马дёҠжіЁеҶҢе…ҘдјҡпјҢз»“дәӨ专家еҗҚжөҒпјҢдә«еҸ—иҙөе®ҫеҫ…йҒҮпјҢи®©дәӢдёҡз”ҹжҙ»еҸҢиөўгҖӮ
жӮЁйңҖиҰҒ зҷ»еҪ• жүҚеҸҜд»ҘдёӢиҪҪжҲ–жҹҘзңӢпјҢжІЎжңүеёҗеҸ·пјҹз«ӢеҚіжіЁеҶҢ


x
зЁӢе®һ й«ҳж¬ЈејҳпјҲе·Ҙ银еӣҪйҷ…йҰ–еёӯз»ҸжөҺеӯҰ家гҖҒи‘ЈдәӢжҖ»з»ҸзҗҶгҖҒдёӯеӣҪйҰ–еёӯз»ҸжөҺеӯҰ家и®әеқӣзҗҶдәӢпјӣе·Ҙ银еӣҪйҷ…е®Ҹи§Ӯз»ҸжөҺеҲҶжһҗеёҲпјү вҖңй•ҝйЈҺз ҙжөӘдјҡжңүж—¶пјҢзӣҙжҢӮдә‘еёҶжөҺжІ§жө·гҖӮвҖқеңЁдёҠдёҖзҜҮжҠҘе‘ҠгҖҠзӘҒеӣҙд»·еҖјй“ҫпјҢеҸ‘еҠӣ硬科жҠҖгҖӢдёӯпјҢжҲ‘们йҮҮз”ЁжңәеҷЁеӯҰд№ иҒҡеҗҲпјҲClusteringпјүеҲҶзұ»пјҲClassificationпјүз ”з©¶пјҢеңЁе…Ёзҗғ5228з§Қдә§е“Ғзұ»еҲ«дёӯзі»з»ҹжҖ§зҡ„иҜҶеҲ«дәҶеҪ“еүҚдёӯеӣҪй«ҳеәҰиҝӣеҸЈдҫқиө–зҡ„88з§ҚвҖңеҚЎи„–еӯҗвҖқе…ій”®дә§е“ҒгҖӮиҖҢдёәдәҶзӘҒз ҙиҘҝж–№еҜ№дёӯеӣҪеңЁе…ій”®жҠҖжңҜдёҠзҡ„еҲ¶иЈҒпјҢжң¬зҜҮжҠҘе‘ҠеҹәдәҺMITз»ҸжөҺеӯҰ家AcemogluпјҲ2002пјүжҸҗеҮәзҡ„еҒҸеҗ‘жҖ§жҠҖжңҜиҝӣжӯҘзҗҶи®әпјҢз»“еҗҲиҝ‘жңҹжҲ‘们еҜ№е…ЁзҗғеҸҠеӣҪеҶ…йЎ¶зә§еӯҰжңҜжңәжһ„еҸҠ科жҠҖдә’иҒ”зҪ‘е…¬еҸёе…ұи®Ў20дҪҚдәәе·ҘжҷәиғҪ科еӯҰ家пјҢз®—жі•е·ҘзЁӢеёҲе’Ңж•°жҚ®еҲҶжһҗеёҲзҡ„и°ғз ”еҲҶжһҗпјҢеҸ‘зҺ°дәҶеҪ“еүҚеҸ‘иҫҫеӣҪ家еҜ№дёӯеӣҪеңЁдёӯй«ҳз«Ҝд»·еҖјй“ҫдёҠзҡ„еҲ¶иЈҒдё»иҰҒйӣҶдёӯеңЁд»ҘиҠҜзүҮпјҢе…үеҲ»жңәе’ҢеҚҠеҜјдҪ“дёәд»ЈиЎЁзҡ„硬件жҠҖжңҜдёҠгҖӮиҖҢзӣёжҜ”硬件пјҢдёӯеӣҪеңЁиҪҜ件方йқўзҡ„иҮӘдё»з ”еҸ‘е’Ңиҝӯд»ЈйҖҹеәҰиҝ‘е№ҙжқҘиҝӣжӯҘжҳҺжҳҫгҖӮеӣ жӯӨпјҢжҲ‘们е»әи®®дёӯеӣҪеҸҜйҖҡиҝҮиҮӘиә«еёӮеңәпјҢиө„жң¬дёҺж•°жҚ®иҰҒзҙ дјҳеҠҝпјҢйӣҶдёӯзӘҒз ҙйғЁеҲҶвҖңеҚЎи„–еӯҗвҖқзҡ„е…ій”®иҪҜ件е’Ңз®—жі•жҠҖжңҜгҖӮе…·дҪ“жқҘиҜҙпјҢдёӯеӣҪеҸҜеҲ©з”ЁеҜ№иҪҜ件дёҺз®—жі•зҡ„еҲӣж–°еә”з”ЁжҢҒз»ӯејәеҢ–зҺ°жңүзҡ„7еӨ§дјҳеҠҝдә§дёҡй“ҫгҖӮеңЁзЁіеӣәзҺ°жңүд»·еҖјй“ҫз«һдәүдјҳеҠҝзҡ„еҹәзЎҖдёҠпјҢеӣҙз»•дёҖдәӣж•°жҚ®ж•Ҹж„ҹеәҰиҫғдҪҺдё”еҸҜиҙёжҳ“еәҰиҫғй«ҳзҡ„иЎҢдёҡпјҲеҰӮе…үеӯҰеҷЁд»¶пјҢеҢ–еӯҰпјҢжңәз”өжҺ§еҲ¶зӯүпјүпјҢдёҚж–ӯжҸҗеҚҮдёӯеӣҪиҪҜ件жҠҖжңҜдёҺиҘҝж–№й«ҳз«Ҝ硬件жҠҖжңҜзӣёдә’й—ҙзҡ„дҫқиө–жҖ§пјҢжңҖз»Ҳеё®еҠ©дёӯеӣҪйЎәеҲ©иҝҲе…Ҙе…Ёзҗғдёӯй«ҳз«Ҝд»·еҖјй“ҫгҖӮ
з ҙеұҖд№Ӣжңәпјҡж•°жҚ®еҜҶйӣҶеһӢдә§дёҡзҡ„еҙӣиө·
еӣһйЎҫдәәзұ»еҺҶеҸІдёҠзҡ„з»ҸжөҺеўһй•ҝеҸҳеҢ–пјҢдёңиҘҝж–№дё–з•ҢзңҹжӯЈеҮәзҺ°е·ЁеӨ§з»ҸжөҺеўһй•ҝе·®и·қзҡ„ж—¶й—ҙе°ұжҳҜд»Һ19дё–зәӘе·Ҙдёҡйқ©е‘ҪеҲқејҖе§ӢгҖӮеӣҙз»•иҝҷз§Қе·®ејӮпјҢдёҖеӨ§жү№з»ҸжөҺеӯҰ家ејҖе§ӢиҜ•еӣҫи§ЈйҮҠз»ҸжөҺеўһй•ҝзҡ„жәҗжіүеҲ°еә•жҳҜд»Җд№ҲгҖӮеҸӨе…ёеўһй•ҝзҗҶи®әи®ӨдёәеҠіеҠЁе’Ңиө„жң¬иҰҒзҙ жҳҜз»ҸжөҺеўһй•ҝзҡ„ж ёеҝғеҠЁеҠӣпјҲAdam SmithпјҢ 1776пјүгҖӮиҖҢж–°еҸӨе…ёз»ҸжөҺеӯҰ家еңЁжӯӨеҹәзЎҖдёҠиҝӣдёҖжӯҘзәіе…ҘдәҶе…ЁиҰҒзҙ жҰӮеҝөе°ҶжҠҖжңҜи§ҶдёәеӨ–з”ҹеҸҳйҮҸи§ЈйҮҠз»ҸжөҺеўһй•ҝпјҲSolow, 1956пјҢSwan, 1956пјүгҖӮиҖҢд»Һ20дё–зәӘ80е№ҙд»ЈејҖе§ӢпјҢ Lucas пјҲ1990пјү е’Ң RomerпјҲ1986пјүзӯүдәәиҜ•еӣҫжҠҠжҠҖжңҜиҝӣжӯҘеҶ…з”ҹеҢ–并解йҮҠдәҶз»ҸжөҺеўһй•ҝзҡ„жәҗжіүжқҘиҮӘжҳҜзҹҘиҜҶзҡ„еҲҶдә«е’Ңз§ҜзҙҜгҖӮиҝ‘10е№ҙжқҘпјҢйҡҸзқҖд»ҘеӨ§ж•°жҚ®пјҢдә‘и®Ўз®—е’Ңдәәе·ҘжҷәиғҪдёәд»ЈиЎЁзҡ„ж–°дёҖд»ЈдҝЎжҒҜжҠҖжңҜзҡ„еҸ‘еұ•пјҢJones е’ҢTonetti пјҲ2020пјүз ”з©¶дәҶж•°жҚ®еңЁз”ҹдә§иҝҮзЁӢдёӯзҡ„еҹәжң¬жЁЎејҸ并е®ҡд№үдәҶж•°жҚ®дҪңдёәз”ҹдә§иҰҒзҙ еҜ№з»ҸжөҺеўһй•ҝзҡ„дҪңз”ЁгҖӮе°Ҫз®Ўж•°жҚ®дҪңдёәдҝЎжҒҜпјҢе…¶жң¬иә«ж— жі•иў«зӣҙжҺҘеә”з”ЁдәҺз”ҹдә§пјҢдҪҶйҖҡиҝҮеҲҶжһҗе’Ңйў„жөӢж•°жҚ®пјҲдҝЎжҒҜпјүжҢҮеҜјз»ҸжөҺзү©е“Ғзҡ„з”ҹдә§дёҺеә”з”ЁпјҢе°Ҷжҳҫи‘—йҷҚдҪҺз»ҸжөҺзү©е“Ғзҡ„дәӨжҳ“жҲҗжң¬пјҢд»ҺиҖҢжҸҗй«ҳеҠіеҠЁз”ҹдә§зҺҮгҖӮ
еҒҸеҗ‘жҖ§жҠҖжңҜиҝӣжӯҘзҗҶи®әпјҲAcemogluпјҢ2002пјүжҢҮеҮәдәҶеҪ“жҠҖжңҜеҲӣж–°дҪҝжҹҗз”ҹдә§иҰҒзҙ иҫ№йҷ…дә§еҮәзӣёеҜ№е…¶д»–з”ҹдә§иҰҒзҙ жҳҫи‘—еўһй•ҝж—¶пјҢжҠҖжңҜе°ұдјҡвҖңйқ’зқҗвҖқпјҲеҒҸеҗ‘пјүиҜҘиҰҒзҙ пјҲеӣҫ1пјүгҖӮеҗҢж—¶пјҢиҜҘиҰҒзҙ зҡ„иҫ№йҷ…дә§еҮәе’Ң规模жҠҘй…¬е°Ҷе‘ҲзҺ°йҖ’еўһзү№еҫҒгҖӮз»“еҗҲдёӯеӣҪз»ҸжөҺеўһй•ҝзҡ„е®һйҷ…жғ…еҶөпјҢдҫқйқ дј з»ҹз”ҹдә§иҰҒзҙ жҠ•е…ҘжӢүеҠЁдёӯеӣҪз»ҸжөҺеўһй•ҝзҡ„жҪңеҠӣи¶ҠжқҘи¶Ҡе°ҸпјҢж— и®әжҳҜеҠіеҠЁиҝҳжҳҜиө„жң¬иҰҒзҙ зҡ„иҫ№йҷ…дә§еҮәиҝ‘е№ҙжқҘеқҮе‘ҲзҺ°жҳҫи‘—йҖ’еҮҸзү№еҫҒгҖӮзӣёеҸҚпјҢд»Ҙж•°жҚ®дёәд»ЈиЎЁзҡ„ж–°з”ҹдә§иҰҒзҙ иҝ‘е№ҙжқҘе‘ҲзҺ°еҮәиҫ№йҷ…дә§еҮәйҖ’еўһзҡ„зү№еҫҒгҖӮиҝҷжҳҜеӣ дёәдҝЎжҒҜж—¶д»ЈдёӢж–°дёҖд»ЈжҠҖжңҜеҲӣж–°пјҲжҜ”еҰӮдә‘и®Ўз®—пјҢеӨ§ж•°жҚ®пјҢдәәе·ҘжҷәиғҪпјҢеҢәеқ—й“ҫзӯүпјүеҮ д№ҺйғҪжҳҜеӣҙз»•ж•°жҚ®иҰҒзҙ з”ҹдә§е’ҢеҸ‘еұ•зҡ„пјҢжӯЈеҰӮеҒҸеҗ‘жҖ§жҠҖжңҜиҝӣжӯҘзҗҶи®әзҡ„ж ёеҝғи§ӮзӮ№пјҢжҠҖжңҜеҲӣж–°еҒҸеҗ‘ж•°жҚ®иҰҒзҙ д»ҺиҖҢеёҰеҠЁеёӮеңәиө„жәҗйӣҶдёӯжөҒе…Ҙж•°еӯ—дә§дёҡпјҢжңҖз»ҲеҜјиҮҙж•°еӯ—еҜҶйӣҶеһӢдә§дёҡ规模жҠҘй…¬жҳҫи‘—йҖ’еўһгҖӮж №жҚ®жҲ‘们зҡ„йў„жөӢпјҢ2025е№ҙдёӯеӣҪжүҖжӢҘжңүзҡ„ж•°жҚ®и§„жЁЎе°ҶеҚ дё–з•Ңж•°жҚ®еңҲзҡ„30%пјҢиҝҷж„Ҹе‘ізқҖдёӯеӣҪе°ҶжҲҗдёәжӢҘжңүж•°жҚ®и§„жЁЎе…Ёзҗғ第дёҖзҡ„з»ҸжөҺдҪ“гҖӮеәһеӨ§зҡ„ж•°жҚ®и§„жЁЎе°ҶиҝӣдёҖжӯҘж”ҜжҢҒдёӯеӣҪеҸ‘еұ•ж•°жҚ®еҜҶйӣҶеһӢдә§дёҡд»Ҙж”ҜжҢҒдёӯеӣҪз»ҸжөҺеўһй•ҝгҖӮ

ж•°жҚ®дә§дёҡзҡ„ж ёеҝғз«һдәүеҠӣпјҡиҪҜ件е’Ңз®—жі•
е°Ҫз®ЎдёӯеӣҪж•°жҚ®и§„жЁЎжӯЈд»ҘжғҠдәәзҡ„йҖҹеәҰжҢҒз»ӯжү©еј пјҢдҪҶеҰӮдҪ•й«ҳж•Ҳзҡ„дҪҝз”Ёж•°жҚ®жқҘжҢҮеҜјз»ҸжөҺдә§е“ҒжңҚеҠЎеҲӣж–°жҳҜж•°жҚ®еҜҶйӣҶеһӢдә§дёҡеҗ‘й«ҳиҙЁйҮҸж–№еҗ‘еҸ‘еұ•зҡ„е…ій”®пјҢд№ҹжҳҜдёӯеӣҪз»ҸжөҺжҢҒз»ӯеўһй•ҝзҡ„жәҗжіүгҖӮжҲ‘们и®ӨдёәпјҢзңҹжӯЈеҜ№ж•°жҚ®еҜҶйӣҶеһӢдә§дёҡжӢҘжңүз»қеҜ№жҺ§еҲ¶жқғдёҚд»…д»…еҸ–еҶідәҺж•°жҚ®и§„жЁЎжӣҙеҸ–еҶідәҺж ёеҝғз®—жі•е’ҢиҪҜ件系з»ҹгҖӮ
еҹәдәҺжҲ‘д»¬з ”з©¶пјҢй•ҝжңҹд»ҘжқҘпјҢдёӯеӣҪеңЁиҪҜ件дёҺж ёеҝғз®—жі•дёҠж•ҙдҪ“дҫқж—§еӨ„дәҺиў«иҘҝж–№еӣҪ家вҖңеҚЎи„–еӯҗвҖқзҡ„зҠ¶жҖҒгҖӮжҜ”еҰӮпјҢеңЁж ёеҝғе·ҘдёҡиҪҜ件йўҶеҹҹпјҢеӣҪдә§EDAпјҲз”өеӯҗи®ҫи®ЎиҮӘеҠЁеҢ–пјүдёҺеҸ‘иҫҫеӣҪ家EDAе·Ҙе…·зӣёжҜ”пјҢеңЁжҖ§иғҪдёҠпјҲеҰӮе·Ҙе…·е®Ңж•ҙжҖ§пјҢзЁіе®ҡжҖ§пјҢе·Ҙиүәи®ҫи®Ўзӯүпјүд»ҚеӯҳеңЁд»Јйҷ…е·®и·қгҖӮеңЁж“ҚдҪңзі»з»ҹдёҠпјҢз»қеӨ§йғЁеҲҶжүӢжңәе’ҢдёӘдәәз”өи„‘дҫқж—§иў«3家зҫҺеӣҪе…¬еҸёпјҲи°·жӯҢпјҢиӢ№жһңпјҢеҫ®иҪҜпјүжүҖеһ„ж–ӯгҖӮеңЁж ёеҝғз®—жі•ж–№йқўпјҢдёӯеӣҪеӣҪдә§зҡ„й«ҳз«ҜжңәеҷЁдәәеңЁзЁіе®ҡжҖ§е’Ңжҳ“з”ЁжҖ§дёҠд»ҚдёҺж—Ҙжң¬пјҢзҫҺеӣҪпјҢеҫ·еӣҪе’Ңз‘һеЈ«зӯүеӣҪ家еӯҳеңЁе·®и·қ, еҸҚжҳ дәҶдёӯеӣҪеңЁдёӯй«ҳз«ҜеҲ¶йҖ дёҡдёҠд»ҚжңӘиғҪжҺҢжҸЎзӣёеҢ№й…Қзҡ„ж ёеҝғз®—жі•гҖӮ
然иҖҢпјҢеҹәдәҺжҲ‘们еҜ№е…Ёзҗғе’ҢдёӯеӣҪйЎ¶зә§й«ҳж ЎеҸҠ科жҠҖдә’иҒ”зҪ‘е…¬еҸё20дҪҚдәәе·ҘжҷәиғҪ科еӯҰ家е’Ңе·ҘзЁӢеёҲзҡ„жңҖж–°и°ғз ”жғ…еҶөжқҘзңӢпјҲиҜҰи§Ғйҷ„еҪ•иЎЁ1пјүпјҢзӣёжҜ”еҪ“еүҚвҖңеҚЎи„–еӯҗвҖқзҡ„硬件жҠҖжңҜпјҢдёӯеӣҪеңЁе…ій”®иҪҜ件йўҶеҹҹзҺҮе…ҲзӘҒз ҙзҡ„еҸҜиғҪжҖ§жӣҙй«ҳгҖӮиҝҷжҳҜеҹәдәҺзӣ®еүҚдёӯеӣҪеңЁз®—жі•е’ҢиҪҜ件йўҶеҹҹе…·еӨҮзҡ„дёүеӨ§дјҳеҠҝпјҡ
дёҖжҳҜеңЁз»ҸжөҺеұӮйқўпјҡдёӯеӣҪжӢҘжңүж•°жҚ®пјҢдәәеҠӣиө„жң¬дёҺеёӮеңәиҰҒзҙ дјҳеҠҝгҖӮжӯЈеҰӮжҲ‘们已з»ҸжҸҗеҲ°зҡ„пјҢдёӯеӣҪжӢҘжңүе…Ёдё–з•ҢжңҖеӨ§зҡ„ж•°жҚ®еңҲгҖӮеҗҢж—¶пјҢеәһеӨ§зҡ„ж¶Ҳиҙ№еёӮеңәиғҪеӨҹдёәж•°жҚ®еҜҶйӣҶдә§дёҡжҸҗдҫӣдё°еҜҢзҡ„еә”з”ЁеңәжҷҜгҖӮеҸҰеӨ–пјҢж №жҚ®2020е№ҙCSDNпјҲChinese Software Developer Networkпјүзҡ„з»ҹи®ЎпјҢеңЁдёӯеӣҪд»ҺдәӢиҪҜ件ејҖеҸ‘дёҺз®—жі•и®ҫи®Ўзӣёе…ізҡ„еӯҰз”ҹжҲ–е·ҘзЁӢеёҲе·Із»Ҹи¶…иҝҮ800дёҮпјҲж №жҚ®CSDNжҙ»и·ғз”ЁжҲ·и®Ўз®—пјүпјҢе…¶дёӯдёҖзәҝејҖеҸ‘дәәе‘ҳе·Із»Ҹи¶…иҝҮ60%гҖӮејәеӨ§зҡ„дәәеҠӣиө„жң¬дјҳеҠҝдҪҝеҫ—иҪҜ件е’Ңз®—жі•ејҖеҸ‘еҸҜд»Ҙеҝ«йҖҹзҡ„еңЁдё°еҜҢзҡ„еңәжҷҜдёӯиҝӣиЎҢиҝӯд»Јеә”з”ЁгҖӮ
дәҢжҳҜеңЁеҲ¶еәҰеұӮйқўпјҡж”ҝеәңе°ҶеӨ§еҠӣж”ҜжҢҒж•°жҚ®иҰҒзҙ еёӮеңәзҡ„еҹ№иӮІгҖӮ2020е№ҙ4жңҲдёӯе…ұдёӯеӨ®гҖҒеӣҪеҠЎйҷўе…¬еёғдәҶгҖҠе…ідәҺжһ„е»әжӣҙеҠ е®Ңе–„зҡ„иҰҒзҙ еёӮеңәеҢ–й…ҚзҪ®дҪ“еҲ¶жңәеҲ¶зҡ„ж„Ҹи§ҒгҖӢжҳҺзЎ®дәҶе°Ҷж•°жҚ®дҪңдёәж–°еһӢз”ҹдә§иҰҒзҙ гҖӮгҖҠж„Ҹи§ҒгҖӢеҗҢж—¶жҢҮеҮәдәҶжңӘжқҘдёӯеӣҪе°Ҷеӣҙз»•ж•°жҚ®иҰҒзҙ еңЁж•°жҚ®е…ұдә«пјҢж•°жҚ®иһҚеҗҲпјҢж•°жҚ®зЎ®жқғпјҢж•°жҚ®е®ҡд»·д»ҘеҸҠж•°жҚ®е®үе…ЁзӯүдёҖзі»еҲ—ж–№йқўжҺЁиЎҢж”№йқ©гҖӮжҜ«ж— з–‘й—®пјҢеӣҪ家вҖңж•°жҚ®зәўеҲ©вҖқзҡ„йҮҠж”ҫе°ҶжҺЁеҠЁж•°жҚ®еҜҶйӣҶеһӢдә§дёҡзҡ„еҸ‘еұ•еә”з”ЁпјҢиҝҷе°ҶжңүеҲ©дәҺиҪҜ件е’Ңз®—жі•зҡ„иҝӯд»ЈеҲӣж–°гҖӮ
дёүжҳҜеңЁжҠҖжңҜеұӮйқўпјҡеҸ—зӣҠдәҺејҖжәҗиҪҜ件иҝҗеҠЁпјҢй«ҳзә§з®—жі•дёҺиҪҜ件зҡ„еҸҜеҫ—жҖ§дёҚеҶҚеӣ°йҡҫгҖӮејҖжәҗиҪҜ件被жҸҸиҝ°дёәе…¶жәҗз ҒеҸҜд»Ҙиў«е…¬дј—дҪҝз”Ёзҡ„иҪҜ件пјҢ并且жӯӨиҪҜ件зҡ„дҪҝз”ЁпјҢе®Ңе–„е’ҢеҲҶдә«ж–№йқўдёҚеҸ—и®ёеҸҜиҜҒзҡ„йҷҗеҲ¶гҖӮж №жҚ®е…ЁзҗғжңҖеӨ§ејҖжәҗйЎ№зӣ®жүҳз®Ўе№іеҸ°GitHubз»ҹи®ЎпјҢеҲ°2025е№ҙе…ЁзҗғеҸӮдёҺејҖжәҗиҪҜ件зҡ„е№іеҸ°з”ЁжҲ·ж•°йҮҸе°ҶиҫҫеҲ°1дәҝз”ЁжҲ·гҖӮе…¶дёӯпјҢдёӯеӣҪејҖжәҗиҪҜ件еҸӮдёҺиҖ…зҡ„ж•°йҮҸеҸҠејҖжәҗиҙЎзҢ®еәҰеўһй•ҝе·ІжҲҗдёәе…ЁзҗғжңҖеҝ«гҖӮ
з ҙеұҖд№ӢйҒ“пјҡеҠ еҝ«иҪҜ件дёҺз®—жі•еңЁдёӯеӣҪд»·еҖјй“ҫдёҠзҡ„еә”з”ЁдёҺеҲӣж–°
жӯЈеҰӮдёҠиҝ°еҲҶжһҗпјҢжҲ‘们и®ӨдёәдёӯеӣҪжңүиғҪеҠӣйҖҡиҝҮиҮӘиә«еёӮеңәпјҢдәәеҠӣиө„жң¬дёҺж•°жҚ®иҰҒзҙ дјҳеҠҝпјҢйӣҶдёӯзӘҒз ҙйғЁеҲҶвҖңеҚЎи„–еӯҗвҖқзҡ„е…ій”®иҪҜ件е’Ңз®—жі•жҠҖжңҜгҖӮиҝӣдёҖжӯҘпјҢеҲ©з”ЁиҪҜ件дёҺз®—жі•зҡ„еҝ«йҖҹиҝӯд»Је’ҢжҢҒз»ӯеҲӣж–°ејәеҢ–дёӯеӣҪзҺ°жңүзҡ„7еӨ§дјҳеҠҝдә§дёҡй“ҫ пјҲеӣҫ2пјүгҖӮеңЁзЁіеӣәзҺ°жңүд»·еҖјй“ҫзҡ„з«һдәүдјҳеҠҝеҹәзЎҖдёҠпјҢеӣҙз»•дёҖдәӣж•°жҚ®ж•Ҹж„ҹеәҰиҫғдҪҺдё”еҸҜиҙёжҳ“еәҰиҫғй«ҳзҡ„иЎҢдёҡпјҢдёҚж–ӯжҸҗеҚҮдёӯеӣҪиҪҜ件жҠҖжңҜдёҺиҘҝж–№й«ҳз«Ҝ硬件жҠҖжңҜзӣёдә’й—ҙзҡ„дҫқиө–жҖ§пјҢжңҖз»Ҳеё®еҠ©дёӯеӣҪйЎәеҲ©иҝҲе…Ҙе…Ёзҗғдёӯй«ҳз«Ҝд»·еҖјй“ҫгҖӮ


йҰ–е…ҲпјҢеҹәдәҺжҲ‘们еҜ№е…ЁзҗғеҸҠеӣҪеҶ…20дҪҚAI科еӯҰ家е’Ңе·ҘзЁӢеёҲзҡ„и°ғз ”еҸ‘зҺ°пјҢдёӯеӣҪеңЁиҪҜ件е’Ңз®—жі•дјҳеҢ–дёҺеә”з”ЁеұӮйқўдёҺиҘҝж–№еӣҪ家зҡ„и·қзҰ»и¶ҠжқҘи¶Ҡе°ҸгҖӮжҜ”еҰӮжҝҖе…үйӣ·иҫҫжҠҖжңҜд»Һ19е№ҙеҲ°зҺ°еңЁпјҢзҹӯзҹӯдёӨе№ҙй—ҙиҝӣжӯҘе·ЁеӨ§гҖӮ19е№ҙзҡ„ж—¶еҖҷпјҢжҝҖе…үеҷЁпјҢжҺҘ收еҷЁпјҢдё»жҺ§FPGAе’ҢйҮҮж ·з”Ёзҡ„ADCпјҢиҝҷеӣӣдёӘжңҖж ёеҝғиҪҜ硬件йғҪжҳҜиў«еӣҪеӨ–еһ„ж–ӯзҡ„гҖӮзҺ°еңЁеӣҪеҶ…е·Із»ҸжңүйЎ¶зә§зҡ„жҝҖе…үеҷЁз”ҹдә§е•ҶпјҢдё»жҺ§е’ҢйҮҮж ·йғҪASICпјҲзү№ж®Ҡеә”з”ЁйӣҶжҲҗз”өи·ҜпјүеҢ–дәҶпјҢеҸӘеү©жҺҘ收еҷЁиҝҳжІЎжңүе®Ңе…Ёи§ЈеҶігҖӮеҶҚеҰӮпјҢеңЁиҜӯйҹіиҜҶеҲ«йўҶеҹҹпјҢзӣ®еүҚе…ЁзҗғжңҖе…Ҳиҝӣзҡ„ж–°дёҖд»ЈиҜӯйҹіиҜҶеҲ«зі»з»ҹ вҖңWenetвҖң д№ҹжҳҜз”ұдёӯ科йҷўе’ҢиҘҝе·ҘеӨ§AI科еӯҰ家иҮӘдё»еҲӣж–°е®ҢжҲҗзҡ„пјҢдё”ж•ҙеҘ—з®—жі•жЎҶжһ¶е®Ңе…ЁдёҚеҗҢдәҺиӢұеӣҪAI科еӯҰ家Danial PoveyжүҖеҲӣйҖ зҡ„вҖқKaldiвҖңиҜӯйҹіиҜҶеҲ«зі»з»ҹ пјҲдёҠдёҖд»ЈеӣҪйҷ…жңҖе…Ҳиҝӣзҡ„иҜӯйҹіиҜҶеҲ«зі»з»ҹпјүгҖӮ
иҝӣдёҖжӯҘпјҢжҲ‘们еҜ№20дҪҚ科еӯҰ家е’Ңе·ҘзЁӢеёҲзҡ„ж·ұеәҰи°ғз ”иҝӣиЎҢдәҶжҜ”иҫғеҲҶжһҗпјҢдёҖиҲ¬жҖ§зҡ„жҖ»з»“еҮәдәҶдёӯеӣҪеҸҜд»ҘйҖҡиҝҮз®—жі•е’ҢиҪҜ件зҡ„еә”з”ЁеҲӣж–°еңЁеӣӣдёӘж–№йқўжҢҒз»ӯејәеҢ–дёӯеӣҪзҺ°жңүд»·еҖјй“ҫгҖӮиҝҷеӣӣдёӘж–№йқўеҲҶеҲ«жҳҜпјҡжҷәиғҪеҢ–дә§е“ҒжңҚеҠЎи®ҫи®ЎгҖҒжҷәиғҪеҢ–з”ҹдә§еҲ¶йҖ пјҢжҷәиғҪеҢ–дҫӣеә”й“ҫз®ЎзҗҶд»ҘеҸҠжҷәиғҪеҢ–иҝҗиҗҘз®ЎзҗҶгҖӮ
1пјүжҷәиғҪдә§е“ҒдёҺжңҚеҠЎи®ҫи®ЎгҖӮеҲ©з”ЁеўһејәеӯҰд№ пјҲReinforcement LearningпјүпјҢзҘһз»ҸзҪ‘з»ңжЁЎеһӢпјҲNeutral Networkпјүд»ҘеҸҠиҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNatural Language ProcessingпјүеҜ№е®ўжҲ·зҡ„ж¶Ҳиҙ№иЎҢдёәе’ҢжЁЎеһӢиҝӣиЎҢйў„жөӢпјҢд»ҺиҖҢи®ҫи®Ўж–°зҡ„дә§е“ҒгҖӮеңЁжҲ‘们зҡ„и°ғз ”дёӯпјҢеҫҲеӨҡе…¬еҸёж—©е·ІејҖе§ӢеҲ©з”ЁеӨ§ж•°жҚ®еҜ№е®ўжҲ·дҪ“йӘҢе’Ңиҙӯд№°жЁЎејҸиҝӣиЎҢйў„жөӢпјҢд»ҺиҖҢиҝӣдёҖжӯҘеҹәдәҺйў„жөӢз»“жһңеҜ№дә§е“ҒжңҚеҠЎиҝӣиЎҢи®ҫи®Ўе’ҢеҲӣж–°гҖӮжӯӨеӨ–пјҢе·ҘзЁӢеёҲе’Ңи®ҫи®ЎеёҲеҸҜд»ҘйҮҮз”ЁеҲӣжҲҗејҸи®ҫи®ЎпјҲGenerative Designпјүе®һзҺ°дә§е“ҒеҲӣж–°гҖӮеҚійҖҡиҝҮи®ҫе®ҡеҜ№дә§е“Ғзҡ„зәҰжқҹжқЎд»¶пјҲжҜ”еҰӮйўңиүІпјҢеҪўзҠ¶пјҢжқҗж–ҷпјҢдҪ“з§ҜпјүпјҢз»“еҗҲеҲӣжҲҗејҸз®—жі•пјҲеҰӮеҸӮж•°еҢ–зі»з»ҹгҖҒиҝӣеҢ–зі»з»ҹгҖҒеҪўзҠ¶иҜӯжі•еҸҠжӢ“жү‘дјҳеҢ–з®—жі•зӯүпјүеҸҜиҮӘеҠЁз”ҹжҲҗдёҠдёҮз§Қдә§е“Ғи®ҫи®Ўж–№жЎҲгҖӮ
2пјүжҷәиғҪеҢ–з”ҹдә§еҲ¶йҖ гҖӮйҖҡиҝҮзӣ‘зқЈејҸе’Ңж— зӣ‘зқЈејҸжңәеҷЁеӯҰд№ (Supervised Learning & Unsupervised learning)з®—жі•пјҢжҸҗй«ҳдә§е“Ғз”ҹдә§еҲ¶йҖ зҡ„ж•ҲзҺҮе’Ңе“ҒиҙЁгҖӮжҜ”еҰӮпјҢдёӯй—ҙе“ҒеҲ¶йҖ з”ҹдә§иҝҮзЁӢдёӯжңүиҜёеӨҡеҲҶжҚЎдҪңдёҡпјҢеҰӮжһңйҮҮз”ЁжҷәиғҪеҢ–жңәеҷЁеҲҶжҚЎпјҢеҲҷеҸҜеӨ§еӨ§жҸҗй«ҳдә§е“Ғз”ҹдә§ж•ҲзҺҮгҖӮжӯӨеӨ–пјҢйҖҡиҝҮеҜ№иҙЁйҮҸе·®ејӮеҢ–зҡ„дә§е“ҒиҝӣиЎҢж·ұеәҰеӯҰд№ пјҲDeep LearningпјүпјҢеҶҚеҹәдәҺеҜ№дә§е“Ғеҗ„дёӘз”ҹдә§зҺҜиҠӮдёҠжүҖиҺ·еҫ—зҡ„зӣ‘жҺ§ж•°жҚ®пјҢеҸҜдҪҝжңәеҷЁи§Ҷи§үжӣҙеҝ«пјҢжӣҙзІҫзЎ®зҡ„иҜҶеҲ«еҮәдә§е“ҒиЎЁйқўзҡ„дёҚеҗҢз”ҹдә§зјәйҷ·гҖӮ
3пјүжҷәиғҪеҢ–дҫӣеә”й“ҫз®ЎзҗҶгҖӮеҲ©з”Ёж·ұеәҰеӯҰд№ з®—жі•еҸҜдјҳеҢ–дҫӣеә”й“ҫиҝҗиҫ“и·Ҝзәҝе’Ңд»“дҪҚз®ЎзҗҶгҖӮжҜ”еҰӮйҖҡиҝҮе°ҶеҺҶеҸІиҝҗиҫ“и·Ҝзәҝе’Ңе®һйҷ…дәӨд»ҳжҲҗжһңиҝӣиЎҢзҘһз»ҸзҪ‘з»ңи®ӯз»ғпјҢд»ҺиҖҢеҲҶжһҗиҝҗиҫ“ж–№жЎҲеҜ№дҫӣеә”й“ҫдёҠдәӨжҳ“жҲҗжң¬зҡ„еҪұе“ҚпјҢд»Ҙеё®еҠ©з®ЎзҗҶиҖ…зЎ®е®ҡжңҖдјҳиҝҗиҫ“и·ҜзәҝгҖӮжӯӨеӨ–пјҢеҹәдәҺзҘһз»ҸзҪ‘з»ңз®—жі•пјҢеҸҜеё®еҠ©еҲ¶йҖ е•Ҷе®һж—¶жЈҖжөӢеә“еӯҳеҸҳеҢ–пјҢеҸҠж—¶и°ғж•ҙеә“еӯҳ规模пјҢд»ҺиҖҢжңүж•ҲжҺ§еҲ¶еә“еӯҳзҹӯзјәжҲ–иҝҮеү©зҡ„зҠ¶еҶөгҖӮ
4пјүжҷәиғҪеҢ–иҝҗиҗҘз®ЎзҗҶгҖӮзӣ‘зқЈејҸеӯҰд№ еҸҜжңүж•Ҳеё®еҠ©дјҒдёҡдјҳеҢ–иҝҗиҗҘеҶізӯ–并йҷҚдҪҺиҝҗиҗҘжҲҗжң¬гҖӮеҲ©з”ЁеӣһеҪ’жЁЎеһӢпјҲRegressionпјү, еҶізӯ–ж ‘ (Decision Tree) еҸҠйҡҸжңәжЈ®жһ—жЁЎеһӢпјҲRandom ForestпјүеҜ№з”ҹдә§з®ЎзҗҶзі»з»ҹжҲ–жңәеҷЁи®ҫеӨҮиҝӣиЎҢж•…йҡңйў„жөӢпјҢд»ҺиҖҢжңүж•ҲйҷҚдҪҺиҝҗиҗҘжҲҗжң¬гҖӮеҸҰеӨ–пјҢеҲ¶йҖ е•ҶйҖҡиҝҮдј ж„ҹеҷЁзӣ‘жҺ§еҸҜ收йӣҶи®ҫеӨҮжүҖеӨ„зҺҜеўғзҡ„жё©еәҰпјҢз…§жҳҺеҸҠж№ҝеәҰеҸҳеҢ–пјҢд»ҺиҖҢйў„жөӢж•…йҡңдәӢ件еҸ‘з”ҹзҡ„жҰӮзҺҮд»ҘйҷҚдҪҺж•…йҡңдә§з”ҹеёҰжқҘзҡ„дёҚзЎ®е®ҡжҖ§гҖӮй’ҲеҜ№дёҖдәӣз”ҹдә§д»»еҠЎпјҢжңәеҷЁеӯҰд№ еҸҜд»ҘеҜ№з”ҹдә§еӨҚжқӮзЁӢеәҰдёҺз”ҹдә§и§„жЁЎиҝӣиЎҢеҢ№й…ҚеҲҶжһҗпјҢд»ҺиҖҢи®Ўз®—е…·дҪ“з”ҹдә§д»»еҠЎжүҖйңҖзҡ„е‘ҳе·Ҙж•°йҮҸгҖӮ
жңҖеҗҺпјҢеңЁжҲ‘们зҡ„и°ғз ”еҲҶжһҗдёӯпјҢз»қеӨ§еӨҡж•°дәәе·ҘжҷәиғҪ科еӯҰ家表зӨәдёӯеӣҪеңЁиҪҜ件е’Ңз®—жі•зҡ„еә”з”ЁеұӮйқўдёҺзҫҺеӣҪзӯүеҸ‘иҫҫеӣҪ家еҮ д№ҺжҳҜйҪҗеӨҙ并иҝӣгҖӮеңЁдёӯеӣҪзҡ„дјҳеҠҝдә§дёҡй“ҫдёҠпјҢжҲ‘们зңӢеҲ°е·Із»Ҹжңүи¶ҠжқҘи¶ҠеӨҡзҡ„дјҒдёҡејҖе§Ӣж¶Ңе…Ҙдәәе·ҘжҷәиғҪжөӘжҪ®пјҢйҖҡиҝҮеҜ№еӣҫеғҸеӨ„зҗҶгҖҒиҜӯйҹіеӨ„зҗҶгҖҒиҮӘ然иҜӯиЁҖзҗҶи§Јзӯүеә”з”ЁжҖ§з®—жі•е°Ҷдәәе·ҘжҷәиғҪеә”з”ЁеңЁеҗ„дёӘдә§дёҡй“ҫзҡ„дёҚеҗҢеңәжҷҜдёӯгҖӮеңЁеӣҪ家ж”ҝзӯ–е’Ңд»Јз ҒејҖжәҗзҡ„ж”ҜжҢҒдёӢпјҢд»·еҖјй“ҫдёҠжӣҙеӨҡзҡ„дёӯе°ҸдјҒдёҡеҸҜз§ҜжһҒйҖҡиҝҮз®—жі•е’ҢиҪҜ件еә”з”ЁжқҘејәеҢ–жҲ–жҸҗй«ҳиҮӘиә«еңЁеҲ¶йҖ з”ҹдә§зҺҜиҠӮдёҠзҡ„з«һдәүеҠӣгҖӮиҖҢеңЁзЁіеӣәзҺ°жңүд»·еҖјй“ҫз«һдәүдјҳеҠҝзҡ„еҹәзЎҖдёҠпјҢеңЁйғЁеҲҶз»ҶеҲҶиЎҢдёҡдёӯпјҢжҸҗеҚҮиҘҝж–№й«ҳз«Ҝ硬件жҠҖжңҜеңЁдёӯеӣҪиҪҜ件系з»ҹдёҠзҡ„дҪҝз”Ёдҫқиө–жҖ§жҳҜдёӯеӣҪиҝҲе…Ҙдёӯй«ҳз«Ҝд»·еҖјй“ҫзҡ„е…ій”®зӘҒз ҙеҸЈгҖӮжҜ”еҰӮпјҢдёӯеӣҪеңЁж— дәәжңәпјҢиҮӘеҠЁй©ҫ驶е’ҢеҢәеқ—й“ҫзӯүз»ҶеҲҶйўҶеҹҹдёҠзҡ„иҪҜ件е’Ңз®—жі•еҲӣж–°пјҢеҫҲеҸҜиғҪжңӘжқҘдјҡи®©йғЁеҲҶеӣҪеӨ–еҲ¶йҖ е•ҶйҖҗжӯҘйҖӮеә”е’ҢжҺҘеҸ—дёӯеӣҪзҡ„иҪҜ件系з»ҹгҖӮеңЁEDAйўҶеҹҹпјҢе°Ҫз®ЎеңЁе…ҲиҝӣеҲ¶зЁӢICпјҲйӣҶжҲҗз”өи·Ҝпјүи®ҫи®Ўж–№йқўпјҢEDAе·Ҙе…·еҮ д№Һиў«еӣҪйҷ…дёүеӨ§е·ЁеӨҙжүҖеһ„ж–ӯпјҢдҪҶеӣҪдә§EDAеңЁ40nmеҸҠ28nmеҲ¶зЁӢе·ҘиүәдёҠиҝ‘е№ҙжқҘиҝӣжӯҘйқһеёёжҳҺжҳҫпјҢз»“еҗҲ5GпјҢжұҪиҪҰз”өеӯҗгҖҒеҢәеқ—й“ҫзӯүж–°е…ҙйўҶеҹҹеҜ№ICи®ҫи®Ўзҡ„ж–°йңҖжұӮпјҢиҝҷеҸҜиғҪдёәEDAдёҺеӣҪеӨ–дёӯй«ҳз«ҜеҲ¶йҖ е•ҶжҸҗдҫӣзӣёдә’еҗҲдҪңдёҺеӯҰд№ зҡ„ж–№еҗ‘гҖӮ
з ҙеұҖд№ӢйҡңпјҡиҪҜ件дёҺз®—жі•еҲӣж–°зҡ„瓶йўҲ-еҹәзЎҖ科еӯҰ
дјҒдёҡзҡ„ж•°еӯ—еҢ–е’ҢжҷәиғҪеҢ–дёҚеҸҜиғҪдёҖи№ҙиҖҢе°ұпјҢзӣ®еүҚе…Ёзҗғд№ҹжІЎжңүдёҖдёӘйҖҡз”Ёзҡ„жЁЎжқҝеҸҜд»ҘеҘ—з”ЁгҖӮеңЁдёӯеӣҪд»·еҖјй“ҫдёҠпјҢеҜ№дәҺеғҸеӨ§йғЁеҲҶжҸҗдҫӣдёӯй—ҙе“ҒпјҢиө„жң¬е“Ғе’Ңж¶Ҳиҙ№е“Ғзҡ„жіӣеҲ¶йҖ дёҡе…¬еҸёжқҘиҜҙпјҢеҰӮдҪ•еҜ№з®—жі•е’ҢиҪҜ件иҝӣиЎҢеҲӣж–°е№¶ж №жҚ®дёҚеҗҢзҡ„з»ҶеҲҶеңәжҷҜжҸҗдҫӣзӣёеә”зҡ„и§ЈеҶіж–№жЎҲдҫқж—§жҳҜеҪ“еүҚдё»иҰҒйқўдёҙзҡ„жҢ‘жҲҳгҖӮеңЁжҲ‘们жүҖи°ғз ”зҡ„20дҪҚAI科еӯҰ家е’Ңе·ҘзЁӢеёҲдёӯпјҢеҮ д№ҺжүҖжңүдәәйғҪжҸҗеҲ°дәҶдёӯеӣҪеңЁж ёеҝғз®—жі•дёҺиҪҜ件еҺҹеҲӣжҖ§дёҠд»ҚдёҺеҸ‘иҫҫеӣҪ家жңүдёҚе°Ҹзҡ„е·®и·қгҖӮжӯӨеүҚиҘҝж–№еӣҪ家еҸҜиғҪе°Ҷе…ій—ӯеҜ№дёӯеӣҪGithubејҖжәҗд»Јз ҒеҲҶдә«зҡ„ж¶ҲжҒҜи®©еӣҪеҶ…еҫҲеӨҡз®—жі•е·ҘзЁӢеёҲе’Ң科еӯҰ家йғҪж„ҹеҲ°дәҶзҙ§еј гҖӮ
жҲ‘们и®ӨдёәпјҢж ёеҝғз®—жі•е’ҢиҪҜ件зҡ„жҢҒз»ӯеҲӣж–°ж №жң¬дёҠиҝҳжҳҜеҸ–еҶідәҺеҹәзЎҖ科еӯҰзҡ„еҸ‘еұ•е’ҢжҠ•е…ҘгҖӮж— и®әжҳҜе…ій”®зҡ„иҪҜ件иҝҳжҳҜ硬件жҠҖжңҜпјҢжҜҸдёҖз§Қдә§е“ҒйғҪжҳҜеҹәзЎҖ科еӯҰеҮ еҚҒе№ҙжқҘзҗҶи®әз§ҜзҙҜзҡ„дә§зү©гҖӮеӣ жӯӨпјҢжҲ‘们ејәи°ғеҹәзЎҖ科еӯҰжҠ•е…Ҙзҡ„й•ҝжңҹжҖ§дёҺзЁіе®ҡжҖ§жҳҜжҸҗй«ҳж ёеҝғз®—жі•дёҺиҪҜ件еҺҹеҲӣжҖ§зҡ„е…ій”®жүҖеңЁгҖӮе…¶ж¬ЎпјҢиҰҒеҜ»жұӮеңЁйҮҚзӮ№еҹәзЎҖ科еӯҰйўҶеҹҹе®һзҺ°еј•йўҶе’ҢзӘҒз ҙгҖӮиҪҜ件е’Ңж ёеҝғз®—жі•зҡ„еҺҹеҲӣжҖ§жң¬иҙЁдёҠе°ұжҳҜж•°еӯҰдҝЎжҒҜ科еӯҰдёҺжҠҖжңҜзҗҶи®әзҡ„еҺҹеҲӣгҖӮеӣ жӯӨпјҢз«Ӣи¶іеҪ“еүҚе®һйҷ…жғ…еҶөпјҢйӣҶдёӯиҰҒзҙ иө„жәҗж”ҜжҢҒж•°еӯҰдҝЎжҒҜ科еӯҰйўҶеҹҹзҡ„еҹәзЎҖзҗҶи®әеҸ‘еұ•дёҺеҲӣж–°жҳҜеҝ…иҰҒзҡ„гҖӮеҸҰеӨ–пјҢе°Ҫз®ЎиҘҝж–№йғЁеҲҶеӯҰжңҜжңәжһ„еҜ№дёӯеӣҪеӯҳеңЁиҜёеӨҡжҲ’еӨҮпјҢдҪҶжҲ‘们иҝҳжҳҜйңҖиҰҒйј“еҠұдёӯеӣҪз§‘з ”жңәжһ„жӣҙеҠ е№ҝжіӣзҡ„пјҢз§ҜжһҒзҡ„дёҺеӣҪйҷ…йЎ¶зә§еӯҰжңҜжңәжһ„иҝӣиЎҢеҗҲдҪңгҖӮеӨҡе…ғеҢ–е’ҢеӣҪйҷ…еҢ–зҡ„科еӯҰз ”з©¶еӣўйҳҹжңүеҲ©дәҺжҢҒз»ӯжҺЁиҝӣеҹәзЎҖ科еӯҰйўҶеҹҹзҡ„еҲӣж–°гҖӮ
йҷ„еҪ•

| 
 й’ҹжӯЈз”ҹзӯүпјҡе№ҝд№үиҙўж”ҝж”Ҝ
й’ҹжӯЈз”ҹзӯүпјҡе№ҝд№үиҙўж”ҝж”Ҝ вҖңдёӯеҺҹзІ®д»“вҖқпјҢе°ҸйәҰжү¬
вҖңдёӯеҺҹзІ®д»“вҖқпјҢе°ҸйәҰжү¬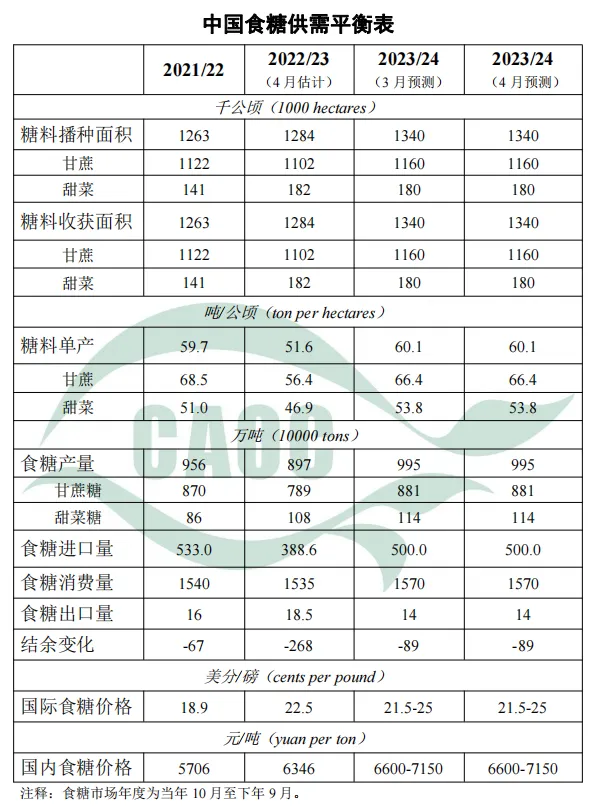 еҶңдёҡеҶңжқ‘йғЁпјҡ2024е№ҙ4
еҶңдёҡеҶңжқ‘йғЁпјҡ2024е№ҙ4 жқҺиҝ…йӣ·пјҡй»„йҮ‘дёәдҪ•иғҪи·‘
жқҺиҝ…йӣ·пјҡй»„йҮ‘дёәдҪ•иғҪи·‘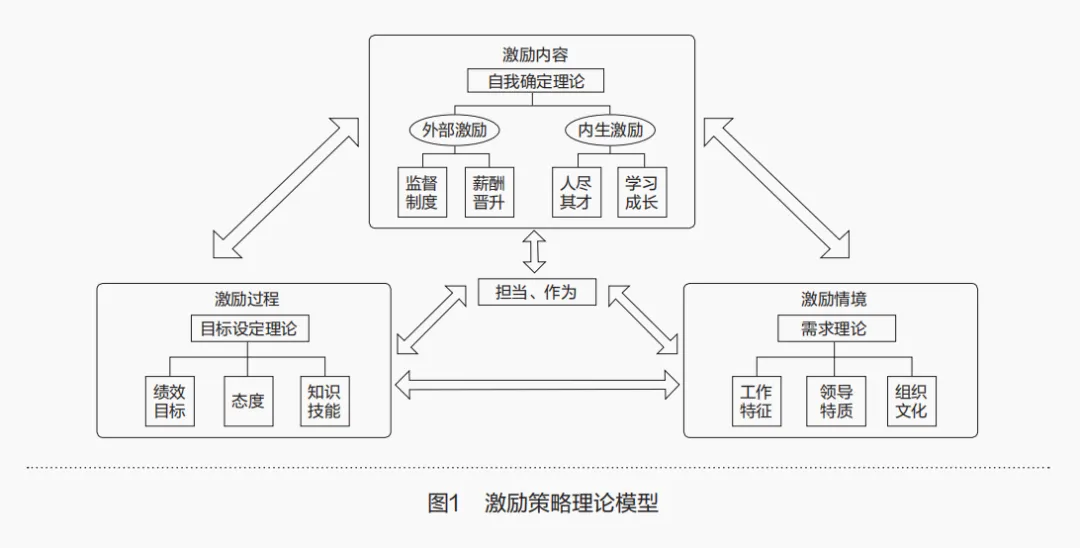 зҺӢй№ӯпјҡж–°ж—¶д»ЈпјҢеҰӮдҪ•жңү
зҺӢй№ӯпјҡж–°ж—¶д»ЈпјҢеҰӮдҪ•жңү йғӯзЈҠпјҡеҰӮдҪ•зҗҶи§ЈдёҖеӯЈеәҰ
йғӯзЈҠпјҡеҰӮдҪ•зҗҶи§ЈдёҖеӯЈеәҰ дјҚжҲҲпјҡз»ҸжөҺпјҢд»Һе№је„ҝеӣӯ
дјҚжҲҲпјҡз»ҸжөҺпјҢд»Һе№је„ҝеӣӯ й’ҹжӯЈз”ҹпјҡз»ҸжөҺвҖңжё©е·®вҖқ
й’ҹжӯЈз”ҹпјҡз»ҸжөҺвҖңжё©е·®вҖқ е‘Ёжө©пјҡзҫҺеҖәеҲ©зҺҮдёҠиЎҢпјҡ
е‘Ёжө©пјҡзҫҺеҖәеҲ©зҺҮдёҠиЎҢпјҡ 第е…ӯе·Ўи§Ҷз»„еӣҪ家粮йЈҹе’Ң
第е…ӯе·Ўи§Ҷз»„еӣҪ家粮йЈҹе’Ң зЁӢе®һпјҡд»Һи¶…йўқ收зӣҠзҡ„и§Ҷ
зЁӢе®һпјҡд»Һи¶…йўқ收зӣҠзҡ„и§Ҷ







 еҸ‘иЎЁдәҺ 2021-8-27 09:34:27
еҸ‘иЎЁдәҺ 2021-8-27 09:34:27
 жҸҗеҚҮеҚЎ
жҸҗеҚҮеҚЎ зҪ®йЎ¶еҚЎ
зҪ®йЎ¶еҚЎ
 第е…ӯе·Ўи§Ҷз»„еӣҪ家粮йЈҹе’Ңзү©иө„еӮЁеӨҮеұҖе…ҡз»„е·ҘдҪңеҠЁ
第е…ӯе·Ўи§Ҷз»„еӣҪ家粮йЈҹе’Ңзү©иө„еӮЁеӨҮеұҖе…ҡз»„е·ҘдҪңеҠЁ еҶңдёҡеҶңжқ‘йғЁеҸ¬ејҖ2024е№ҙе…Ёйқўд»ҺдёҘжІ»е…ҡе·ҘдҪңдјҡи®®
еҶңдёҡеҶңжқ‘йғЁеҸ¬ејҖ2024е№ҙе…Ёйқўд»ҺдёҘжІ»е…ҡе·ҘдҪңдјҡи®® з»ҹзӯ№иһҚиө„дҝЎз”ЁжңҚеҠЎе№іеҸ°е»әи®ҫжҸҗеҚҮдёӯе°Ҹеҫ®дјҒдёҡиһҚ
з»ҹзӯ№иһҚиө„дҝЎз”ЁжңҚеҠЎе№іеҸ°е»әи®ҫжҸҗеҚҮдёӯе°Ҹеҫ®дјҒдёҡиһҚ


