёҠи®ӨдёәеӨ§ж•°жҚ®жҜ”科еӯҰжҠҪж ·еҹәзЎҖдёҠеҪўжҲҗзҡ„дј з»ҹж•°жҚ®жӣҙдјҳи¶ҠгҖӮиҷҪ然иҝ‘е№ҙжқҘеӨ§ж•°жҚ®дёҺеҗ„зұ»дј з»ҹж•°жҚ®зӣёз»“еҗҲзҡ„еҲҶжһҗеҸ—еҲ°дәҶдёҖе®ҡзЁӢеәҰзҡ„йҮҚи§ҶпјҢдҪҶжҳҜеңЁе®һи·өдёӯеҚҙд»Қ然еӯҳеңЁвҖңеӨ§ж•°жҚ®иҮӘеӨ§вҖқзҺ°иұЎгҖӮ
вҖңеӨ§ж•°жҚ®иҮӘеӨ§вҖқзҡ„зҺ°е®һиЎЁзҺ°
01гҖҒеҝҪз•ҘеӨ§ж•°жҚ®еҸҜиғҪеӯҳеңЁзҡ„з»“жһ„еҸҳеҢ–
з”ұдәҺеӨ§ж•°жҚ®зӣёе…іжҠҖжңҜеңЁжҲ‘еӣҪиҝҗз”Ёзҡ„ж—¶й—ҙиҝҳжҜ”иҫғзҹӯпјҢеңЁеҜ№з»ҸжөҺе’ҢйҮ‘иһҚзӣёе…ізҡ„йў„жөӢдёӯпјҢе°ҡдёҚеӯҳеңЁеҸҜд»Ҙи·Ёи¶Ҡиҫғй•ҝз»ҸжөҺе‘Ёжңҹзҡ„еӨ§ж•°жҚ®гҖӮиҖҢеӨ§ж•°жҚ®еҲҶжһҗжүҖдҫқжҚ®зҡ„жңәеҷЁеӯҰд№ жҲ–иҖ…ж·ұеәҰеӯҰд№ жЁЎеһӢпјҢйғҪеҒҮе®ҡдәҶи®ӯз»ғж•°жҚ®зҡ„з”ҹжҲҗжңәеҲ¶е’Ңзңҹе®һж•°жҚ®зҡ„з”ҹжҲҗжңәеҲ¶жҳҜзӣёдјјзҡ„пјҢеҚідёҚеӯҳеңЁз»“жһ„жҖ§еҸҳеҢ–гҖӮиҝҷдёҖеҒҮе®ҡеңЁиҫғзҹӯж—¶й—ҙеҶ…еҸҜиғҪжҲҗз«ӢпјҢдҪҶжҳҜеҰӮжһңз»ҸжөҺеҮәзҺ°з»“жһ„жҖ§еҸҳеҢ–пјҢе°ұдјҡдә§з”ҹиҝҮеҺ»иҝҗиЎҢиүҜеҘҪзҡ„жЁЎеһӢеҝҪ然预жөӢдёҚеҮҶзҡ„зҺ°иұЎгҖӮдҫӢеҰӮпјҢеңЁз»ҸжөҺз№ҒиҚЈж—¶жңҹи®ӯз»ғеҮәзҡ„еҲӨж–ӯдёӘдәәжҳҜеҗҰдјҡйҖҫжңҹжҲ–иҖ…еҪўжҲҗдёҚиүҜиҙ·ж¬ҫзҡ„йЈҺжҺ§жЁЎеһӢпјҢеңЁз»ҸжөҺдёӢиЎҢж—¶жңҹе°ұеҸҜиғҪдҪҺдј°е®һйҷ…дёҚиүҜзҺҮзҡ„еҸ‘з”ҹпјҢеҜјиҮҙеҜ№йЈҺйҷ©зҡ„йў„еӨҮдёҚи¶ігҖӮ
02гҖҒеҝҪз•ҘеӨ§ж•°жҚ®еҸҜиғҪдёҚе…·еӨҮд»ЈиЎЁжҖ§
дёҚеҗҢе№іеҸ°жҲ–иҖ…жңәжһ„жңүе…¶зү№е®ҡзҡ„ж¶Ҳиҙ№дәәзҫӨгҖӮеӣ жӯӨеҲҶжһҗз»“и®әеҸҜиғҪд»…йҖӮз”ЁдәҺиҜҘе№іеҸ°жҲ–жңәжһ„гҖҒжңӘеҝ…еҸҜд»Ҙд»ЈиЎЁе…ЁеӣҪжҲ–жҹҗдёҖең°еҢәзҡ„зҠ¶еҶөгҖӮ然иҖҢдёҖдёӘеёёи§ҒзҺ°иұЎжҳҜпјҢзҪ‘з»ңж–°й—»е№іеҸ°йҮҮз”ЁиҜҘе№іеҸ°зҡ„жөҸи§ҲеӨ§ж•°жҚ®жқҘеҲҶжһҗеҗ„зңҒдәәзҫӨзҡ„йҳ…иҜ»д№ жғҜе·®ејӮпјҢйӨҗйҘ®иЎҢдёҡе№іеҸ°йҮҮз”ЁеңЁиҝҷдёӘе№іеҸ°дёҠдә§з”ҹзҡ„еӨ§ж•°жҚ®жқҘеҲҶжһҗдёҚеҗҢеҹҺеёӮзҡ„еӨңй—ҙз»ҸжөҺпјҢжҠҘе‘Ҡз»“жһңеҫҖеҫҖзӣҙжҺҘйҳҗиҝ°дёәвҖңXXзңҒзҡ„иҜ»иҖ…жӣҙеҒҸеҘҪеЁұд№җзұ»ж–°й—»вҖқвҖңXXеёӮеӨңй—ҙз»ҸжөҺзү№еҫҒвҖқзӯүгҖӮеҪ“зӣёе…ідјҒдёҡе°Ҷиҝҷзұ»жҠҘе‘ҠжҠҘйҖҒжңүе…ійғЁй—Ёж—¶пјҢи§ЈиҜ»иҝҷзұ»жҠҘе‘Ҡдёӯзҡ„и¶ӢеҠҝе’Ңзү№еҫҒе°ұйңҖиҰҒжіЁж„ҸпјҢиҝҷзұ»жҠҘе‘Ҡзҡ„еҲҶжһҗеҢ…еҗ«дәҶдёӨйғЁеҲҶеӣ зҙ пјҡдёҖжҳҜе…ЁеӣҪжҲ–иҖ…жҹҗдёҖең°еҢәдәәж°‘йҳ…иҜ»жҲ–иҖ…йӨҗйҘ®зҡ„зңҹе®һзү№еҫҒе’Ңи¶ӢеҠҝпјӣдәҢжҳҜиҜҘе№іеҸ°иҮӘиә«йңҖжұӮжүҖеёҰжқҘзҡ„з»“жһ„жҖ§еҸҳеҢ–гҖӮеҰӮжһңеҝҪз•ҘдәҶ第дәҢз§Қеӣ зҙ пјҢе°ұеҸҜиғҪдјҡеҜјиҮҙеҜ№дёҖдәӣиЎҢдёҡеҸ‘еұ•зҠ¶еҶөдә§з”ҹиҜҜеҲӨгҖӮ
еңЁеӨ§ж•°жҚ®дҫӣз»ҷеұӮйқўеӯҳеңЁз®—жі•и°ғж•ҙй—®йўҳгҖӮд»Ҙи°·жӯҢе…¬еҸёдёәдҫӢпјҢе…¶е•ҶдёҡжЁЎејҸзҡ„дё»иҰҒзӣ®ж ҮжҳҜжӣҙеҝ«йҖҹең°дёәдҪҝз”ЁиҖ…жҸҗдҫӣеҮҶзЎ®дҝЎжҒҜгҖӮдёәдәҶе®һзҺ°иҝҷдёҖзӣ®ж ҮпјҢж•°жҚ®з§‘еӯҰ家дёҺе·ҘзЁӢеёҲдёҚж–ӯжӣҙж–°и°·жӯҢжҗңзҙўзҡ„з®—жі•пјҢи®©дҪҝз”ЁиҖ…еҸҜд»ҘйҖҡиҝҮеҗҺз»ӯи°·жӯҢжҺЁиҚҗзҡ„зӣёе…іиҜҚеҝ«жҚ·ең°иҺ·еҫ—жңүз”ЁдҝЎжҒҜгҖӮиҝҷдёҖжЁЎејҸеңЁе•ҶдёҡдёҠйқһеёёеҝ…иҰҒпјҢдҪҶеңЁж•°жҚ®з”ҹжҲҗжңәеҲ¶ж–№йқўеҚҙеҜјиҮҙдёҚеҗҢж—¶жңҹзҡ„ж•°жҚ®д№Ӣй—ҙеҸҜиғҪдёҚеҸҜжҜ”гҖӮеҰӮжһңж•°жҚ®еҲҶжһҗеӣўйҳҹе’Ңз®—жі•жј”еҢ–еӣўйҳҹжІЎжңүе……еҲҶжІҹйҖҡпјҢж•°жҚ®еҲҶжһҗеӣўйҳҹдёҚжё…жҘҡзҹҘжҷ“з®—жі•и°ғж•ҙеҜ№ж•°жҚ®з”ҹжҲҗжңәеҲ¶зҡ„еҪұе“ҚпјҢе°ұдјҡиҜҜе°Ҷж•°жҚ®еҸҳеҠЁи§ЈиҜ»дёәеёӮеңәзңҹе®һеҸҳеҠЁиҖҢеёҰжқҘиҜҜеҲӨгҖӮ
ж•°жҚ®з”ҹжҲҗеҠЁжңәеҸҜиғҪдјҡйҡҸж—¶й—ҙжҺЁз§»иҖҢеҸ‘з”ҹеҸҳеҢ–гҖӮеӨ§ж•°жҚ®дёҚеҶҚжҳҜз”ұж”ҝеәңзү№е®ҡйғЁй—ЁжҲ–иҖ…зү№е®ҡжңәжһ„дё»жҢҒ收йӣҶпјҢиҖҢжҳҜз»ҸжөҺзӨҫдјҡдё»дҪ“иҝҗиҗҘдёӯдә§з”ҹзҡ„еүҜдә§е“ҒпјҢеӣ жӯӨеӨ§ж•°жҚ®зҡ„йҮҮйӣҶе°ұе’ҢиҜҘдё»дҪ“иҮӘиә«зҡ„еҲ©зӣҠиҜүжұӮеҜҶеҲҮзӣёе…ігҖӮд»ҘзӨҫдәӨеӘ’дҪ“еӨ§ж•°жҚ®дёәдҫӢпјҢеҜ№иҝҷзұ»ж•°жҚ®зҡ„еҲҶжһҗеёёеёёе»әз«ӢеңЁдёҖдёӘеҒҮе®ҡд№ӢдёҠпјҢеҚідәә们еңЁзӨҫдәӨеӘ’дҪ“еҲҶдә«зҡ„дҝЎжҒҜйғҪжҳҜзңҹе®һзҡ„гҖҒиҮӘеҸ‘зҡ„гҖҒдёҚдјҡиў«иҮӘе·ұеҸ‘иЁҖзҡ„е№іеҸ°жүҖж“ҚзәөгҖӮеҰӮжһңиҜҙиҝҮеҺ»зӨҫдәӨеӘ’дҪ“дјҒдёҡи®°еҪ•дҝқеӯҳе®ўжҲ·дҝЎжҒҜзҡ„еҠЁжңәд»…д»…жҳҜжң¬е…¬еҸёеҸ‘еұ•дёҡеҠЎйңҖиҰҒпјҢз®—жі•жј”еҢ–д№ҹеҚ•зәҜжҳҜдёәдәҶжӣҙеҘҪең°жңҚеҠЎж¶Ҳиҙ№иҖ…пјҢйӮЈд№ҲйҡҸзқҖеӨ§ж•°жҚ®ж—¶д»Јзҡ„жҺЁиҝӣпјҢвҖңж•°жҚ®дёәзҺӢвҖқзҡ„зү№еҫҒе°ұдјҡи¶ҠжқҘи¶ҠжҳҺжҳҫпјҢзӨҫдәӨеӘ’дҪ“дјҡзңӢеҲ°йҷӨдәҶеҸҜд»Ҙз»ҷдҪҝз”ЁиҖ…жӨҚе…Ҙе№ҝе‘Ҡд»ҘеўһеҠ 收е…Ҙд№ӢеӨ–пјҢиҝҳеҸҜд»Ҙж“Қзәөж•°жҚ®зҡ„з”ҹжҲҗдёҺжҠҘе‘Ҡд»ҘеўһеҠ иҮӘиә«зҡ„еҪұе“ҚеҠӣгҖӮ
03гҖҒжҠҖжңҜе”ҜдёҠпјҢеҝҪз•ҘеӨ§ж•°жҚ®еҲҶжһҗзҡ„зҺ°е®һзҺҜеўғ
еӨ§ж•°жҚ®дёәжҲ‘еӣҪеҸ‘еұ•ж–°дёҡжҖҒжҸҗдҫӣдәҶеҙӯж–°жңәйҒҮпјҢдҪҶд№ҹеӯҳеңЁдёҖе‘іејәи°ғеӨ§ж•°жҚ®зҡ„жҠҖжңҜдјҳеҠҝпјҢиҖҢеҝҪз•ҘеӨ§ж•°жҚ®жҠҖжңҜе’Ңеҗ„ең°еҢәз»ҸжөҺзӨҫдјҡеҸ‘еұ•е®һйҷ…зҠ¶еҶөзӣёз»“еҗҲж—¶еҸҜиғҪдә§з”ҹй—®йўҳзҡ„зҺ°иұЎгҖӮдҫӢеҰӮпјҢйҮ‘иһҚ科жҠҖеҸ‘еұ•иҝҮзЁӢдёӯпјҢеӨ§ж•°жҚ®еҫҒдҝЎиҺ·еҫ—дәҶй•ҝи¶іиҝӣеұ•гҖӮеҹәдәҺеӨ§ж•°жҚ®жҠҖжңҜпјҢиҪҰжҠөиҙ·жңүдәҶж–°зҡ„жү§иЎҢж–№ејҸгҖӮзӣёиҫғдәҺиҝҮеҺ»жҠөжҠјиҪҰд№ӢеҗҺиҪҰе°ұиҰҒж”ҫеҲ°еӣәе®ҡең°зӮ№дёҚиғҪ移еҠЁзҡ„е®үжҺ’пјҢзҺ°еңЁз”ұдәҺиҪҰиҫҶйғҪе®үиЈ…дәҶGPSпјҢиҙ·ж¬ҫе№іеҸ°еҸҜд»Ҙе®һж—¶зӣ‘жҺ§иҪҰиҫҶеҺ»еҗ‘пјҢеӣ жӯӨжҠөжҠјдәәеҠһе®ҢжҠөжҠјжүӢз»ӯд№ӢеҗҺд»Қ然еҸҜд»Ҙе°ҶиҪҰејҖиө°пјҢдёҖж—Ұж— жі•иҝҳж¬ҫпјҢе№іеҸ°е…¬еҸёдёҠй—ЁжӢ–иҪҰеҚіеҸҜгҖӮдҪҶжҳҜпјҢеңЁ2018е№ҙд»ҘжқҘејҖеұ•зҡ„жү«й»‘йҷӨжҒ¶дё“йЎ№ж•ҙжІ»жҙ»еҠЁдёӯпјҢеҖҹж¬ҫдәәдёҚиҝҳж¬ҫгҖҒиҖҢеҮәеҖҹж–№е№іеҸ°еӣ дёәжӢ…еҝғиў«еҪ“дҪңжҒ¶ж„ҸеӮ¬ж”¶пјҢд№ҹдёҚиғҪжҢүз…§GPSдёҠ门收иҪҰзҡ„зҺ°иұЎејҖе§ӢеҮәзҺ°гҖӮеҸҲеҰӮпјҢеӨ§ж•°жҚ®еҲҶжһҗжҠҖжңҜзҡ„еҸ‘еұ•и®©зҪ‘зәҰиҪҰжҲҗдёәдәә们ж—ҘеёёеҮәиЎҢзҡ„ж–°йҖүжӢ©гҖӮдҪҶ2019е№ҙ12жңҲUberзҡ„йҰ–д»Ҫе®үе…ЁжҠҘе‘ҠжҳҫзӨәпјҢ2018е№ҙе…ұеҸ‘з”ҹи¶…иҝҮ3000иө·жҖ§дҫөжЎҲ件пјҢиҖҢзәҪзәҰиӯҰеҜҹеұҖи®°еҪ•зҡ„ж•°жҚ®жҳҫзӨәпјҢ2018е№ҙдәӨйҖҡзі»з»ҹеҸ‘з”ҹзҡ„иҝҷзұ»жЎҲ件дёә533иө·гҖӮдёҠиҝ°дёӨдҫӢиҜҙжҳҺпјҢеҰӮжһңжІЎжңүе°ҠйҮҚйҮ‘иһҚ规еҫӢпјҲйЈҺйҷ©иҫғй«ҳзҡ„дәәеҚідҫҝеҸҜд»ҘжҠөжҠјиҪҰд№ҹдёҚи§Ғеҫ—жҳҜеҘҪзҡ„еҖҹж¬ҫдәәпјүгҖҒжІЎжңүзӣёеә”зҡ„еҸёжі•дҝқйҡңиҖҢеҚ•зәҜдҫқйқ еӨ§ж•°жҚ®еҲҶжһҗзҡ„жҠҖжңҜеҠӣйҮҸпјҢйӮЈд№ҲеңЁејҖеҸ‘ж–°дёҡжҖҒзҡ„еҗҢж—¶д№ҹеҸҜиғҪеёҰжқҘж–°йЈҺйҷ©гҖӮ
йҳІиҢғвҖңеӨ§ж•°жҚ®иҮӘеӨ§вҖқзҡ„ж”ҝзӯ–е»әи®®
еҠ еҝ«и®ўз«ӢеӨ§ж•°жҚ®йҮҮйӣҶе’ҢеҲҶжһҗж–№йқўзҡ„жі•еҫӢ法规гҖӮиҷҪ然жңүгҖҠзҪ‘з»ңе®үе…Ёжі•гҖӢгҖҒгҖҠз»ҹи®Ўжі•гҖӢзӯүжі•еҫӢ法规пјҢдҪҶзӣ®еүҚжҲ‘еӣҪеңЁдё“й—Ёй’ҲеҜ№еӨ§ж•°жҚ®йҮҮйӣҶгҖҒдҪҝз”ЁгҖҒеҲҶдә«зӯүж–№йқўзҡ„жі•еҫӢ法规иҝҳеҚҒеҲҶж¬ зјәгҖӮдҫӢеҰӮпјҢдёҖдәӣAPPеӯҳеңЁеңЁдҪҝз”ЁиҖ…дёҚзҹҘжғ…зҡ„жғ…еҶөдёӢпјҢйҮҮйӣҶе’ҢдҪҝз”ЁдёҺиҜҘAPPж— е…ізҡ„дёӘдәәдҝЎжҒҜзҡ„еҒҡжі•пјҢиҖҢиҝҷдәӣиЎҢдёәзӣ®еүҚ并没жңүжҳҺзЎ®зҡ„жі•еҫӢеұӮйқўзҡ„жғ©жҲ’жҺӘж–ҪгҖӮиҖҢ欧зӣҹзҡ„гҖҠйҖҡз”Ёж•°жҚ®дҝқжҠӨжқЎдҫӢпјҲGeneral Data Protection RegulationsпјүгҖӢгҖҒиҚ·е…°зҡ„гҖҠдёӘдәәж•°жҚ®дҝқжҠӨжі•гҖӢпјҲPersonal Data Protection ActпјҢвҖңDPAвҖқпјүйғҪжҢҮеҮәпјҢеңЁжІЎжңүжі•еҫӢдҫқжҚ®зҡ„жғ…еҶөдёӢеӨ„зҗҶдёӘдәәж•°жҚ®жҳҜдёҚиў«е…Ғи®ёзҡ„гҖӮ
жҸҗй«ҳеӨ§ж•°жҚ®дҪҝз”Ёзҡ„йҖҸжҳҺеәҰпјҢеҠ ејәеҜ№еӨ§ж•°жҚ®иҙЁйҮҸзҡ„иҜ„дј°гҖӮз”ұдәҺеӨ§ж•°жҚ®дҪ“йҮҸеӨ§гҖҒеҲҶжһҗйҡҫеәҰй«ҳзӯүй—®йўҳпјҢдёҚд»…еӨ§ж•°жҚ®зҡ„收йӣҶиҝҮзЁӢеҸҜиғҪжҳҜвҖңй»‘з®ұвҖқпјҢеӨ§ж•°жҚ®еҲҶжһҗд№ҹеҸҜиғҪеӯҳеңЁиҝҮзЁӢдёҚйҖҸжҳҺзҡ„зҺ°иұЎгҖӮеңЁGFTжЎҲдҫӢдёӯпјҢLazerзӯүдәәжҢҮеҮәпјҢи°·жӯҢе…¬еҸёд»ҺжңӘжҳҺзЎ®з”ЁдәҺжҗңзҙўзҡ„45дёӘе…ій”®иҜҚжҳҜе“ӘдәӣпјӣиҷҪ然谷жӯҢе·ҘзЁӢеёҲеңЁ2013е№ҙи°ғж•ҙдәҶж•°жҚ®з®—жі•пјҢдҪҶжҳҜи°·жӯҢ并没жңүе…¬ејҖзӣёеә”ж•°жҚ®пјҢд№ҹжІЎжңүи§ЈйҮҠиҝҷзұ»ж•°жҚ®жҳҜеҰӮдҪ•жҗңйӣҶзҡ„гҖӮеҗҢж—¶пјҢдёҺйҖҸжҳҺеәҰзӣёе…ізҡ„жҳҜеӨ§ж•°жҚ®еҲҶжһҗз»“жһңзҡ„еҸҜеӨҚеҲ¶жҖ§й—®йўҳгҖӮз”ұдәҺи°·жӯҢд»ҘеӨ–зҡ„з ”з©¶дәәе‘ҳйҡҫд»ҘиҺ·еҫ—GFTдҪҝз”Ёзҡ„ж•°жҚ®пјҢеӣ жӯӨе°ұйҡҫд»ҘеӨҚеҲ¶гҖҒиҜ„дј°йҮҮз”ЁиҜҘж•°жҚ®еҲҶжһҗз»“жһңзҡ„еҸҜйқ жҖ§гҖӮиҝҷз§Қж•°жҚ®з”ҹжҲҗе’ҢеҲҶжһҗзҡ„вҖңй»‘з®ұвҖқзү№еҫҒпјҢе®№жҳ“жҲҗдёәдјҒдёҡжҲ–иҖ…жңәжһ„ж“Қзәөж•°жҚ®з”ҹжҲҗиҝҮзЁӢе’Ңз ”з©¶жҠҘе‘Ҡз»“жһңзҡ„жё©еәҠгҖӮе”ҜжңүйҖҡиҝҮжҺЁеҠЁеӨ§ж•°жҚ®еҲҶжһҗзҡ„йҖҸжҳҺеҢ–пјҢжүҚиғҪеңЁеӨ§ж•°жҚ®дә§дёҡеҸ‘еұ•д№ӢеҲқпјҢе»әз«ӢеҒҘеә·зҡ„ж•°жҚ®ж–ҮеҢ–гҖӮ
еңЁдҝқжҠӨйҡҗз§Ғе’Ңж•°жҚ®е®үе…Ёзҡ„еҹәзЎҖдёҠпјҢеҠ еӨ§дј з»ҹж•°жҚ®е’ҢеӨ§ж•°жҚ®зҡ„ејҖж”ҫе…ұдә«еҠӣеәҰгҖӮеӨ§ж•°жҚ®еҲҶжһҗдёӯпјҢеҚ•дёӘдјҒдёҡе…·жңүйў—зІ’еәҰиҫғй«ҳдҪҶжҳҜд»ЈиЎЁжҖ§дёҚи¶ізҡ„ж•°жҚ® вҖңдҝЎжҒҜеӯӨеІӣвҖқй—®йўҳпјҢйңҖиҰҒйҖҡиҝҮдёҚеҗҢиЎҢдёҡгҖҒдёҚеҗҢзұ»еһӢеӨ§ж•°жҚ®е’Ңдј з»ҹж•°жҚ®д№Ӣй—ҙеҠ ејәејҖж”ҫе’Ңе…ұдә«жқҘи§ЈеҶігҖӮзӣ®еүҚпјҢдёҖдәӣеӨ§ж•°жҚ®дјҒдёҡе·Із»ҸејҖе§ӢзқҖжүӢжҺЁеҠЁж•°жҚ®ејҖж”ҫе№іеҸ°ж–№йқўзҡ„е·ҘдҪңпјҢиҝҷжҳҜиҜҘж–№еҗ‘еҸҜе–ңзҡ„еҸҳеҢ–гҖӮеҗҢж—¶иҰҒзңӢеҲ°пјҢеңЁдј з»ҹж•°жҚ®зҡ„收йӣҶе’ҢејҖж”ҫиҝҗз”Ёж–№йқўпјҢжҲ‘еӣҪиҝҳжңүеҫҲеӨ§жҸҗеҚҮз©әй—ҙгҖӮеҸӘжңүеңЁеҜ№ж¶үеҸҠжҲ‘еӣҪеҹәжң¬еӣҪжғ…зҡ„дј з»ҹж•°жҚ®иҝӣиЎҢе……еҲҶеӯҰд№ з ”з©¶д№ӢеҗҺпјҢжҲ‘еӣҪеӯҰз•Ңе’Ңдёҡз•ҢжүҚиғҪеҜ№з»ҸжөҺж”ҝжІ»зӨҫдјҡж–ҮеҢ–зӯүйўҶеҹҹзҡ„еҹәжң¬зҠ¶еҶөжңүиҫғжё…жҷ°зҡ„жҠҠжҸЎгҖӮиҖҢиҝҷзұ»зҡ„жҠҠжҸЎпјҢжҳҜиҜ„дј°еӨ§ж•°жҚ®иҙЁйҮҸгҖҒеӨ§ж•°жҚ®еҸҜз ”з©¶й—®йўҳзҡ„е…ій”®пјҢеҜ№жҺЁиҝӣеӨ§ж•°жҚ®дә§дёҡеҒҘеә·еҸ‘еұ•жңүдёҫи¶іиҪ»йҮҚзҡ„дҪңз”ЁгҖӮ
| 
 й«ҳз‘һдёңзӯүпјҡ2025е№ҙиө„дә§
й«ҳз‘һдёңзӯүпјҡ2025е№ҙиө„дә§ еҶңдёҡж–°иҙЁз”ҹдә§еҠӣпјҡеҶ…ж¶ө
еҶңдёҡж–°иҙЁз”ҹдә§еҠӣпјҡеҶ…ж¶ө еҲҳдҝҠжқ°зӯүпјҡжһ„е»әйҖӮеә”еҶң
еҲҳдҝҠжқ°зӯүпјҡжһ„е»әйҖӮеә”еҶң 11жңҲе…Ёзҗғи°·зү©еёӮеңәдёҺиҙё
11жңҲе…Ёзҗғи°·зү©еёӮеңәдёҺиҙё з®Ўж¶ӣзӯүпјҡпјҡдәәж°‘еёҒжұҮзҺҮ
з®Ўж¶ӣзӯүпјҡпјҡдәәж°‘еёҒжұҮзҺҮ й’ҹжӯЈз”ҹпјҡеҗ‘е®ҢжҲҗйў„з®—зӣ®
й’ҹжӯЈз”ҹпјҡеҗ‘е®ҢжҲҗйў„з®—зӣ® жқҺиҝ…йӣ·пјҡжҳҺе№ҙиҙўж”ҝиөӨеӯ—
жқҺиҝ…йӣ·пјҡжҳҺе№ҙиҙўж”ҝиөӨеӯ— еј зәўе®Үпјҡжһ„е»әе…·жңүдёӯеӣҪ
еј зәўе®Үпјҡжһ„е»әе…·жңүдёӯеӣҪ ж—әеӯЈдёҚж—ә еҪ“еүҚз”ҹзҢӘеёӮ
ж—әеӯЈдёҚж—ә еҪ“еүҚз”ҹзҢӘеёӮ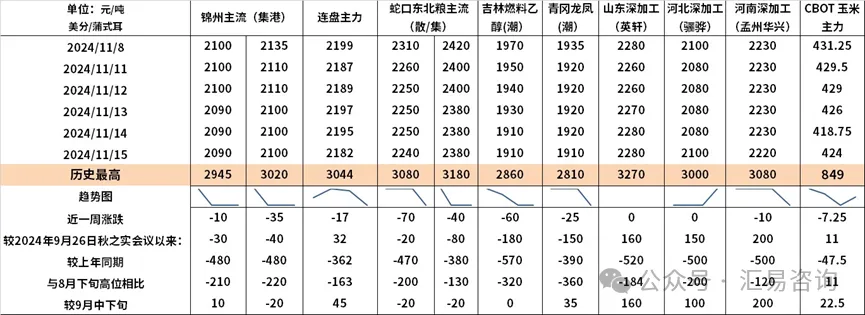 д»ҺеҪ“еүҚеӣҪеҶ…зҺүзұіеёӮеңәең°
д»ҺеҪ“еүҚеӣҪеҶ…зҺүзұіеёӮеңәең° з®Ўж¶ӣпјҡзү№жң—жҷ®еӣһеҪ’еҜ№дёӯ
з®Ўж¶ӣпјҡзү№жң—жҷ®еӣһеҪ’еҜ№дёӯ







 еҸ‘иЎЁдәҺ 2020-8-6 09:14:19
еҸ‘иЎЁдәҺ 2020-8-6 09:14:19
 жҸҗеҚҮеҚЎ
жҸҗеҚҮеҚЎ зҪ®йЎ¶еҚЎ
зҪ®йЎ¶еҚЎ
 еҰӮдҪ•жһ„е»әејҳжү¬ж•ҷиӮІе®¶зІҫзҘһзҡ„жңәеҲ¶дҪ“зі»пјҹжҠҠжҸЎеҘҪ
еҰӮдҪ•жһ„е»әејҳжү¬ж•ҷиӮІе®¶зІҫзҘһзҡ„жңәеҲ¶дҪ“зі»пјҹжҠҠжҸЎеҘҪ иҙўж”ҝйғЁпјҡжҸҗеүҚдёӢиҫҫ566дәҝе…ғпјҒ
иҙўж”ҝйғЁпјҡжҸҗеүҚдёӢиҫҫ566дәҝе…ғпјҒ зҺӢдәҡеҚҺпјҡд»Ҙжңүж•ҲжІ»зҗҶжҺЁиҝӣд№Ўжқ‘е…ЁйқўжҢҜе…ҙ
зҺӢдәҡеҚҺпјҡд»Ҙжңүж•ҲжІ»зҗҶжҺЁиҝӣд№Ўжқ‘е…ЁйқўжҢҜе…ҙ еҘҪз”ҹжҖҒдәҰжңүвҖңеҘҪд»·й’ұвҖқ зӨҫдјҡиө„жң¬йҰ–ж¬ЎеҸӮдёҺж°ҙ
еҘҪз”ҹжҖҒдәҰжңүвҖңеҘҪд»·й’ұвҖқ зӨҫдјҡиө„жң¬йҰ–ж¬ЎеҸӮдёҺж°ҙ


