马дёҠжіЁеҶҢе…ҘдјҡпјҢз»“дәӨ专家еҗҚжөҒпјҢдә«еҸ—иҙөе®ҫеҫ…йҒҮпјҢи®©дәӢдёҡз”ҹжҙ»еҸҢиөўгҖӮ
жӮЁйңҖиҰҒ зҷ»еҪ• жүҚеҸҜд»ҘдёӢиҪҪжҲ–жҹҘзңӢпјҢжІЎжңүеёҗеҸ·пјҹз«ӢеҚіжіЁеҶҢ


x
йғӯжҜ…еҸҜпјҲйҰҷжёҜ科жҠҖеӨ§еӯҰйҰ–еёӯеүҜж Ўй•ҝгҖҒиӢұеӣҪзҡҮ家е·ҘзЁӢйҷўйҷўеЈ«гҖҒ欧жҙІз§‘еӯҰйҷўйҷўеЈ«гҖҒйҰҷжёҜе·ҘзЁӢ科еӯҰйҷўйҷўеЈ«пјҢ2023е№ҙвҖңеҗҙж–ҮдҝҠдәәе·ҘжҷәиғҪжқ°еҮәиҙЎзҢ®еҘ–вҖқиҺ·еҫ—иҖ…пјү
еҰӮжһңеӨ§жЁЎеһӢжҳҜдёҖдёӘзӯ”жЎҲпјҢйӮЈд№Ҳд»Җд№ҲжҳҜй—®йўҳ
иҜҙеҲ°еӨ§жЁЎеһӢпјҢдёҖдёӘз®ҖеҚ•зҡ„зҗҶи§Је°ұжҳҜжҠҠе·ЁйҮҸзҡ„дҝЎжҒҜпјҲеҰӮдә’иҒ”зҪ‘дёҠжүҖжңүзҡ„ж–Үеӯ—пјүеҺӢзј©пјҲеҚізј–з ҒпјүпјҢеңЁиҝҷдёӘеҺӢзј©зҡ„з©әй—ҙйҮҢеҪўжҲҗдёҖдёӘйҮҮж ·жңәеҲ¶пјҢе®ғеҸҜд»Ҙж №жҚ®йңҖиҰҒпјҲеҰӮеӣһзӯ”дёҖдёӘй—®йўҳпјүйҖүжӢ©дёҖдәӣеҺӢзј©зҡ„дҝЎжҒҜпјҢжҠҠе®ғеӨҚеҺҹпјҲеҚіиҜ‘з Ғпјүд»Ҙз”ҹжҲҗж–°зҡ„еҶ…е®№пјҲеҰӮеҜ№й—®йўҳзҡ„еӣһзӯ”пјүпјҢд№ҹе°ұжҳҜиҜҙжЁЎеһӢзҡ„з»ҲжһҒзӣ®ж ҮжҳҜеҺӢзј©иҫ“е…Ҙз©әй—ҙзҡ„дҝЎжҒҜпјҢеҪўжҲҗжЁЎеһӢпјҢдҪҝе…¶еҸҜд»ҘйҮҚжһ„并жҒўеӨҚеҺҹжқҘзҡ„иҫ“е…Ҙз©әй—ҙгҖӮеҜ№дәҺиҜӯиЁҖиҖҢиЁҖпјҢйҮҚжһ„з”ҹжҲҗзӯ–з•ҘжҳҜвҖңж–Үеӯ—жҺҘйҫҷвҖқпјҢеҚійҖҡиҝҮеүҚдёҖдёӘиҜҚйў„жөӢдёӢдёҖдёӘиҜҚзҡ„ж–№жі•з”ҹжҲҗеҸҘеӯҗгҖӮиҝҷж ·зҡ„з§°дёәиҮӘеӣһеҪ’зҡ„йў„жөӢеҹәдәҺвҖңжіЁж„ҸеҠӣвҖқпјҲattentionпјүзҡ„ж–№жі•жқҘи®Ўз®—иҜҚдёҺиҜҚзҡ„жүҖжңүзӣёе…іжҖ§пјҢ并用е®ғжқҘеҲӨж–ӯдёҖдёӘиҜҚе’ҢеҗҺдёҖдёӘиҜҚзҡ„з”ҹжҲҗгҖӮиҝҷдёӘзңӢдјјз®ҖеҚ•зҡ„ж–№жі•пјҢжҲҗе°ұдәҶChatGPTйқ©е‘ҪжҖ§зҡ„зӘҒз ҙпјҒ еӨ§жЁЎеһӢеңЁиҜӯиЁҖдёҠзҡ„жҲҗе°ұд№ҹжү©еұ•еҲ°дәҶе…¶д»–зҡ„жЁЎжҖҒпјҢеҰӮйҹід№җгҖҒи§Ҷйў‘йғҪиғҪеӨҹд»ҘеҗҢж ·зҡ„ж–№жі•з”ҹжҲҗгҖӮеңЁеӣҫеғҸж–№йқўпјҢжү©ж•ЈжЁЎеһӢйҖҡиҝҮеҜ№еӣҫеғҸиҝӣиЎҢеҺӢзј©зј–з ҒжқҘжҸҗеҸ–жҠҪиұЎеӣҫеғҸзҡ„зү№еҫҒпјҢ并йҖҡиҝҮиҜ‘з ҒеңЁеҺӢзј©зҡ„з©әй—ҙдёӯеҹәдәҺдёҚеҗҢзү№еҫҒзҡ„з»„еҗҲпјҢеҪўжҲҗж–°зҡ„еӣҫеғҸгҖӮеңЁз”ҹжҲҗзҡ„иҝҮзЁӢдёӯпјҢеҜ№дәҺеӣҫеғҸе…ғзҙ д№Ӣй—ҙзӣёе…іе…ізі»зҡ„дј°и®ЎпјҢдҪҝеҫ—з”ҹжҲҗзҡ„еӣҫеғҸз¬ҰеҗҲйҖ»иҫ‘гҖҒе…·жңүж„Ҹд№үгҖӮ иҝҷдёҖеҺҹзҗҶ并дёҚеӨҚжқӮпјҢиҖҢд»Ҙиҝҷж ·з®ҖеҚ•зҡ„еҺҹзҗҶеҺ»е®һзҺ°дёҖдёӘжңәеҷЁзҡ„иҜӯиЁҖжЁЎеһӢпјҢдҪҝжңәеҷЁеҸҜд»ҘдёҺдәәдёҖж ·иҝӣиЎҢдәӨжөҒеҜ№иҜқпјҢеҚҙе…·жңүеҲ’ж—¶д»Јзҡ„ж„Ҹд№үгҖӮ иҝҷз§Қж–№жі•д№ӢжүҖд»ҘиғҪеӨҹжҲҗеҠҹпјҢзјҳдәҺд»ҠеӨ©жҲ‘们еҸҜд»ҘжңүжғҠдәәзҡ„з®—еҠӣеҺ»еӨ„зҗҶеӨ©дёӢжүҖжңүзҡ„ж•°жҚ®гҖӮд»ҠеӨ©зҡ„и®Ўз®—жңәеҸҜд»ҘиҜ»йҒҚдё–з•ҢдёҠжүҖжңүзҡ„ж–Үеӯ—пјҢжҠҠе®ғеҺӢзј©жҲҗдёҖдёӘдёҮдәҝеҸӮж•°зҡ„жЁЎеһӢпјҢиҝҷжҳҜдёҖдёӘдјҹеӨ§зҡ„жҲҗе°ұгҖӮиҖҢиҝҷж ·зҡ„жЁЎеһӢеҸҜд»Ҙд»Һжө·йҮҸзҡ„ж–Үеӯ—йҮҢйқўпјҢжҖ»з»“еҮәжүҖжңүиҜҚдёҺиҜҚзҡ„е…ізі»пјҢжӣҙжҳҜдёҖз§ҚдёҚеҸҜжҖқи®®зҡ„иғҪеҠӣгҖӮ жңәеҷЁиө°еҲ°д»ҠеӨ©пјҢе…·жңүдәҶдёҺдәәзӣёиҝ‘зҡ„иҜӯиЁҖиғҪеҠӣпјҢз”Ёдё“дёҡзҡ„иҜқиҜҙе°ұжҳҜжңәеҷЁе…·жңүдәҶдёҺдәәзӣёиҝ‘зҡ„иҜӯиЁҖжЁЎеһӢпјҢиҝҷе·Із»ҸжҳҜдёҚдәүзҡ„дәӢе®һгҖӮжңәеҷЁеҸҜд»ҘеҰӮдәәиҲ¬еӣһзӯ”й—®йўҳпјҢи®©дәәд»Һеӣһзӯ”дёӯеҲҶиҫЁдёҚеҮәжңәеҷЁе’ҢдәәпјҢд№ҹе°ұжҳҜиҜҙд»ҠеӨ©зҡ„и®Ўз®—жңәйҖҡиҝҮдәҶеҪ“е№ҙеӣҫзҒөдёәеӣһзӯ”вҖңжңәеҷЁиғҪжҖқз»ҙеҗ—вҖқиҝҷдёӘй—®йўҳиҖҢи®ҫи®Ўзҡ„вҖңеӣҫзҒөжөӢиҜ•вҖқгҖӮдәәе·ҘжҷәиғҪиҝӣе…ҘдәҶвҖңеҗҺеӣҫзҒөж—¶д»ЈвҖқгҖӮ д»ҠеӨ©жҲ‘们йғҪеңЁеҒҡеӨ§жЁЎеһӢпјҢжңүејҖжәҗзҡ„гҖҒй—ӯжәҗзҡ„пјҢжңүиҜӯиЁҖзҡ„пјҢиҝҳжңүеҗ„з§Қе…¶д»–жЁЎжҖҒзҡ„гҖӮеңЁеӨ§жЁЎеһӢзҡ„иҝҪйҖҗдёӯжңүдёҖеҘ—жөӢиҜ•ж ҮеҮҶпјҢеҰӮеҗҢдәәзҡ„жҷәе•ҶжөӢиҜ•пјҢеӨ§е®¶йғҪеңЁд»Ҙиҝҷж ·зҡ„жөӢиҜ•жқҘиЎЎйҮҸжЁЎеһӢзҡ„ж°ҙе№іпјҢиҝҪжұӮдёҖдёӘSOTAпјҲеҚізӣ®еүҚзҡ„жңҖеҘҪз»“жһңпјүгҖӮд»ҝдҪӣдәәе·ҘжҷәиғҪзҡ„еҸ‘еұ•е·Із»ҸжүҫеҲ°дәҶдёҖдёӘзӯ”жЎҲгҖҒдёҖдёӘдёҮиғҪзҡ„ж–№жі•пјҢеү©дёӢзҡ„е·ҘдҪңе°ұжҳҜз”ЁжӣҙеӨҡзҡ„ж•°жҚ®гҖҒжӣҙејәзҡ„з®—еҠӣжҠҠжЁЎеһӢеҒҡеҫ—жӣҙеӨ§гҖӮ ејәеҢ–еӯҰд№ зҡ„йј»зҘ–иҗЁйЎҝпјҲRichard Suttonпјү2019е№ҙеҸ‘иЎЁдәҶдёҖзҜҮеҚҡж–ҮвҖ”вҖ”гҖҠиӢҰ涩зҡ„ж•ҷи®ӯгҖӢпјҲThe Bitter LessonпјүпјҢжҢҮеҮәеңЁдәәе·ҘжҷәиғҪз ”з©¶дёӯеҰӮиғҪжүҫеҲ°дёҖдёӘйҖҡз”Ёзҡ„ж–№жі•пјҢеҲ©з”ЁеӨ§з®—еҠӣдёҚж–ӯжӢ“еұ•е…¶иғҪеҠӣпјҢеҫҖеҫҖжҳҜжңҖжңүж•Ҳзҡ„з ”з©¶йҖ”еҫ„гҖӮиҝҷзҜҮеҚҡж–Үиў«е№ҝжіӣеј•з”ЁпјҢиў«з§°д№Ӣдёәдәәе·ҘжҷәиғҪеӯҰиҖ…еҝ…еӯҰзҡ„жқҗж–ҷпјҢиҝҷдёӘи®әж–ӯд№ҹиў«з§°д№ӢдёәвҖңжү©еұ•еҫӢвҖқпјҲScaling LawпјүгҖӮд»ҺиҝҷдёӘи®әж–ӯеҮәеҸ‘пјҢеӨ§жЁЎеһӢзҡ„еҸ‘еұ•дё»иҰҒжҳҜдҫқиө–еӨ§з®—еҠӣе’ҢеӨ§ж•°жҚ®пјҢиҝҷд№ҹжҳҜзӣ®еүҚеӨ§е®¶жҷ®йҒҚйҒөеҫӘзҡ„дёҖжқЎжҠҖжңҜи·ҜзәҝгҖӮ 然иҖҢпјҢжҲ‘们зңҹзҡ„е·Із»Ҹдёәдәәе·ҘжҷәиғҪзҡ„еҸ‘еұ•жүҫеҲ°дәҶеӨ§жЁЎеһӢиҝҷж ·дёҖдёӘе®ҢзҫҺзҡ„зӯ”жЎҲдәҶеҗ—пјҹжҲ‘们зҹҘйҒ“пјҢ科еӯҰеҸ‘еұ•жҜҸдёҖдёӘйҳ¶ж®өгҖҒжҜҸдёҖдёӘйҮҢзЁӢзў‘зҡ„е®ҢжҲҗйғҪдёҚеҸӘжҳҜз»ҷеҮәдёҖдёӘзӯ”жЎҲпјҢиҖҢжҳҜжҸҗеҮәдёҖзі»еҲ—ж–°зҡ„й—®йўҳпјҢиҝҷдәӣж–°зҡ„й—®йўҳжҒ°жҒ°жҳҜ科еӯҰ继з»ӯеҸ‘еұ•зҡ„еҶ…еңЁжҺЁеҠЁеҠӣгҖӮйӮЈд№ҲпјҢеӨ§жЁЎеһӢж—¶д»ЈпјҢжҸҗеҮәзҡ„й—®йўҳеҸҲжҳҜд»Җд№Ҳе‘ўпјҹ дҪңдёәжҠ•иө„иҖ…пјҢ他们关еҝғзҡ„й—®йўҳжҳҜеӨ§жЁЎеһӢзҡ„д»·еҖјеҲ°еә•жҳҜд»Җд№ҲпјҹеҰӮдҪ•е®һзҺ°е®ғзҡ„е•ҶдёҡеҲ©зӣҠпјҹдҪңдёәе“ІеӯҰ家пјҢ他们关еҝғзҡ„й—®йўҳжҳҜжңәеҷЁжҖқз»ҙе’Ңдәәзұ»жҖқз»ҙд№Ӣй—ҙзҡ„ејӮеҗҢд»ҘеҸҠз”ұжӯӨеёҰжқҘзҡ„дёҺзӨҫдјҡеҸ‘еұ•зҡ„е…ізі»гҖӮе“ІеӯҰ家з»ҙзү№ж №ж–ҜеқҰиҜҙиҝҮпјҢиҜӯиЁҖзЎ®е®ҡдәҶжҖқз»ҙзҡ„иҫ№з•ҢгҖӮд№ҹе°ұжҳҜиҜҙд»ҠеӨ©зҡ„жңәеҷЁжңүдәҶиҜӯиЁҖпјҢжүҖд»Ҙе®ғдёҚд»…жңүдәҶжҖқз»ҙзҡ„иЎЁиҫҫпјҢд№ҹжңүдәҶжҖқз»ҙзҡ„иғҪеҠӣпјҢйӮЈд№ҲпјҢиҝҷж ·зҡ„иғҪеҠӣе°ҶеҰӮдҪ•иҝӣеҢ–пјҢе…¶еҸ‘еұ•еҜ№дәәзұ»е’ҢзӨҫдјҡеҸҲжңүеӨҡеӨ§зҡ„еҶІеҮ»е’ҢеҪұе“ҚпјҹиҝҷжҳҜдәәе·ҘжҷәиғҪеҸ‘еұ•дёҺжІ»зҗҶйңҖиҰҒжҖқиҖғзҡ„еӨ§й—®йўҳгҖӮдҪңдёәи®Ўз®—жңә科еӯҰ家пјҢеңЁдёәжҠҖжңҜдёҚж–ӯиҝӣжӯҘиҖҢжғҠе–ңзҡ„ж—¶еҖҷпјҢжҲ‘们д№ҹеңЁжҖ»з»“иҝҮеҺ»зҡ„з»ҸйӘҢе’ҢжҺўзҙўжңӘжқҘзҡ„ж–№еҗ‘гҖӮд»ҠеӨ©еӨ§жЁЎеһӢз»ҷеҮәзҡ„并дёҚжҳҜдёҖдёӘзӯ”жЎҲпјҢиҖҢжҳҜдёҖзі»еҲ—ж–°зҡ„й—®йўҳвҖ”вҖ”и®©жңәеҷЁе…·жңүжҷәеҠӣпјҢжҲҗдёәдәәзұ»иҮӘиә«еҸ‘еұ•зҡ„еҘҪдјҷдјҙгҖҒеҘҪеё®жүӢжҳҜдёҖдёӘжј«й•ҝзҡ„еҫҒзЁӢгҖӮеҜ№иҝҷдәӣж–°й—®йўҳзҡ„зҗҶи§Је’ҢжҖқиҖғжңүеҠ©дәҺжҲ‘们规еҲ’еҘҪз ”з©¶зҡ„ж–№еҗ‘пјҢйҒҝе…Қдәәдә‘дәҰдә‘гҖҒйҮҚеӨҚеҠіеҠЁпјҢд»ҺиҖҢжңүж•Ҳең°иҝӣиЎҢеҲӣж–°гҖӮдёӢйқўпјҢ笔иҖ…е°Ҷд»Һз®—еҠӣгҖҒз®—ж–ҷпјҲж•°жҚ®пјүе’Ңз®—жі•дёүиҰҒзҙ зҡ„и§’еәҰжқҘи°ҲдёҖдәӣзңӢжі•гҖӮ е…ідәҺз®—еҠӣ еӨ§жЁЎеһӢзҡ„и®ӯз»ғйңҖиҰҒе·ЁеӨ§зҡ„з®—еҠӣгҖӮжҚ®з§°GPT-3жЁЎеһӢи®ӯз»ғдҪҝз”ЁдәҶ128еҸ°иӢұдјҹиҫҫA100жңҚеҠЎеҷЁпјҲи®ӯз»ғ34еӨ©пјүпјҢеҜ№еә”640Pз®—еҠӣпјӣGPT-4жЁЎеһӢи®ӯз»ғдҪҝз”ЁдәҶ3125еҸ°иӢұдјҹиҫҫA100жңҚеҠЎеҷЁпјҲи®ӯз»ғ90пҪһ100еӨ©пјүпјҢеҜ№еә”15625Pз®—еҠӣгҖӮд»ҺGPT-3еҲ°GPT-4жЁЎеһӢпјҢеҸӮ数规模еўһеҠ зәҰ10еҖҚпјҢдҪҶз”ЁдәҺи®ӯз»ғзҡ„GPUж•°йҮҸеўһеҠ дәҶиҝ‘24еҖҚпјҢжҖ»и®Ўз®—йҮҸеўһеҠ дәҶиҝ‘70еҖҚгҖӮеҸҜд»ҘжғіиұЎпјҢжү©еұ•еҫӢеҜ№еә”зҡ„иө„жәҗйңҖжұӮйҮҸйҖ’еўһжҳҜеӨҡд№Ҳзҡ„е·ЁеӨ§гҖӮе®һйҷ…дёҠпјҢжү©еұ•еҫӢиҝҳжҸӯзӨәдәҶдёҖдёӘд»ӨдәәжІ®дё§зҡ„дәӢе®һпјҡеҪ“жҲ‘们зҡ„иө„жәҗжҠ•е…Ҙе‘ҲзәҝжҖ§еўһй•ҝзҡ„ж—¶еҖҷпјҢжҖ§иғҪзҡ„жҸҗеҚҮжҳҜиҝңдҪҺдәҺзәҝжҖ§еўһй•ҝзҡ„гҖӮ е·ЁеӨ§зҡ„з®—еҠӣд№ҹж„Ҹе‘ізқҖе·ЁеӨ§зҡ„жҠ•е…ҘгҖӮжҚ®дј°и®ЎпјҢиҝҗиҗҘдёҖеҸ°иӢұдјҹиҫҫзҡ„A100жңҚеҠЎеҷЁпјҢдёҖе№ҙзҡ„жҲҗжң¬зәҰдёә80дёҮе…ғгҖӮеҜ№дәҺдёҖдёӘжӢҘжңүдёҮеҚЎзҡ„еҺӮе•ҶпјҢжӢҘжңү1250еҸ°жңҚеҠЎеҷЁпјҲ8еҚЎдёҖеҸ°жңҚеҠЎеҷЁпјүпјҢдёҖе№ҙйңҖиҰҒ1250д№ҳд»Ҙ80дёҮд№ҹе°ұжҳҜ10дәҝе…ғзҡ„жҲҗжң¬гҖӮеҸҜд»ҘжғіиұЎпјҢз»ҙжҠӨдёҖдёӘејәеӨ§зҡ„з®—еҠӣдёӯеҝғзҡ„жҲҗжң¬жҳҜжғҠдәәзҡ„пјҢеҜ№дәҺжҲҗжң¬еҰӮжӯӨй«ҳжҳӮзҡ„з®—еҠӣиө„жәҗпјҢеҰӮжһңдёҚиғҪеҫ—еҲ°ж»ЎиҙҹиҪҪзҡ„еҲ©з”ЁпјҢе°ҶдјҡйҖ жҲҗе·ЁеӨ§зҡ„жөӘиҙ№гҖӮ еӣ жӯӨпјҢеӨ§жЁЎеһӢзҡ„еҸ‘еұ•дёҚиғҪд»…д»…еңЁжү©еұ•зҺҮзҡ„й©ұеҠЁдёӢпјҢз”Ёз®—еҠӣзҡ„йҮҺиӣ®еўһй•ҝжқҘжҺЁеҠЁгҖӮз®—еҠӣзҡ„зЎ®жҳҜд»ҠеӨ©AIж—¶д»ЈжңҖж №жң¬зҡ„еҹәзЎҖи®ҫж–ҪпјҢдҪҶе®ғдёҚеҸҜиғҪжҳҜж— йҷҗзҡ„гҖӮжҲ‘们еҝ…йЎ»з ”з©¶й«ҳж•Ҳзҡ„еӯҰд№ ж–№жі•е’Ңзӯ–з•ҘжқҘиҒӘжҳҺең°дҪҝз”Ёжңүйҷҗзҡ„и®Ўз®—иө„жәҗгҖӮ ж··еҗҲ专家模еһӢгҖӮдјҳеҢ–и®Ўз®—ж•ҲзҺҮзҡ„дёҖдёӘжңүж•Ҳзҡ„ж–№жі•пјҢжҳҜйҖҡиҝҮеҜ№жЁЎеһӢз»“жһ„е’ҢжҺЁзҗҶжңәеҲ¶зҡ„ж”№иүҜпјҢдҪҝеҫ—жЁЎеһӢеҸӮж•°зҡ„еўһй•ҝе’Ңи®Ўз®—иө„жәҗйңҖжұӮзҡ„еўһй•ҝе‘ҲзәҝжҖ§иҖҢдёҚжҳҜеҖҚеўһе…ізі»пјҢиҝҷе…¶дёӯдёҖдёӘйҮҚиҰҒзҡ„иҝӣеұ•е°ұжҳҜйҖҡиҝҮеӨҡдёӘе°ҸеҸӮж•°жЁЎеһӢзҡ„з»„еҗҲеҪўжҲҗдёҖдёӘеӨ§еҸӮж•°йҮҸзҡ„жЁЎеһӢпјҢеҚівҖңж··еҗҲ专家模еһӢвҖқпјҲMixture of Experts, MoEпјүгҖӮиҝҷдёҖжЁЎеһӢе°ҶеӨҡдёӘдёҚеҗҢзҡ„еӯҰд№ ж•°жҚ®и®ӯз»ғжҲҗзҡ„еӯҗжЁЎеһӢзӣёз»“еҗҲпјҢз”ЁдёҖз§ҚиЎЁеҶіз»„еҗҲзҡ„ж–№ејҸеҪўжҲҗз»јеҗҲзҡ„з”ҹжҲҗеҶ…е®№гҖӮз”ұдәҺиҝҷдёҖж–№жЎҲеңЁжҺЁзҗҶиҝҮзЁӢдёӯиғҪеӨҹж №жҚ®иҫ“е…Ҙж•°жҚ®зҡ„дёҚеҗҢпјҢеҠЁжҖҒең°йҖүжӢ©дёҚеҗҢзҡ„еӯҗжЁЎеһӢпјҲеҚівҖң专家вҖқпјүиҝӣиЎҢи®Ўз®—пјҢдҪҝеӨ§жЁЎеһӢзҡ„еӯҰд№ е’ҢжҺЁзҗҶвҖңзЁҖз–ҸеҢ–вҖқпјҢеӣ иҖҢиғҪеӨҹжҠҠеӨ§жЁЎеһӢеҸӮж•°еўһй•ҝеҜ№з®—еҠӣзҡ„иҰҒжұӮвҖңзәҝжҖ§еҢ–вҖқпјҢе®һзҺ°жӣҙеҝ«зҡ„е“Қеә”йҖҹеәҰгҖӮиҝҷж ·зҡ„зӯ–з•Ҙе®һзҺ°дәҶеҜ№и®Ўз®—ж•ҲзҺҮзҡ„жһҒеӨ§ж”№иҝӣпјҢиҖҢдё”е®һи·өиҜҒжҳҺпјҢд»Ҙиҝҷж ·зҡ„ж–°ж–№ејҸжһ„йҖ зҡ„жЁЎеһӢзі»з»ҹзҡ„жҖ§иғҪдёҺеҗҢж ·и§„жЁЎзҡ„еҚ•дёҖжЁЎеһӢзӣёжҜ”并дёҚйҖҠиүІгҖӮиҝҷдёҖз»“жһңе…¶е®һ并дёҚд»ӨдәәжғҠ讶пјҢеӣ дёәе’Ңдәәи„‘дёҖж ·пјҢеҹәдәҺзҘһз»Ҹе…ғзҪ‘з»ңзҡ„жЁЎеһӢеңЁжҖқиҖғдёҖдёӘй—®йўҳзҡ„иҝҮзЁӢдёӯпјҢе®һйҷ…дёҠеҸӘжңүжһҒе°Ҹзҡ„дёҖйғЁеҲҶзҘһз»Ҹе…ғеҸӮдёҺдәҶе·ҘдҪңпјҢжүҖд»Ҙиҝҷж ·вҖңзЁҖз–ҸвҖқзҡ„еӯҰд№ е’ҢжҺЁзҗҶзӯ–з•Ҙеә”еҪ“жҳҜиЎҢд№Ӣжңүж•Ҳзҡ„гҖӮ й«ҳиҙЁйҮҸзҡ„ж•°жҚ®гҖӮ第дәҢз§ҚеҮҸе°‘еҜ№еӨ§з®—еҠӣдҫқиө–зҡ„йҮҚиҰҒжҖқи·ҜпјҢжҳҜз”Ёй«ҳиҙЁйҮҸзҡ„ж•°жҚ®жқҘејҘиЎҘжЁЎеһӢзҡ„规模дёҚи¶ігҖӮж•°жҚ®жҳҜдәәе·ҘжҷәиғҪзҡ„еҹәзҹіпјҢж•°жҚ®зҡ„иҙЁйҮҸе…ід№Һдәәе·ҘжҷәиғҪеҸ‘еұ•ж°ҙе№іпјҢеҪұе“Қе…¶е®үе…ЁжҖ§гҖҒеҸҜдҝЎжҖ§гҖӮй«ҳиҙЁйҮҸзҡ„ж•°жҚ®йӣҶеҸҜд»Ҙеё®еҠ©жЁЎеһӢжӣҙеҘҪең°зҗҶи§Је’ҢжҚ•жҚүдёҚеҗҢзҡ„жҰӮеҝөгҖҒиҜӯд№үе’ҢиҜӯжі•з»“жһ„пјҢдҪҝжЁЎеһӢеңЁеҗ„з§Қд»»еҠЎе’ҢйўҶеҹҹдёӯиЎЁзҺ°еҮәжӣҙеҘҪзҡ„жіӣеҢ–иғҪеҠӣпјҢжҺЁеҠЁеӨ§жЁЎеһӢзҡ„д»·еҖји·ғиҝҒгҖӮеӨ§жЁЎеһӢ并дёҚжҳҜи¶ҠеӨ§и¶ҠеҘҪпјҢж•°жҚ®д№ҹдёҚжҳҜи¶ҠеӨҡи¶ҠеҘҪпјҢзңҹжӯЈеҘҪзҡ„еӨ§жЁЎеһӢжҳҜеҸӮж•°еӨ§е°ҸйҖӮдёӯгҖҒж•°жҚ®иҙЁйҮҸй«ҳгҖӮе®һи·өе……еҲҶиҜҒжҳҺпјҢйқўеҜ№еҗҢдёҖдёӘеӯҰд№ зӯ–з•ҘпјҢй«ҳиҙЁйҮҸзҡ„еӯҰд№ ж•°жҚ®еҸҜд»ҘеӨ§еӨ§жҸҗй«ҳжЁЎеһӢзҡ„иҙЁйҮҸгҖӮзӣёжҜ”дёҖдёӘ规模жӣҙеӨ§дҪҶи®ӯз»ғж•°жҚ®иҙЁйҮҸиҫғдҪҺзҡ„жЁЎеһӢпјҢдёҖдёӘ规模иҫғе°ҸдҪҶдҪҝз”Ёй«ҳиҙЁйҮҸж•°жҚ®и®ӯз»ғзҡ„жЁЎеһӢеҸҜиғҪиЎЁзҺ°еҮәжӣҙй«ҳзҡ„з”ҹжҲҗиҙЁйҮҸгҖӮ жҢҒз»ӯеӯҰд№ гҖӮзј“и§Јз®—еҠӣйңҖжұӮзҡ„第дёүз§ҚйҮҚиҰҒж–№жі•жҳҜжҢҒз»ӯеӯҰд№ пјҢеҚіеңЁдёҚвҖңеҝҳи®°вҖқд»Һд»ҘеүҚзҡ„еӯҰд№ дёӯиҺ·еҫ—зҡ„зҹҘиҜҶзҡ„жғ…еҶөдёӢпјҢдёҚж–ӯең°з”Ёж–°зҡ„ж•°жҚ®жқҘжӣҙж–°жЁЎеһӢпјҢдҪҝи®ӯз»ғзҡ„еӨ§жЁЎеһӢжңүжӣҙй«ҳзҡ„з”ҹжҲҗиҙЁйҮҸгҖӮжҲ‘们зҹҘйҒ“пјҢдәәзұ»е…·жңүд»Һз»ҸйӘҢдёӯдёҚж–ӯеӨҚз”ЁжӢ“еұ•зҹҘиҜҶзҡ„иғҪеҠӣпјҢдёҚд»…еҸҜд»Ҙе°Ҷе…ҲеүҚеӯҰеҲ°зҡ„зҹҘиҜҶе’ҢжҠҖиғҪеә”з”ЁеҲ°ж–°зҡ„зҺҜеўғдёӯпјҢиҝҳеҸҜд»Ҙе°Ҷе®ғ们дҪңдёәд»ҘеҗҺеӯҰд№ зҡ„еҹәзЎҖгҖӮеҰӮжһңжңәеҷЁд№ҹиғҪжңүиҝҷж ·зҡ„жҢҒз»ӯеӯҰд№ жңәеҲ¶пјҢжҲ‘们е°ұеҸҜд»ҘйҒҝе…ҚжҜҸж¬ЎеңЁиҝӣеҢ–дёҖдёӘеӨ§жЁЎеһӢж—¶пјҢеңЁеҢ…еҗ«ж–°ж—§ж•°жҚ®иҝҷдёҖж–°зҡ„жӣҙеӨ§ж•°жҚ®йӣҶзҡ„еҹәзЎҖдёҠеҜ№ж•ҙдёӘжЁЎеһӢиҝӣиЎҢйҮҚж–°и®ӯз»ғпјҢд»ҺиҖҢж”№е–„еӨ§жЁЎеһӢи®ӯз»ғеҜ№з®—еҠӣзҡ„йңҖжұӮгҖӮдҪҶжҳҜпјҢжҢҒз»ӯеӯҰд№ дёҚжҳҜдёҖ件容жҳ“зҡ„дәӢжғ…пјҢжЁЎеһӢжүҖеӯҰеҲ°зҡ„зҹҘиҜҶдёҺ规еҫӢеӯҳеӮЁеңЁжЁЎеһӢеҸӮж•°дёӯпјҢеҪ“жЁЎеһӢеңЁж–°ж•°жҚ®йӣҶдёҠеӯҰд№ ж—¶пјҢзҪ‘з»ңдёӯзҡ„еҸӮж•°дјҡиў«жӣҙж–°пјҢиҖҢж—§д»»еҠЎзҡ„зҹҘиҜҶеҲҷдјҡиў«иҰҶзӣ–пјҢеҜјиҮҙжӣҙж–°еҗҺзҡ„жЁЎеһӢеңЁж—§д»»еҠЎдёҠзҡ„иЎЁзҺ°еҮәзҺ°вҖңзҒҫйҡҫжҖ§зҡ„дёӢйҷҚвҖқпјҢиҝҷз§ҚзҺ°иұЎиў«з§°дёәвҖңзҒҫйҡҫжҖ§йҒ—еҝҳвҖқгҖӮеҰӮдҪ•дҪҝжңәеҷЁеңЁжҢҒз»ӯеӯҰд№ дёӯе…ӢжңҚиҝҷдёҖй—®йўҳпјҢжҳҜдёҖдёӘеҫҲеӨ§зҡ„з ”з©¶иҜҫйўҳгҖӮжүҖд»ҘпјҢжҲ‘们иҰҒзңӢеҲ°пјҢд»ҠеӨ©жңәеҷЁеӯҰд№ зҡ„жңәеҲ¶иҝҳжҳҜеҫҲеҲқзә§зҡ„пјҢз”ҡиҮідёҚе…·еӨҮдәәзұ»жӢҘжңүзҡ„еҹәжң¬и®ӨзҹҘеҠҹиғҪпјҢжҜ”еҰӮвҖңи®°еҝҶвҖқгҖӮеңЁиҝҷж ·дёҖдёӘеҠҹиғҪж¬ зјәзҡ„жңәеҲ¶дёҠпјҢйҖҡиҝҮжү©еұ•еҫӢпјҢ用规模жқҘејҘиЎҘжңәеҲ¶зҡ„зјәйҷ·пјҢеә”иҜҘдёҚжҳҜдёҖдёӘй•ҝиҝңд№Ӣи®ЎгҖӮжҲ‘зӣёдҝЎпјҢеҜ№дәәи„‘иҝҷж ·дёҖдёӘз»ҸиҝҮеҮ зҷҫдёҮе№ҙзҡ„иҝӣеҢ–иҖҢеҪўжҲҗзҡ„й«ҳж•ҲеӯҰд№ жңәеҲ¶зҡ„з ”з©¶е’Ңи®ӨиҜҶпјҢдёҖе®ҡдјҡдҪҝжҲ‘们еҸ‘еұ•еҮәй«ҳж•Ҳзҡ„жңәеҷЁеӯҰд№ жңәеҲ¶пјҢдҪҝз®—еҠӣдёҚеҶҚжҲҗдёәеӨ§жЁЎеһӢеҸ‘еұ•зҡ„瓶йўҲгҖӮ е…ідәҺж•°жҚ®
жү©еұ•еҫӢзҡ„еҸҰдёҖдёӘз»“и®әжҳҜпјҢйҖҡиҝҮеӨ§йҮҸдёҚеҗҢзҡ„ж•°жҚ®жқҘи®ӯз»ғй«ҳе®№йҮҸзҡ„еӨ§жЁЎеһӢпјҢиҫғд№ӢдәҺйҖҡиҝҮе·§еҰҷзҡ„ж–№жі•гҖҒз”ЁзІҫйҖүзҡ„е°Ҹж•°жҚ®жқҘеҫ®и°ғдёҖдёӘзҺ°жҲҗзҡ„жЁЎеһӢпјҢжӣҙиғҪжҚ•жҚүж•°жҚ®зҡ„жң¬иҙЁзү№еҫҒпјҢд»ҺиҖҢжүҫеҲ°ж•°жҚ®зҡ„е…ұжҖ§пјҲеҚіжіӣеҢ–иғҪеҠӣпјүпјҢжҸҗй«ҳз”ҹжҲҗиғҪеҠӣгҖӮ зҺ°еңЁдёҡз•ҢжңүдёҖдёӘжҷ®йҒҚзҡ„и®ӨиҜҶпјҢе°ұжҳҜзӣ®еүҚжүҖжңүзҡ„ж•°жҚ®е·Із»Ҹеҝ«иў«з”Ёе®ҢпјҢжҲ‘们еҚіе°ҶйқўдёҙвҖңж•°жҚ®еҚұжңәвҖқгҖӮиҝҷдёӘзңӢжі•жңүдёҖе®ҡзҡ„йҒ“зҗҶпјҢдҪҶдәӢе®һжҳҜпјҢиў«жҲ‘们用е®Ңзҡ„ж•°жҚ®е№¶дёҚжҳҜж¶ҲеӨұдәҶпјҢиҖҢжҳҜиў«еҺӢзј©жҲҗдәҶдёҖдёӘејәеӨ§зҡ„жЁЎеһӢгҖӮдҪ•и°“еҺӢзј©пјҹеҺӢзј©е°ұжҳҜжүҫеҮәж•°жҚ®дёӯзҡ„规еҫӢжҖ§гҖҒе…ұжҖ§пјҢ并用жӣҙз®ҖжҙҒзҡ„ж–№ејҸдәҲд»ҘиЎЁзӨәпјҢд»ҘеҮҸе°‘еҶ—дҪҷдҝЎжҒҜгҖӮиҖҢеҪ“жҲ‘们жҲҗеҠҹең°еҜ№ж•°жҚ®иҝӣиЎҢеҺӢзј©ж—¶пјҢе°ұж„Ҹе‘ізқҖжҲ‘们已з»ҸжҚ•жҚүеҲ°дәҶж•°жҚ®зҡ„жң¬иҙЁзү№еҫҒе’Ң规еҫӢпјҢжүҖеҫ—еҲ°зҡ„жЁЎеһӢе°ұжңүдәҶдјҳз§Җзҡ„жіӣеҢ–е’Ңз”ҹжҲҗиғҪеҠӣгҖӮеҒҮеҰӮжҲ‘们жңүдәҶдёҖдёӘйқһеёёеҘҪзҡ„иҜӯиЁҖжЁЎеһӢпјҢйӮЈд№Ҳиҝҷж ·зҡ„иҜӯиЁҖжЁЎеһӢеҗҢж—¶д№ҹжһ„жҲҗдәҶдёҖдёӘжңҖејәеӨ§зҡ„ж•°жҚ®з”ҹжҲҗеҷЁпјҢеҸҜд»Ҙз”ҹжҲҗжүҖжңүжҲ‘们жғіи®Ізҡ„е’ҢиғҪи®Ізҡ„иҜқгҖӮеҰӮжӯӨдёҖжқҘпјҢжӣҙжңүж„Ҹд№үзҡ„е·ҘдҪңе°ұдёҚеҶҚжҳҜеҠӘеҠӣеҜ»жүҫж–°зҡ„ж•°жҚ®пјҢиҖҢжҳҜз ”з©¶еҰӮдҪ•д»ҺеӨ§жЁЎеһӢдёӯз”ҹжҲҗжҲ‘们йңҖиҰҒзҡ„ж•°жҚ®пјҢ并еңЁиҝҷж ·зҡ„ж•°жҚ®д№ӢдёҠд»Ҙжңүйҷҗзҡ„з®—еҠӣжӣҙдёәжңүж•Ҳең°жһ„йҖ дёҖдёӘеҸҲдёҖдёӘзІҫиҮҙзҡ„гҖҒж»Ўи¶ізү№е®ҡйңҖиҰҒзҡ„жЁЎеһӢгҖӮ иҝҷеҗ¬иө·жқҘд»ҝдҪӣжҳҜдёҖдёӘиҪ®еӣһпјҡд»Һж•°жҚ®еҲ°жЁЎеһӢеҸҲд»ҺжЁЎеһӢз”ҹжҲҗж•°жҚ®пјҢдҪҶиҝҷж ·зҡ„иҪ®еӣһеҸҜд»Ҙе®һзҺ°еұӮж¬ЎжҖ§зҡ„дёҠеҚҮпјҡж–°зҡ„ж•°жҚ®е’ҢдҝЎжҒҜзҡ„иҙЁйҮҸгҖҒиҜӯиЁҖзҡ„з»“жһ„жӣҙдёәй«ҳзә§пјҢд»ҺиҖҢдҪҝеҫ—ж–°зҡ„жЁЎеһӢеңЁеұӮж¬ЎдёҠжңүдәҶиҙЁзҡ„йЈһи·ғгҖӮжҜ”еҰӮжҲ‘们иҰҒжұӮж–°зҡ„иҜӯиЁҖжЁЎеһӢеҸҜд»ҘжҮӮеҫ—е№Ҫй»ҳгҖҒеҜҢжңүж„ҹжғ…пјҢеҸҜд»ҘеҶҷеҮә笑иҜқпјҢиҝҷдёҚжҳҜдёҖдёӘз®ҖеҚ•зҡ„д»»еҠЎгҖӮзҫҺеӣҪи‘—еҗҚдҪң家гҖҒиҜӯиЁҖеӯҰ家еӢ’еҸӨжҒ©пјҲUrsula K. Le GuinпјүжҢҮеҮәпјҢиҜҚиҜӯжҳҜдёҖз§ҚдәӢ件пјҢе…·жңүдҪңз”ЁеҠӣпјҢиғҪеӨҹж”№еҸҳдәӢзү©гҖӮе®ғ们дёҚд»…иғҪеӨҹж”№еҸҳиҜҙиҜқиҖ…е’ҢиҒҶеҗ¬иҖ…пјҢиҝҳиғҪеңЁеҸҢж–№д№Ӣй—ҙдј йҖ’иғҪйҮҸпјҢдј йҖ’зҗҶи§ЈжҲ–жғ…ж„ҹпјҢ并еҜ№е…¶иҝӣиЎҢж”ҫеӨ§гҖӮ然иҖҢпјҢеҪ“иҜҚиҜӯиў«еүҘзҰ»дәҶвҖңдәәжҖ§вҖқпјҢиҫ“е…ҘеҲ°ж— ж„ҹжғ…зҡ„жңәеҷЁдёӯпјҢиў«з”ЁдҪңдёҚе…·жңүеҗҜиҝӘеҠҹиғҪзҡ„дҝЎжҒҜд»Јд»·зү©ж—¶пјҢдјҡеҸ‘з”ҹд»Җд№Ҳе‘ўпјҹиҝҷжӯЈжҳҜд»ҠеӨ©зҡ„еӨ§жЁЎеһӢжҠҖжңҜйқўдёҙзҡ„дёҖдёӘжҢ‘жҲҳгҖӮ иҰҒеңЁжңәеҷЁз”ҹжҲҗзҡ„иҜӯиЁҖдёӯжіЁе…ҘвҖңдәәжҖ§вҖқпјҢе°ұиҰҒжұӮжҲ‘们еңЁжЁЎеһӢдёӯжіЁе…ҘиғҪеӨҹз”ЁиҜӯиЁҖиЎЁиҫҫзҡ„дәәзұ»ж–ҮжҳҺеҮқз»ғзҡ„зІҫзҘһжҷәж…§е’Ңж–ҮеҢ–еә•и•ҙпјҢд№ҹе°ұжҳҜиҜҙжҲ‘们еңЁи®ӯз»ғжЁЎеһӢж—¶пјҢеҜ№иҜӯиЁҖж•°жҚ®зҡ„еҺӢзј©дёҚд»…иҰҒжҚ•жҚүдҪҺйҳ¶зҡ„иҜӯд№үзү№еҫҒпјҢиҝҳиҰҒжҚ•жҚүй«ҳйҳ¶зҡ„иҜӯеўғгҖҒиҜӯз”Ёзү№еҫҒпјҢиҝҷеҜ№иҜӯиЁҖжЁЎеһӢзҡ„еӯҰд№ жҸҗеҮәдәҶж–°зҡ„иҰҒжұӮгҖӮдёәдәҶжҠҠиҝҷж ·зҡ„еұӮж¬ЎжҖ§иЎЁиҫҫеҮәжқҘпјҢд№ҹи®ёпјҢжҲ‘们жңӘжқҘзҡ„еҺӢзј©зј–з Ғз©әй—ҙе°ҶдёҚеҶҚжҳҜз®ҖеҚ•зҡ„еҗ‘йҮҸз©әй—ҙдәҶгҖӮ иҝӣиҖҢиЁҖд№ӢпјҢеҜ№ж–°ж•°жҚ®еҗҲжҲҗзҡ„иҰҒжұӮд№ҹе°ҶдёҚеҶҚж»Ўи¶ідәҺз®ҖеҚ•ең°жҢүеҲҶеёғйҮҮж ·пјҢж•°жҚ®зҡ„з”ҹжҲҗдёҚеҶҚжҳҜи¶ҠеӨҡи¶ҠеҘҪпјҢиҖҢжҳҜиҰҒжңүйҖүжӢ©жҖ§пјҢејәи°ғдёҖе®ҡжқЎд»¶дёӢзҡ„ж•°жҚ®з”ҹжҲҗгҖҒжңүз»“жһ„зҡ„ж•°жҚ®з”ҹжҲҗпјҢеҚіж•°жҚ®зҡ„дә§з”ҹе’ҢйҮҮйӣҶжҳҜз»“жһ„еҢ–зҡ„пјҢиҖҢдёҚжҳҜеҰӮзҺ°еңЁиҝҷиҲ¬вҖ”вҖ”еӨ§жЁЎеһӢзҡ„ж•°жҚ®йҮҮйӣҶз”ЁдёҖдёӘж•°жҚ®е…ғпјҲtokenпјүз»ҹдёҖз»„з»ҮвҖ”вҖ”иҝӣиЎҢзәҝжҖ§йҮҮйӣҶе’ҢйЎәеәҸз”ҹжҲҗдәҶгҖӮ дҫқ笔иҖ…д№Ӣи§ҒпјҢз”ЁдәҺеӯҰд№ зҡ„ж•°жҚ®жҳҜеҸ–д№ӢдёҚе°ҪгҖҒз”Ёд№ӢдёҚз«ӯзҡ„гҖӮж•°жҚ®жҳҜе®ўи§Ӯдё–з•Ңзҡ„дёҖз§ҚдҪ“зҺ°е’ҢиЎЁиҫҫпјҢеҰӮжһңжҠҠжЁЎеһӢзңӢжҲҗжҳҜжңәеҷЁйҖҡиҝҮж•°жҚ®еҜ№е®ўи§Ӯдё–з•ҢиҝӣиЎҢзҗҶи§ЈпјҢйӮЈд№Ҳж•°жҚ®е’ҢжЁЎеһӢзҡ„е…ізі»дҫҝз¬ҰеҗҲжҜӣжіҪдёңеҗҢеҝ—еңЁвҖңе®һи·өи®әвҖқдёӯеҜ№иҫ©иҜҒе”Ҝзү©дё»д№үи®ӨиҜҶи®әзҡ„йҳҗиҝ°пјҡвҖңе®һи·өгҖҒи®ӨиҜҶгҖҒеҶҚе®һи·өгҖҒеҶҚи®ӨиҜҶпјҢиҝҷз§ҚеҪўејҸпјҢеҫӘзҺҜеҫҖеӨҚд»ҘиҮіж— з©·пјҢиҖҢе®һи·өе’Ңи®ӨиҜҶд№ӢжҜҸдёҖеҫӘзҺҜзҡ„еҶ…е®№пјҢйғҪжҜ”иҫғең°иҝӣеҲ°дәҶй«ҳдёҖзә§зҡ„зЁӢеәҰгҖӮиҝҷе°ұжҳҜиҫ©иҜҒе”Ҝзү©и®әзҡ„е…ЁйғЁи®ӨиҜҶи®әпјҢиҝҷе°ұжҳҜиҫ©иҜҒе”Ҝзү©и®әзҡ„зҹҘиЎҢз»ҹдёҖи§ӮвҖқгҖӮе°ұеӨ§жЁЎеһӢиҖҢиЁҖпјҢд»Һж•°жҚ®еҲ°жЁЎеһӢдҪ“зҺ°дәҶе®һи·өпјҢиҖҢд»ҺжЁЎеһӢеҲ°ж•°жҚ®еҸҚжҳ дәҶи®ӨиҜҶгҖӮжҲ‘们дёҚеҝ…жӢ…еҝғж•°жҚ®зҡ„з©·е°ҪпјҢиҖҢеә”иҜҘжңҹеҫ…и¶ҠжқҘи¶ҠжңүдәәжҖ§зҡ„еӨ§жЁЎеһӢзҡ„еҲ°жқҘгҖӮ е…ідәҺз®—жі•
жңӘжқҘзҡ„еӨ§жЁЎеһӢеҰӮдҪ•еҸ‘еұ•пјҹиҝҷжҳҜд»ҠеӨ©жҜҸдёҖдёӘдәәе·ҘжҷәиғҪз ”з©¶иҖ…йғҪиҰҒи®ӨзңҹжҖқиҖғзҡ„й—®йўҳгҖӮеҰӮдёҠж–ҮжүҖиЁҖпјҢд»ҘиҮӘеӣһеҪ’дёәеҹәзЎҖзҡ„еӨ§жЁЎеһӢзҡ„з ”з©¶еҸ–еҫ—дәҶи®ёеӨҡйқһеёёжҢҜеҘӢдәәеҝғзҡ„жҲҗжһңпјҢеӯҳеңЁжҠҖжңҜж”№иҝӣзҡ„еҸҜиғҪжҖ§з©әй—ҙе’Ңе№ҝйҳ”зҡ„ејҖжӢ“жҪңеҠӣпјҢзү№еҲ«жҳҜеңЁеӯҰд№ ж•ҲзҺҮзҡ„жҸҗй«ҳгҖҒжҖқз»ҙй“ҫзҡ„еўһејәдёҺеҗҲжҲҗж•°жҚ®зҡ„ж·ұеәҰгҖҒзІҫеәҰе’Ңе№ҝеәҰзӯүж–№йқўеӨ§жңүеҸҜдёәгҖӮжӯӨеӨ–пјҢжҠҠеӨ§жЁЎеһӢдёҺе…¶д»–зҡ„еҠҹиғҪи°ғз”ЁпјҲfunctional callпјүзҡ„дёҡеҠЎе·ҘдҪңжөҒзӣёз»“еҗҲпјҢжҠҠиҜӯиЁҖдҪңдёәе·ҘдҪңжөҒзҡ„й©ұеҠЁжңәеҲ¶пјҢеҸҜд»ҘзҒөжҙ»ең°з»„з»Үеҗ„з§ҚеҠҹиғҪпјҢеҪўжҲҗдёҖдёӘеӨ§е•ҶдёҡиҜӯиЁҖжЁЎеһӢпјҲLarge Business Language ModelпјүгҖӮиҝҷд№ҹжҳҜеӨ§жЁЎеһӢз®—жі•з ”з©¶дёҠдёҖдёӘйқһеёёжңүеүҚжҷҜзҡ„ж–№еҗ‘гҖӮиҝҷйҮҢжҲ‘жғіи°ҲдёҖдёӢеҜ№з”ҹжҲҗејҸдәәе·ҘжҷәиғҪз®—жі•зҡ„дёҖдәӣж №жң¬жҖ§й—®йўҳгҖӮ еҹәдәҺиҮӘеӣһеҪ’зҡ„з”ҹжҲҗжЁЎеһӢзҡ„еұҖйҷҗжҖ§гҖӮеҹәдәҺиҮӘеӣһеҪ’зҡ„з”ҹжҲҗжЁЎеһӢзҡ„еҹәжң¬жҖқи·ҜжҳҜзәҝжҖ§ең°дҫқйЎәеәҸйҮҚжһ„иҫ“е…Ҙз©әй—ҙпјҢжүҖд»ҘпјҢи®©жЁЎеһӢе…·жңүиЎҘе…ЁдёҖеҸҘиҜқгҖҒеЎ«ж»ЎдёҖеј еӣҫзҡ„иғҪеҠӣжҳҜжңүж•Ҳзҡ„еӯҰд№ ж–№жі•пјҢзӣ®зҡ„йғҪжҳҜдҪҝжЁЎеһӢе…·жңүз”ҹжҲҗеҠӣгҖӮдҪҶжҳҜпјҢиҝҷж ·зҡ„жЁЎеһӢд№ҹжңүе…¶еҶ…еңЁзјәйҷ·гҖӮ д»ҺеӯҰд№ зҡ„и§’еәҰиҖҢиЁҖпјҢд»ҘйҮҚжһ„дё–з•Ңдёәзӣ®ж Үзҡ„еӯҰд№ е№¶дёҚзӯүеҗҢдәҺеҸҜд»ҘзҗҶи§Јдё–з•ҢгҖӮжӯЈеҰӮдҪ еӯҰдјҡдәҶйҮҚж–°жӢјиЈ…дёҖжһ¶йЈһжңәпјҢ并дёҚзӯүдәҺдҪ зҗҶи§ЈйЈһиЎҢзҡ„еҺҹзҗҶпјҢд№ҹдёҚдёҖе®ҡзЎ®дҝқдҪ иғҪеӨҹйҮҚж–°и®ҫи®ЎеҮәдёҖжһ¶ж–°зҡ„йЈһжңәгҖӮжүҖд»ҘпјҢйҮҚжһ„еҸӘжҳҜеӯҰд№ зҡ„第дёҖжӯҘпјҢзҗҶи§ЈжүҖжһ„йҖ зҡ„дё–з•ҢжүҚжҳҜе…ій”®иҖҢиү°йҡҫзҡ„дёӢдёҖжӯҘгҖӮиҝҷдёӘжҢ‘жҲҳеңЁзӣ®еүҚзҡ„и§Ҷйў‘з”ҹжҲҗз ”з©¶дёӯе·Із»ҸжҳҫзӨәеҫ—еҫҲжё…жҘҡдәҶгҖӮжҲ‘们еҸҜд»ҘжҠҠи§Ҷйў‘з”ҹжҲҗе’ҢиҜӯиЁҖз”ҹжҲҗзӯүеҗҢиө·жқҘпјҢжҠҠи§Ҷйў‘зңӢжҲҗжҳҜеӣҫеғҸзҡ„еәҸеҲ—иҜӯиЁҖпјҢеҹәдәҺеҗҢж ·зҡ„иҮӘеӣһеҪ’ж–№жі•и®©жңәеҷЁжқҘйҮҚжһ„пјҢд»ҺеӨ§йҮҸзҡ„и§Ҷйў‘ж•°жҚ®дёӯеӯҰдјҡеӣҫеғҸеәҸеҲ—зҡ„з”ҹжҲҗгҖӮиҝҷе°ұиҰҒжұӮеңЁдёҖдёӘиҝһз»ӯзҡ„ж—¶й—ҙеәҸеҲ—дёӯеҮҶзЎ®ең°з”ҹжҲҗжҜҸдёҖе№…еӣҫеғҸдёҠзҡ„еҗ„з§Қз»ҶиҠӮпјҢ并еңЁиҝҷдёӘж—¶й—ҙж®өдёӯдҝқжҢҒжҜҸдёҖе№…еӣҫеғҸзҡ„дёҖиҮҙжҖ§пјҲеҰӮдёҚеҸҳзҡ„е»әзӯ‘иғҢжҷҜгҖҒз¬ҰеҗҲиҝҗеҠЁи§„еҫӢзҡ„иҪҰжөҒзӯүпјүпјҢиҝҷжҳҜйқһеёёеӣ°йҡҫзҡ„пјҢеӣ дёәйҮҚжһ„дёҖдёӘеҠЁжҖҒиҝһз»ӯеҸҳеҢ–зҡ„еңәжҷҜзҡ„еӨҚжқӮзЁӢеәҰиҰҒжҜ”йҮҚжһ„дёҖж®өйқҷжҖҒзҡ„ж–Үеӯ—иЎЁиҫҫй«ҳеҫ—еӨҡгҖӮеӣ жӯӨ笔иҖ…и®ӨдёәпјҢз”ЁиҮӘеӣһеҪ’зҡ„ж–№жі•з”ҹжҲҗи§Ҷйў‘пјҢз”ҹжҲҗеҶ…е®№з»ҶиҠӮжңүйҷҗзҡ„еҠЁз”»жҳҜжҜ”иҫғзҺ°е®һзҡ„пјҢдҪҶеҜ№дәҺй«ҳжё…зҡ„гҖҒжңүзңҹе®һеңәжҷҜз»ҶиҠӮзҡ„и§Ҷйў‘з”ҹжҲҗпјҢе®ғеҸҜиғҪдёҚжҳҜдёҖжқЎжңүж•Ҳзҡ„йҖ”еҫ„гҖӮ д»ҺвҖңжҗңзҙўиҢғејҸвҖқеҲ°вҖңд»·еҖјиҢғејҸвҖқгҖӮеҰӮдҪ•жҠҠжҸЎеӨ§жЁЎеһӢжңӘжқҘзҡ„еҸ‘еұ•ж–№еҗ‘пјҹе…ідәҺиҝҷдёӘе‘Ҫйўҳжңүи®ёеӨҡи®Ёи®әпјҢдҫӢеҰӮд»ҺжҠҖжңҜгҖҒе“ІеӯҰгҖҒи®ӨзҹҘ科еӯҰзӯүи§’еәҰгҖӮдёӢйқўпјҢ笔иҖ…е°Ҷд»ҺеӨ§жЁЎеһӢдҪҝз”ЁжЁЎејҸзҡ„и§’еәҰжқҘи°Ҳи°ҲиҝҷдёӘй—®йўҳгҖӮ д»ҠеӨ©пјҢеӨ§жЁЎеһӢж”ҜжҢҒдәәзұ»е’ҢжңәеҷЁзҡ„вҖңдәәй—®жңәзӯ”вҖқдәӨжөҒжЁЎејҸпјҢиҝҷж ·зҡ„дәӨжөҒжҳҜз®ҖеҚ•зҡ„пјҢжҲ‘们еҸҜд»ҘжҠҠе®ғзңӢжҲҗжҳҜжҗңзҙўзҡ„дёҖдёӘй«ҳзә§зүҲпјҢз”ҹжҲҗзҡ„зӯ”жЎҲеҸҜд»Ҙи§ҶдёәжЈҖзҙўеҶ…е®№зҡ„дёҖдёӘжҖ»з»“гҖӮжүҖд»ҘпјҢд»ҠеӨ©еӨ§жЁЎеһӢзҡ„еӯҰд№ е’ҢжҺЁзҗҶж”ҜжҢҒзҡ„жҳҜвҖңжҗңзҙўиҢғејҸвҖқгҖӮ дәӢе®һдёҠпјҢжҲ‘们дҪҝз”Ёзҡ„еӨ§жЁЎеһӢжҗңзҙўиҢғејҸ并дёҚжҳҜе”ҜдёҖзҡ„ж–№ејҸгҖӮжҜӢе®Ғи§Ҷе…¶дёәдёҖз§ҚеҲқзә§зҡ„з”ҹжҲҗиғҪеҠӣпјҢеӣ дёәе®ғеҸӘжҳҜеңЁиҜҚиҜӯзӣёе…іжҖ§зҡ„жҢҮеҜјдёӢпјҢеҜ№еӯҰиҝҮзҡ„иҜӯиЁҖиҝӣиЎҢеҗҲд№Һз»ҹ计规еҫӢзҡ„йҮҚжһ„гҖӮиҝҷж ·зҡ„иҮӘеӣһеҪ’ж–№жі•иҝҳдёҚе…·жңүдәәзұ»иҜӯиЁҖдёӯзҡ„зұ»жҜ”гҖҒиҒ”жғігҖҒеұӮж¬ЎжҺЁзҗҶзӯүеҗ„з§ҚиғҪеҠӣгҖӮеңЁжңӘжқҘеӨ§жЁЎеһӢзҡ„з ”з©¶дёӯпјҢжҲ‘们иҰҒи¶…и¶ҠиҮӘеӣһеҪ’зҡ„жҖқжғіпјҢеҲӣйҖ еҮәжӣҙй«ҳзә§зҡ„иҜӯиЁҖиғҪеҠӣпјҢиҝҷе°ҶжһҒеӨ§ең°дё°еҜҢеӨ§жЁЎеһӢзҡ„еә”з”Ёж–№ејҸпјҢеҗҢж—¶иҝҷд№ҹе°ҶжҳҜеӨ§жЁЎеһӢз®—жі•з ”з©¶дёӯдёҖдёӘжңүж„Ҹд№үзҡ„ж–№еҗ‘гҖӮ д»ҺвҖңдәәй—®жңәзӯ”вҖқзҡ„жҗңзҙўиҢғејҸеҮәеҸ‘пјҢеҜ№еӨ§жЁЎеһӢзҡ„дёӢдёҖдёӘиҰҒжұӮе°ұжҳҜпјҢдёҚд»…иғҪеӣһзӯ”й—®йўҳпјҢиҖҢдё”иҰҒжңүи®Ёи®әе’Ңдәүиҫ©зҡ„иғҪеҠӣгҖӮеңЁдәәе·ҘжҷәиғҪйўҶеҹҹпјҢеҜ№дәҺжҖқиҫ©пјҲargumentationпјүзҡ„з ”з©¶дёҖзӣҙжҳҜдёҖдёӘйҮҚиҰҒзҡ„йўҶеҹҹпјҢеҰӮдҪ•и®©жңәеҷЁжЁЎеһӢе…·жңүжҖқиҫЁзҡ„иғҪеҠӣпјҢеҸҜд»ҘдёҺдәәиҝӣиЎҢи®Ёи®әпјҢеҚідёҚд»…иғҪеӣһзӯ”й—®йўҳпјҢиҝҳиғҪжҸҗеҮәй—®йўҳпјҢ并еҜ№дәәзҡ„еӣһзӯ”дҪңеҮәеҲӨж–ӯгҖҒиҜ„д»·е’Ңеӣһеә”гҖӮиҝҷж ·зҡ„жҖқиҫЁиғҪеҠӣзҡ„е®һзҺ°иҰҒжұӮжЁЎеһӢзҡ„жҖқз»ҙдёҚд»…жңүжј”з»Һзҡ„иғҪеҠӣпјҢиҖҢдё”иҰҒжңүдёҖдёӘеҶ…еңЁзҡ„вҖңдё–з•ҢжЁЎеһӢвҖқпјҢд»ҺиҖҢиғҪеӨҹеҜ№вҖңеӣһзӯ”вҖқиҝӣиЎҢеҲӨж–ӯе’Ңи®әиҜҒпјҢиҝҷе°ҶдҪҝжЁЎеһӢд»ҺвҖңжҗңзҙўиҢғејҸвҖқиҝӣеҢ–еҲ°дёҖдёӘд»Ҙйҳҗиҝ°и§ӮзӮ№дёәзӣ®ж Үзҡ„вҖңд»·еҖјиҢғејҸвҖқгҖӮиҝҷж ·зҡ„дё–з•ҢжЁЎеһӢзҡ„е»әз«ӢеҜ№дәҺз®—жі•жқҘиҜҙпјҢиҰҒжұӮе…¶дёҚд»…е…·жңүеӯҰд№ е’ҢжҺЁзҗҶзҡ„иғҪеҠӣпјҢжӣҙйңҖиҰҒжңүи®°еҝҶгҖҒиЎҢдёәзӣ®ж Үзҡ„е»әз«ӢпјҢд»·еҖјзҡ„иЎЎйҮҸдёҺеҲӨж–ӯд»ҘеҸҠиЎҢдёәжҺ§еҲ¶зҡ„иғҪеҠӣгҖӮеңЁиҝҷж ·зҡ„иҢғејҸдёӢпјҢеӯҰд№ зҡ„ж–№ејҸе’ҢжҺЁзҗҶзҡ„жЁЎејҸд№ҹдјҡеҸ‘з”ҹйҮҚеӨ§зҡ„ж”№еҸҳпјҢе°ҶдёҚеҶҚеҸҜд»Ҙиў«еҪ’з»“дёәвҖңйў„жөӢдёӢдёҖдёӘжңүеҸҜиғҪзҡ„ж•°жҚ®е…ғвҖқиҝҷд№Ҳз®ҖеҚ•зҡ„еӯҰд№ е’Ңз”ҹжҲҗжЁЎејҸдәҶгҖӮе®һйҷ…дёҠпјҢиҝҷж ·зҡ„еҗ‘вҖңд»·еҖјиҢғејҸвҖқзҡ„иҝӣеҢ–пјҢд№ҹжҳҜе®һзҺ°жҲ‘们д»ҠеӨ©еёёи®Ізҡ„вҖңе…·иә«жҷәиғҪвҖқзҡ„еҹәзЎҖгҖӮе…·иә«жҷәиғҪејәи°ғжҷәиғҪдҪ“йҖҡиҝҮдёҺзҺҜеўғзҡ„дәӨдә’иҺ·еҸ–дҝЎжҒҜгҖҒзҗҶи§Јй—®йўҳгҖҒдҪңеҮәеҶізӯ–并е®һзҺ°иЎҢеҠЁпјҢд»ҺиҖҢдә§з”ҹжҷәиғҪиЎҢдёәе’ҢйҖӮеә”жҖ§гҖӮжңүдәҶж”ҜжҢҒвҖңд»·еҖјиҢғејҸвҖқзҡ„еӨ§жЁЎеһӢпјҢжҲ‘们жүҚеҸҜд»Ҙжңүж•Ҳең°е®һзҺ°еҜ№зҺҜеўғзҡ„зҗҶ解并йҖҡиҝҮе…¶еҹәдәҺдё–з•ҢжЁЎеһӢзҡ„д»·еҖјиЎЎйҮҸжқҘдҪңеҮәеҶізӯ–гҖҒе®һзҺ°иЎҢеҠЁгҖӮ з ”з©¶вҖңеҲӣйҖ иҢғејҸвҖқпјҢдҪҝжңәеҷЁе…·жңүдәәзұ»зҒөжҖ§гҖӮеӨ§жЁЎеһӢзҡ„еҸ‘еұ•жҳҜд»Һж•°жҚ®еӯҰд№ жЁЎеһӢгҖҒжЁЎеһӢз”ҹжҲҗж•°жҚ®зҡ„еҫӘзҺҜеҫҖеӨҚдёӯпјҢдёҚж–ӯд»ҺдёҖдёӘеұӮж¬ЎиҝҲеҗ‘жӣҙй«ҳзҡ„еұӮж¬ЎгҖӮдёҚз®ЎжҳҜжіЁе…Ҙжғ…ж„ҹпјҢиҝҳжҳҜиһҚе…ҘжҖқиҫЁпјҢжҜҸдёҖеұӮзҡ„еҫӘзҺҜйғҪжҳҜеңЁиҜӯиЁҖжЁЎеһӢдёӯж·»еҠ дәәжҖ§зҡ„зҗҶи§ЈпјҢдҪҝжҲ‘们еңЁиҜӯиЁҖжЁЎеһӢзҡ„е»әз«ӢдёҠдёҚж–ӯең°йҖјиҝ‘дәәзұ»зҡ„иҜӯиЁҖе’ҢжҖқз»ҙпјҢи®©жңәеҷЁзҡ„иҜӯиЁҖжЁЎејҸйҖҗжёҗдёҺдәәзұ»зӣёдёҖиҮҙгҖӮж—©еңЁ2013е№ҙпјҢжң¬иҪ®дәәе·ҘжҷәиғҪжөӘжҪ®жқҘдёҙеүҚеӨ•пјҢзҫҺеӣҪдёҠжҳ дәҶдёҖйғЁи®Іиҝ°еңЁдёҚиҝңзҡ„жңӘжқҘдәәдёҺдәәе·ҘжҷәиғҪжңәеҷЁзӣёзҲұзҡ„科幻зҲұжғ…з”өеҪұгҖҠеҘ№гҖӢпјҲHerпјүгҖӮдё»дәәе…¬иҘҝеҘҘеӨҡжҳҜдёҖдҪҚдҝЎд»¶ж’°еҶҷдәәпјҢиғҪеҶҷеҮәж„ҹдәәиӮәи…‘зҡ„дҝЎд»¶гҖӮд»–еҲҡз»“жқҹдёҺеҰ»еӯҗзҡ„е©ҡ姻пјҢиҝҳжІЎиө°еҮәз—ӣиӢҰзҡ„йҳҙеҪұгҖӮдёҖж¬ЎеҒ¶з„¶зҡ„жңәдјҡи®©д»–жҺҘи§ҰеҲ°жңҖж–°зҡ„дәәе·ҘжҷәиғҪзі»з»ҹOS1пјҢе®ғзҡ„еҢ–иә«иҗЁжӣјиҺҺжӢҘжңүиҝ·дәәзҡ„еЈ°зәҝпјҢжё©жҹ”дҪ“иҙҙиҖҢеҸҲе№Ҫй»ҳйЈҺи¶ЈгҖӮиҘҝеҘҘеӨҡдёҺиҗЁжӣјиҺҺеҫҲеҝ«еҸ‘зҺ°д»–们жҳҜеҰӮжӯӨжҠ•зјҳпјҢиҖҢдё”еӯҳеңЁеҜ№еҪјжӯӨзҡ„йңҖжұӮдёҺж¬ІжңӣпјҢдәәжңәеҸӢи°ҠжңҖз»ҲеҸ‘еұ•дёәдёҖж®өеҘҮејӮзҲұжғ…гҖӮиҝҷдёӘ科幻зүҮз”ҹеҠЁең°еұ•зӨәдәҶдәәзұ»е’ҢдёҖдёӘжңүиҜӯиЁҖиғҪеҠӣзҡ„жңәеҷЁд№Ӣй—ҙзҡ„е…ізі»пјҢд№ҹеҜ№еҗҺеӣҫзҒөж—¶д»ЈиҜӯиЁҖжЁЎеһӢзҡ„еҸ‘еұ•дҪңдәҶдёҖдёӘеҪўиұЎзҡ„жҸҸиҝ°пјҡжңәеҷЁзҡ„иҜӯиЁҖжЁЎеһӢдјҡдёҺдәәж— зјқдәӨжөҒпјҢдјҡзҗҶи§ЈжҲ‘们зҡ„иҜӯиЁҖгҖҒж„ҹжғ…е’ҢиҜӯеўғпјҢе…¶дёҺжҲ‘们зҡ„дәӨжөҒд№ҹдјҡи¶ҠжқҘи¶ҠжңүвҖңдәәжҖ§вҖқгҖӮиөӢдәҲжңәеҷЁжЁЎеһӢд»ҘдәәжҖ§зҡ„е…үиҫүпјҢе°ұжҳҜз ”з©¶еӨ§жЁЎеһӢзҡ„з»ҲжһҒзӣ®ж ҮгҖӮдј—жүҖе‘ЁзҹҘпјҢдәәжҖ§жңҖзІҫеҪ©зҡ„йғЁеҲҶжҳҜеҲӣйҖ еҠӣгҖӮеӣ жӯӨпјҢжҲ‘们еә”иҜҘз ”з©¶еӨ§жЁЎеһӢзҡ„вҖңеҲӣйҖ иҢғејҸвҖқпјҢи®©жңәеҷЁд№ҹе…·жңүдәәзұ»зҡ„зҒөжҖ§гҖӮ 2022е№ҙз”ұAIз”ҹжҲҗзҡ„з”»дҪңвҖ”вҖ”гҖҠз©әй—ҙжӯҢеү§йҷўгҖӢпјҲThéâtre D'opГ©ra SpatialпјүеңЁзҫҺеӣҪ科зҪ—жӢүеӨҡе·һеҚҡи§Ҳдјҡзҡ„вҖңж•°еӯ—иүәжңҜвҖқзұ»еҲ«зҫҺжңҜжҜ”иөӣдёӯиҺ·еҫ—第дёҖеҗҚгҖӮиҜҘз”»дҪңзҡ„еҲӣдҪңиҖ…жҳҜ39еІҒзҡ„зҫҺеӣҪжёёжҲҸи®ҫи®ЎеёҲжқ°жЈ®В·иүҫдјҰпјҲJason AllenпјүпјҢд»–дҪҝз”Ёж–Үжң¬з”ҹжҲҗеӣҫеғҸзЁӢеәҸMidjourneyпјҢз»ҸиҝҮиҝ‘еҚғж¬Ўи°ғж•ҙгҖҒиҖ—иҙ№иҝ‘дёүзҷҫдёӘе°Ҹж—¶иҝӣиЎҢдҝ®ж”№е®Ңе–„пјҢз»ҳжҲҗдәҶиҝҷдёӘдҪңе“ҒгҖӮMidjourneyж №жҚ®з”ЁжҲ·зҡ„ж–Үеӯ—жҸҸиҝ°з”ҹжҲҗйҖјзңҹзҡ„еӣҫеғҸпјҢжҜҸж¬ЎеҲӣдҪңиҖ—ж—¶зәҰдёҖеҲҶй’ҹгҖӮеңЁеҲӣдҪңиҖ…з»ҷе®ҡдёҖдёӘеҜ№жӯҢеү§йҷўе’ҢеӨ©е Ӯзҡ„жҸҸиҝ°д№ӢеҗҺпјҢжңәеҷЁеҮӯеҖҹиҮӘе·ұеҜ№еӨ©е Ӯзҡ„зҗҶи§Јз”ҹжҲҗдәҶдёҖе№…дҪңе“ҒгҖӮеңЁиҝҷдёӘдҪңе“ҒдёӯпјҢжҲ‘们зңӢеҲ°дәҶжңәеҷЁдёҺдәәзұ»еҜ№еӨ©е Ӯе№»жғізҡ„е…ұеҗҢд№ӢеӨ„пјҢдҪҶеҗҢж—¶жңәеҷЁеҸҲиөӢдәҲе®ғзӢ¬зү№зҡ„жғіиұЎеҠӣпјҢз”»еҮәдәҶи¶…и¶Ҡд№ жғҜжҖ§жҖқз»ҙзҡ„еӨ©е ӮгҖӮеҜ№дәҺжңәеҷЁзҡ„иҝҷз§ҚиғҪеҠӣпјҢжҲ‘们йҖҡеёёз§°д№ӢдёәвҖңе№»жҖқвҖқпјҲhallucinationsпјүгҖӮ еңЁж–Үжң¬з”ҹжҲҗдёӯпјҢиҝҷж ·зҡ„е№»жҖқиў«и®ӨдёәжҳҜдёӘдёҘйҮҚзҡ„й—®йўҳпјҢжҳҜжЁЎеһӢиҰҒе…ӢжңҚзҡ„вҖңжҜӣз—…вҖқпјҢз”ҡиҮіеёёеёёиў«и§ҶдёәвҖңдёҖжң¬жӯЈз»Ҹзҡ„иғЎиҜҙе…«йҒ“вҖқгҖӮд№ӢжүҖд»ҘеҜ№е…¶жңүиҝҷж ·зҡ„зңӢжі•пјҢжӯЈжҳҜеҮәдәҺжҲ‘们еҜ№еӨ§жЁЎеһӢжҗңзҙўиҢғејҸзҡ„д№ жғҜжҖ§зҗҶи§Је’ҢдҪҝз”ЁгҖӮеңЁжҗңзҙўиҢғејҸдёӢпјҢеҶ…е®№зҡ„з”ҹжҲҗеёёеёёжҳҜжңүдәӢе®һдҫқжҚ®зҡ„пјҢдёҺдәӢе®һзӣёз¬ҰдёҺеҗҰжҳҜиЎЎйҮҸеҶ…е®№иҙЁйҮҸзҡ„ж ҮеҮҶпјҢдёҚ然е°ұжҳҜвҖңиғЎиҜҙе…«йҒ“вҖқпјӣдҪҶжҳҜеҰӮжһңжҲ‘们иө°еҮәдј з»ҹзҡ„еӨ§жЁЎеһӢжҗңзҙўиҢғејҸзҡ„жҖқз»ҙпјҢжҠҠе®ғзңӢжҲҗжҳҜдёҖдёӘжңүеҲӣдҪңиғҪеҠӣзҡ„з”ҹжҲҗзі»з»ҹпјҢйӮЈд№Ҳе№»жҖқе°ұжҳҜдёҖдёӘйқһеёёйҮҚиҰҒзҡ„иғҪеҠӣдәҶгҖӮд»Ҙ笔иҖ…еӣўйҳҹжӯЈеңЁејҖеҸ‘зҡ„дёҖдёӘз”ҹжҲҗзі»з»ҹдёәдҫӢпјҢжҲ‘们з»ҷзі»з»ҹжҸҗдҫӣеҮ е№…з…§зүҮжҲ–еҮ е№…еӣҫз”»еҗҺпјҢжңәеҷЁеҸҜд»Ҙз”ҹеҠЁең°еҶҷеҮәдёҖзҜҮдёҺжҸҗдҫӣзҡ„еӣҫзүҮзӣёеҢ№й…Қзҡ„ж•Јж–ҮгҖӮеңЁиҝҷж ·зҡ„еҲӣдҪңдёӯпјҢйҮҚиҰҒзҡ„дёҚжҳҜдёҺдәӢе®һзҡ„дёҖиҮҙжҖ§пјҢиҖҢжҳҜеҶ…е®№дёҺжүҖз»ҷеҮәеӣҫзүҮзҡ„ж„Ҹеўғзӣёеҗ»еҗҲпјҢжҚўеҸҘиҜқиҜҙпјҢиҝҷж ·зҡ„еҗ»еҗҲеәҰе°ұжҳҜжҲ‘们иҰҒжұӮзҡ„вҖңдёҖжң¬жӯЈз»ҸвҖқгҖӮеҸӘиҰҒз¬ҰеҗҲйҖ»иҫ‘пјҢе°ұдёҚдјҡеҜ№е…¶жңүдёҺдәӢе®һзӣёз¬Ұзҡ„иҰҒжұӮпјӣеҸӘиҰҒдёҚиҝқиғҢеёёиҜҶгҖҒдёҚиҝқиғҢйҖ»иҫ‘пјҢе°ұдёҚдјҡеҜ№е…¶жңүвҖңиғЎиҜҙе…«йҒ“вҖқзҡ„иҙЈйҡҫгҖӮеҰӮжӯӨдёҖжқҘпјҢе°ұжңүдәҶеӨ§жЁЎеһӢдҪҝз”Ёзҡ„вҖңеҲӣйҖ иҢғејҸвҖқгҖӮеҜ№дәҺеңЁеҲӣйҖ иҢғејҸдёӢзҡ„еӨ§жЁЎеһӢиҖҢиЁҖпјҢйҮҚиҰҒзҡ„жҳҜз ”з©¶еҗ„з§Қе№»жҖқзҡ„еҪўејҸе’ҢжҖ§иҙЁпјҢд»ҘеҸҠиЎЎйҮҸеҗ„з§Қе№»жҖқзҡ„еҲӣйҖ жҖ§гҖҒеҗҜеҸ‘жҖ§е’Ңе…¶д»–зү№жҖ§зҡ„ж ҮеҮҶеҸҠиҜ„д»·ж–№жі•гҖӮд»Ҙ笔иҖ…еӣўйҳҹжӯЈеңЁи®ҫи®Ўзҡ„з”ЁеӨ§жЁЎеһӢжқҘеҲӣдҪңз«ҘиҜқзҡ„е·ҘдҪңдёәдҫӢпјҢеӨ§жЁЎеһӢзҡ„е№»жҖқжҳҜдёҖдёӘйқһеёёйҮҚиҰҒзҡ„иғҪеҠӣпјҢжӯЈжҳҜеҜ№е№»жҖқиғҪеҠӣзҡ„еҗҲзҗҶејҖеҸ‘пјҢжүҚиғҪеӨҹдёәз«ҘиҜқеҲӣйҖ еҮәе…·жңүеҗҜиҝӘжҖ§е’Ңи¶Је‘іжҖ§зҡ„еҶ…е®№гҖӮ еҜ№еӨ§жЁЎеһӢеҸ‘еұ•зҡ„жңӘжқҘеұ•жңӣ
дҪңдёәжҖ»з»“пјҢжҲ‘жғіеӣһйЎҫдёҖдёӢеӣҫзҒөе…ідәҺжңәеҷЁжҷәиғҪзҡ„жҖқиҖғгҖӮеӣҫзҒөеңЁ1950е№ҙеҸ‘иЎЁзҡ„и‘—еҗҚи®әж–ҮгҖҠи®Ўз®—жңәеҷЁдёҺжҷәиғҪгҖӢпјҲComputing Machinery and IntelligenceпјүдёӯпјҢжҸҗеҮәдәҶжңәеҷЁиғҪеҗҰжҖқз»ҙзҡ„е‘ҪйўҳпјҢи®ӨдёәеҸӘиҰҒжңәеҷЁеңЁеҜ№иҜқдёҠе’ҢдәәжІЎжңүжҳҺжҳҫе·®еҲ«пјҢе°ұжҳҜе…·жңүжҷәиғҪзҡ„пјҢжӯӨеҚіеҗҺдәәжүҖз§°зҡ„вҖңеӣҫзҒөжөӢиҜ•вҖқгҖӮд»ҠеӨ©зҡ„еӨ§жЁЎеһӢе·Із»ҸеҲқжӯҘе…·жңүдәҶиҝҷж ·зҡ„иғҪеҠӣпјҢеҸҜд»Ҙе®һзҺ°вҖңдәәй—®жңәзӯ”вҖқгҖӮиҝҷж ·зңӢжқҘпјҢдјјд№ҺеҸҜд»ҘиҜҙжҲ‘们жңүдәҶй—®йўҳзҡ„зӯ”жЎҲгҖӮдҪҶжҳҜпјҢдәәзҡ„иҜӯиЁҖиғҪеҠӣиҝңдёҚеҸӘжҳҜй—®зӯ”пјҢжҲ‘们зҡ„еүҚи·ҜиҝҳеҫҲй•ҝгҖӮеӣҫзҒөд№ҹеңЁд»–зҡ„ж–Үз« дёӯ规еҲ’дәҶдёҖжқЎйҒ“и·ҜпјҢи®ӨдёәеҸҜд»Ҙзј–еҲ¶дёҖдёӘвҖңе„ҝз«ҘзЁӢеәҸвҖқпјҢеҜ№е…¶иҝӣиЎҢж•ҷиӮІпјҢд»ҘдҪҝе…¶иҫҫеҲ°жҲҗдәәзҡ„жҷәеҠӣж°ҙе№ігҖӮдҪҶеңЁз¬”иҖ…зңӢжқҘпјҢйүҙдәҺдәәзұ»ж•ҷиӮІе’ҢжңәеҷЁеӯҰд№ зҡ„вҖңдёӨжһҒжҖ§вҖқпјҢиҝҷжқЎи·Ҝдјјд№ҺиҰҒеҸҚзқҖиө°дәҶгҖӮ еҰӮеӣҫ1жүҖзӨәпјҢжҲ‘们еҜ№дәҺжңәеҷЁзҡ„ж•ҷиӮІе’ҢеҜ№дәҺдәәзұ»зҡ„ж•ҷиӮІе®һи·өдјјд№ҺжӯЈеҘҪжҳҜзӣёеҸҚзҡ„гҖӮеҜ№дәәзұ»иҖҢиЁҖпјҢжҲ‘们еңЁе№је„ҝж•ҷиӮІйҳ¶ж®өпјҢдёҚж–ӯең°еҗҜеҸ‘еӯ©еӯҗеҜ№ж–°дәӢзү©зҡ„еҘҪеҘҮпјҢд»ҺиҖҢе»әз«Ӣиө·еӯ©еӯҗеҜ№з”ҹжҙ»е’ҢзӨҫдјҡзҡ„еёёиҜҶпјӣе°ҸеӯҰж•ҷиӮІзҡ„зӣ®ж Үдё»иҰҒдёҚжҳҜзҹҘиҜҶз§ҜзҙҜпјҢиҖҢжҳҜд»·еҖји§Ӯеҹ№е…»пјҢи®©еӯ©еӯҗд»Һеҗ„ж–№йқўеӯҰеҲ°зӨҫдјҡдёҠзҡ„еҜ№дёҺй”ҷгҖҒзңҹдёҺеҒҮгҖҒе–„дёҺжҒ¶пјӣдёӯеӯҰж•ҷиӮІејҖе§Ӣе»әз«ӢзҹҘиҜҶдҪ“зі»зҡ„еҹәзЎҖпјӣеӨ§еӯҰж•ҷиӮІжүҚжҳҜдё“й—ЁеҢ–зҡ„зҹҘиҜҶеҹ№е…»гҖӮжңүдәҶиҝҷдәӣпјҢдёҖдёӘдәәжүҚиғҪеңЁзӨҫдјҡе®һи·өдёӯжҺҘеҸ—зӨҫдјҡзҡ„еҶҚж•ҷиӮІпјҢе»әз«ӢиҮӘе·ұзҡ„зҹҘиҜҶдҪ“зі»пјҢеҪўжҲҗжҲҗдәәжҷәеҠӣгҖӮиҖҢжңәеҷЁеӯҰд№ зҡ„иҝҮзЁӢжӯЈеҘҪжҳҜеҸҚиҝҮжқҘзҡ„гҖӮжҲ‘们дёҖејҖе§Ӣе°ұе–Ӯз»ҷдәҶжңәеҷЁиҝҷдёӘдё–з•Ңзҡ„е…ЁйғЁж•°жҚ®пјҢжҠҠе®ғеҺӢзј©жҲҗдёҖдёӘйҖҡз”Ёзҡ„йў„и®ӯз»ғжЁЎеһӢпјҢзҗҶи®әдёҠпјҢе®ғеҸҜд»Ҙи®ІжүҖжңүз¬ҰеҗҲиҜӯиЁҖзү№жҖ§зҡ„иҜқпјӣ第дәҢжӯҘпјҢжүҚејҖе§ӢеҜ№иҝҷж ·зҡ„дёҖдёӘйў„и®ӯз»ғжЁЎеһӢиҝӣиЎҢеҫ®и°ғпјҢеӯҰд№ еҗ„дёӘйўҶеҹҹзҡ„зҹҘиҜҶпјҲеҫ®и°ғпјүе’Ңдәәзұ»зҡ„иЎЁиҫҫж–№ејҸпјҲеҜ№йҪҗпјүпјҢдҪҝе®ғз¬ҰеҗҲжҲ‘们еңЁеҗ„з§Қдё»йўҳдёӢдәӨжөҒзҡ„йңҖиҰҒпјӣжҺҘдёӢжқҘпјҢжҲ‘们жүҚеҸ‘зҺ°иҰҒи®©жңәеҷЁжңүеҲӨж–ӯзҡ„иғҪеҠӣпјҢе°ұеҝ…йЎ»и®©жңәеҷЁеӯҰд№ еҜ№дёҺй”ҷзҡ„еҲӨеҲ«пјҢдҪҝе®ғдә§з”ҹд»·еҖји§ӮпјӣзӣҙеҲ°жңҖеҗҺпјҢжҲ‘们еёҢжңӣжңәеҷЁд»ҺеӨ§йҮҸзҡ„еӯҰд№ дёӯпјҢиғҪеӨҹжҖ»з»“еҮәдёҖдёӘдё–з•ҢжЁЎеһӢпјҢдҪңдёәиҮӘе·ұзҡ„еёёиҜҶпјҢ并еңЁиҝҷж ·зҡ„еҹәзЎҖдёҠпјҢиғҪеӨҹеҜ№иҝҷдёӘдё–з•Ңдә§з”ҹеҲӣйҖ еҠӣгҖӮ

жқҘжәҗпјҡдҪңиҖ…иҮӘеҲ¶ еӣҫ1 дәәзұ»ж•ҷиӮІе’ҢжңәеҷЁеӯҰд№ зҡ„дёӨжһҒжҖ§
жӯЈжҳҜеҹәдәҺиҝҷж ·зҡ„еҜ№дәәжңәеӯҰд№ дёӨжһҒжҖ§зҡ„зҗҶи§ЈпјҢжҲ‘们еҜ№еӨ§жЁЎеһӢеҸ‘еұ•зҡ„жңӘжқҘдҪңдәҶиҝҷж ·зҡ„еұ•жңӣпјҡдёҖдёӘеҸҜд»Ҙз”ҹжҲҗиҜӯиЁҖзҡ„еӨ§жЁЎеһӢдјҡд»ҺиЎЁиҝ°еҶ…е®№зҡ„жҗңзҙўиҢғејҸиҝӣеҢ–еҲ°йҳҗиҝ°и®әиҜҒи§ӮзӮ№зҡ„д»·еҖјиҢғејҸпјҢе®ғеҸҜд»ҘеңЁеҜ№дё–з•Ңзҡ„зҗҶи§ЈдёӢдёҺдәәдәӨжөҒпјҢиҝҷж ·зҡ„зҗҶи§Јд№ҹдјҡеңЁдәӨжөҒдёӯдёҚж–ӯиҝӣеҢ–пјҢд»ҺиҖҢдҪҝеҫ—жңәеҷЁеӯҰдјҡе»әз«ӢиҮӘе·ұзҡ„д»·еҖји§ӮгҖӮиҖҢдәәе·ҘжҷәиғҪжІ»зҗҶзҡ„дёҖдёӘж №жң¬жҖ§д»»еҠЎжҳҜеҠӘеҠӣдҝқиҜҒиҝҷж ·зҡ„д»·еҖји§Ӯз¬ҰеҗҲдәәзұ»иҝӣжӯҘзҡ„иҰҒжұӮгҖӮеңЁиҝҷж ·зҡ„д»·еҖјиҢғејҸдёӢпјҢжңәеҷЁзҡ„дәәжҖ§еҢ–дјҡдёҚж–ӯеўһејәпјҢеҲӣйҖ еҠӣдјҡеҫ—еҲ°иҝӣдёҖжӯҘеҸ‘еұ•пјҢд»ҺиҖҢдҪҝе…¶е№»жҖқзҡ„иғҪеҠӣжҲҗдёәеҗҲд№Һдё–з•ҢжЁЎеһӢзҡ„жңүж„Ҹд№үзҡ„еҲӣйҖ ж–№ејҸгҖӮиҝҷж ·зҡ„еҲӣйҖ ж–№ејҸдјҡдҪҝдәәдёҺжңәеҷЁзҡ„е…ұз”ҹгҖҒе…ұеӯҳгҖҒе…ұеҲӣжҲҗдёәеҸҜиғҪпјҢеҪўжҲҗдёҖдёӘеҙӯж–°зҡ„зӨҫдјҡеҪўжҖҒгҖӮиҖҢдәәе·ҘжҷәиғҪжІ»зҗҶзҡ„еҸҰдёҖдёӘж №жң¬жҖ§зҡ„д»»еҠЎе°ұжҳҜдёәиҝҷж ·зҡ„зӨҫдјҡе»әз«Ӣж–°зҡ„秩еәҸпјҢдҪҝдёҖдёӘеҜ№дё–з•ҢжңүзҗҶи§ЈгҖҒжңүд»·еҖјгҖҒжңүеҲӨж–ӯзҡ„еӨ§жЁЎеһӢдҪңдёәдәәи„‘зҡ„延伸пјҢеҸҜд»Ҙжңүе…¶иЎҢдёәйҖүжӢ©зҡ„жӯЈзЎ®еҺҹеҲҷе’ҢжңәеҲ¶пјҢиҝҷж ·жҲ‘们讲зҡ„е…·иә«жҷәиғҪжүҚдјҡзңҹжӯЈеҲ°жқҘпјҢеңЁдёҖдёӘдәәжңәдәҢе…ғзҡ„зӨҫдјҡйҮҢдёәжҲ‘们жңҚеҠЎгҖӮ 2024е№ҙ5жңҲ14ж—ҘпјҢзҫҺеӣҪOpenAIе®ЈеёғдәҶе…ЁиғҪеӨ§жЁЎеһӢGPT-4oпјҢе®ғеңЁеӨ§жЁЎеһӢзҡ„й—®зӯ”иғҪеҠӣж–№йқўпјҢеҠ е…ҘдәҶи§Ҷи®ҜеҠҹиғҪпјҢеҸҜд»Ҙж„ҹзҹҘиҜӯиЁҖзҺҜеўғпјҢиҝӣиЎҢе®һж—¶гҖҒиҮӘ然гҖҒж»Ўи¶іиҜӯеўғзҡ„иҜӯйҹіеҜ№иҜқпјҢ并且иғҪжҚ•жҚүжғ…з»ӘгҖҒжЁЎжӢҹжғ…з»ӘпјҢиҝҷжҳҜеӨ§жЁЎеһӢеҗ‘дәәжҖ§еҢ–еүҚиҝӣзҡ„йҮҚиҰҒдёҖжӯҘгҖӮеҪ“еүҚпјҢеӨ§жЁЎеһӢеҸ‘еұ•зҡ„йҖҹеәҰи¶ҠжқҘи¶Ҡеҝ«пјҢиҖҢеҜ№е…¶еҸ‘еұ•йҒ“и·Ҝе’Ңж–№еҗ‘зҡ„жҠҠжҸЎе°ӨдёәйҮҚиҰҒгҖӮжҲ‘们еҝ…йЎ»е»әжһ„иҮӘе·ұзҡ„жҠҖжңҜзҗҶжғіпјҢеҜ№дәәе·ҘжҷәиғҪзҡ„еҸ‘еұ•пјҢеҸҠе…¶жҺЁеҠЁдәәзұ»еҸ‘еұ•иҝӣжӯҘзҡ„еүҚжҷҜе……ж»ЎдҝЎеҝғпјҢдёҚз•ҸиҜ•й”ҷгҖҒеӨ§иғҶеҲӣж–°пјҢиө°еҮәдёҖжқЎжҲ‘们иҮӘе·ұзҡ„еӨ§жЁЎеһӢйҒ“и·ҜгҖӮпјҲжқҘжәҗпјҡеӯҰжңҜеүҚжІҝпјү
| 
 еҶңдёҡж–°иҙЁз”ҹдә§еҠӣпјҡеҶ…ж¶ө
еҶңдёҡж–°иҙЁз”ҹдә§еҠӣпјҡеҶ…ж¶ө еҲҳдҝҠжқ°зӯүпјҡжһ„е»әйҖӮеә”еҶң
еҲҳдҝҠжқ°зӯүпјҡжһ„е»әйҖӮеә”еҶң 11жңҲе…Ёзҗғи°·зү©еёӮеңәдёҺиҙё
11жңҲе…Ёзҗғи°·зү©еёӮеңәдёҺиҙё з®Ўж¶ӣзӯүпјҡпјҡдәәж°‘еёҒжұҮзҺҮ
з®Ўж¶ӣзӯүпјҡпјҡдәәж°‘еёҒжұҮзҺҮ й’ҹжӯЈз”ҹпјҡеҗ‘е®ҢжҲҗйў„з®—зӣ®
й’ҹжӯЈз”ҹпјҡеҗ‘е®ҢжҲҗйў„з®—зӣ® жқҺиҝ…йӣ·пјҡжҳҺе№ҙиҙўж”ҝиөӨеӯ—
жқҺиҝ…йӣ·пјҡжҳҺе№ҙиҙўж”ҝиөӨеӯ— еј зәўе®Үпјҡжһ„е»әе…·жңүдёӯеӣҪ
еј зәўе®Үпјҡжһ„е»әе…·жңүдёӯеӣҪ ж—әеӯЈдёҚж—ә еҪ“еүҚз”ҹзҢӘеёӮ
ж—әеӯЈдёҚж—ә еҪ“еүҚз”ҹзҢӘеёӮ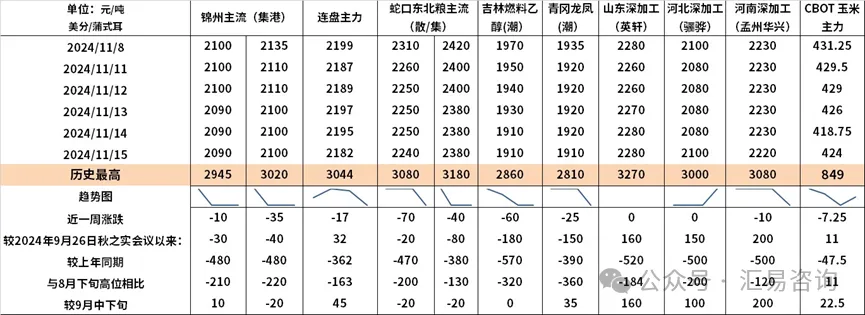 д»ҺеҪ“еүҚеӣҪеҶ…зҺүзұіеёӮеңәең°
д»ҺеҪ“еүҚеӣҪеҶ…зҺүзұіеёӮеңәең° з®Ўж¶ӣпјҡзү№жң—жҷ®еӣһеҪ’еҜ№дёӯ
з®Ўж¶ӣпјҡзү№жң—жҷ®еӣһеҪ’еҜ№дёӯ д»ҺеўғеӨ–з»ҸйӘҢзңӢиӮЎеёӮе№іеҮҶ
д»ҺеўғеӨ–з»ҸйӘҢзңӢиӮЎеёӮе№іеҮҶ







 еҸ‘иЎЁдәҺ 2024-7-25 09:40:13
еҸ‘иЎЁдәҺ 2024-7-25 09:40:13
 жҸҗеҚҮеҚЎ
жҸҗеҚҮеҚЎ зҪ®йЎ¶еҚЎ
зҪ®йЎ¶еҚЎ
 еҶңдёҡж–°иҙЁз”ҹдә§еҠӣпјҡеҶ…ж¶өдёҺеӨ–延гҖҒжҪңеҠӣдёҺжҢ‘жҲҳе’ҢеҸ‘еұ•жҖқи·Ҝ
еҶңдёҡж–°иҙЁз”ҹдә§еҠӣпјҡеҶ…ж¶өдёҺеӨ–延гҖҒжҪңеҠӣдёҺжҢ‘жҲҳе’ҢеҸ‘еұ•жҖқи·Ҝ еҰӮдҪ•жһ„е»әејҳжү¬ж•ҷиӮІе®¶зІҫзҘһзҡ„жңәеҲ¶дҪ“зі»пјҹжҠҠжҸЎеҘҪ
еҰӮдҪ•жһ„е»әејҳжү¬ж•ҷиӮІе®¶зІҫзҘһзҡ„жңәеҲ¶дҪ“зі»пјҹжҠҠжҸЎеҘҪ иҙўж”ҝйғЁпјҡжҸҗеүҚдёӢиҫҫ566дәҝе…ғпјҒ
иҙўж”ҝйғЁпјҡжҸҗеүҚдёӢиҫҫ566дәҝе…ғпјҒ зҺӢдәҡеҚҺпјҡд»Ҙжңүж•ҲжІ»зҗҶжҺЁиҝӣд№Ўжқ‘е…ЁйқўжҢҜе…ҙ
зҺӢдәҡеҚҺпјҡд»Ҙжңүж•ҲжІ»зҗҶжҺЁиҝӣд№Ўжқ‘е…ЁйқўжҢҜе…ҙ еҘҪз”ҹжҖҒдәҰжңүвҖңеҘҪд»·й’ұвҖқ зӨҫдјҡиө„жң¬йҰ–ж¬ЎеҸӮдёҺж°ҙ
еҘҪз”ҹжҖҒдәҰжңүвҖңеҘҪд»·й’ұвҖқ зӨҫдјҡиө„жң¬йҰ–ж¬ЎеҸӮдёҺж°ҙ


