马дёҠжіЁеҶҢе…ҘдјҡпјҢз»“дәӨ专家еҗҚжөҒпјҢдә«еҸ—иҙөе®ҫеҫ…йҒҮпјҢи®©дәӢдёҡз”ҹжҙ»еҸҢиөўгҖӮ
жӮЁйңҖиҰҒ зҷ»еҪ• жүҚеҸҜд»ҘдёӢиҪҪжҲ–жҹҘзңӢпјҢжІЎжңүеёҗеҸ·пјҹз«ӢеҚіжіЁеҶҢ


x
жһ—з§ҖиҠ№пјҲеҺҰй—ЁеӨ§еӯҰзҹҘиҜҶдә§жқғз ”з©¶йҷўйҷўй•ҝпјү
01 й—®йўҳзҡ„жҸҗеҮә еҪ“еүҚпјҢж–°дёҖиҪ®з§‘жҠҖйқ©е‘Ҫе’Ңдә§дёҡеҸҳйқ©ж·ұе…ҘеҸ‘еұ•пјҢж•°жҚ®иҰҒзҙ жҳҜж•°еӯ—з»ҸжөҺж·ұеҢ–еҸ‘еұ•зҡ„ж ёеҝғеј•ж“ҺпјҢж•°жҚ®еҜ№жҸҗй«ҳз”ҹдә§ж•ҲзҺҮзҡ„д№ҳж•°дҪңз”ЁдёҚж–ӯеҮёжҳҫпјҢжҲҗдёәжңҖе…·ж—¶д»Јзү№еҫҒзҡ„з”ҹдә§иҰҒзҙ гҖӮ然иҖҢпјҢж•°жҚ®жҪңеҠӣеҸ‘жҢҘеҝ…然е»әз«ӢеңЁж•°жҚ®и§„жЁЎйӣҶиҒҡе’ҢзӨҫдјҡеҢ–еҲ©з”Ёзҡ„еҹәзЎҖд№ӢдёҠпјҢжө·йҮҸж•°жҚ®з”ҹдә§иҖ…гҖҒеӨ„зҗҶиҖ…е’ҢеҲ©з”ЁиҖ…д№Ӣй—ҙзҡ„жңүж•ҲеҚҸдҪңжҳҜвҖңж•°еӯ—еј•ж“ҺвҖқеҗҜеҠЁзҡ„е…ій”®гҖӮеӣ жӯӨпјҢж•°жҚ®зҡ„з•…йҖҡиҺ·еҸ–жҳҜе……еҲҶйҮҠж”ҫж•°жҚ®иҰҒзҙ д»·еҖјгҖҒжҝҖжҙ»ж•°жҚ®иҰҒзҙ жҪңиғҪзҡ„еҝ…иҰҒжқЎд»¶пјҢдёәж•°жҚ®иҺ·еҸ–е’ҢеҲ©з”ЁжҸҗдҫӣе®Ңе–„й«ҳж•Ҳзҡ„жІ»зҗҶжЎҶжһ¶жҳҜжі•жІ»е»әи®ҫзҡ„йҮҚиҰҒеҶ…е®№гҖӮ дё–з•Ңеҗ„дё»иҰҒжі•еҹҹе·Ізә·зә·еҗҜеҠЁж•°жҚ®з«Ӣжі•жІ»зҗҶиҝӣзЁӢпјҢдҪҶжҖ»дҪ“е°ҡеӨ„дәҺз ”з©¶е’Ңж‘ёзҙўйҳ¶ж®өгҖӮжҲ‘еӣҪд№ҹе·Іе…ҲеҗҺйўҒеёғгҖҠдёӯеҚҺдәәж°‘е…ұе’ҢеӣҪж•°жҚ®е®үе…Ёжі•гҖӢе’ҢгҖҠдёӯеҚҺдәәж°‘е…ұе’ҢеӣҪдёӘдәәдҝЎжҒҜдҝқжҠӨжі•гҖӢпјҢеӣһеә”еҗ„з•ҢеҜ№ж•°жҚ®е®үе…ЁгҖҒдёӘдәәдҝЎжҒҜж•°жҚ®дҝқжҠӨзӯүеҲ©зӣҠзҡ„е…іеҲҮпјҢеҗҢж—¶пјҢдёҺж•°жҚ®иҺ·еҸ–е’ҢжөҒйҖҡеҲ©з”Ёзӣёе…ізҡ„еҲ©зӣҠеҲҶй…Қ规еҲҷд»ҚеңЁй…қй…ҝд№ӢдёӯгҖӮ2022е№ҙ6жңҲпјҢд№ иҝ‘е№іжҖ»д№Ұи®°еңЁдё»жҢҒеҸ¬ејҖдёӯеӨ®е…Ёйқўж·ұеҢ–ж”№йқ©е§”е‘ҳдјҡ第дәҢеҚҒе…ӯж¬Ўдјҡи®®ж—¶ејәи°ғпјҢж•°жҚ®еҹәзЎҖеҲ¶еәҰе»әи®ҫдәӢе…іеӣҪ家еҸ‘еұ•е’Ңе®үе…ЁеӨ§еұҖпјҢиҰҒз»ҙжҠӨеӣҪ家数жҚ®е®үе…ЁпјҢдҝқжҠӨдёӘдәәдҝЎжҒҜе’Ңе•Ҷдёҡз§ҳеҜҶпјҢдҝғиҝӣж•°жҚ®й«ҳж•ҲжөҒйҖҡдҪҝз”ЁгҖҒиөӢиғҪе®һдҪ“з»ҸжөҺпјҢз»ҹзӯ№жҺЁиҝӣж•°жҚ®дә§жқғгҖҒжөҒйҖҡдәӨжҳ“гҖҒ收зӣҠеҲҶй…ҚгҖҒе®үе…ЁжІ»зҗҶпјҢеҠ еҝ«жһ„е»әж•°жҚ®еҹәзЎҖеҲ¶еәҰдҪ“зі»гҖӮдјҡи®®е®Ўи®®йҖҡиҝҮгҖҠе…ідәҺжһ„е»әж•°жҚ®еҹәзЎҖеҲ¶еәҰжӣҙеҘҪеҸ‘жҢҘж•°жҚ®иҰҒзҙ дҪңз”Ёзҡ„ж„Ҹи§ҒгҖӢпјҢе…¶дё»иҰҒзӣ®ж ҮжҳҜйҖҡиҝҮжһ„е»әж•°жҚ®еҹәзЎҖеҲ¶еәҰпјҢи®©ж•°жҚ®иҰҒзҙ зҡ„иҺ·еҸ–гҖҒеҠ е·ҘгҖҒжөҒйҖҡгҖҒеҲ©з”Ёд»ҘеҸҠ收зӣҠеҲҶй…ҚзӯүиЎҢдёәжңүжі•еҸҜдҫқгҖҒжңү规еҸҜеҫӘпјҢжҺЁеҠЁж•°жҚ®иҰҒзҙ еёӮеңә规иҢғеҢ–гҖҒеҲ¶еәҰеҢ–е»әи®ҫпјҢжңҖз»Ҳе®һзҺ°ж•°жҚ®иҰҒзҙ еёӮеңәеҢ–й…ҚзҪ®ж•ҲзҺҮзҡ„жҸҗеҚҮгҖӮзӣ®еүҚеӣҪеҶ…е…ідәҺж•°жҚ®зҡ„з ”з©¶дҫ§йҮҚдәҺдҝқжҠӨпјҢиҖҢеҜ№ж•°жҚ®зҡ„иҺ·еҸ–е’ҢеҲ©з”Ёе…іжіЁдёҚи¶ігҖӮз”ұжӯӨпјҢжң¬ж–Үе°қиҜ•д»ҺйҖ»иҫ‘зҗҶжҖ§е’Ңе·Ҙе…·зҗҶжҖ§зҡ„и§’еәҰеҲҶжһҗзҫҺеӣҪгҖҒ欧зӣҹгҖҒж—Ҙжң¬зӯүжі•еҹҹж•°жҚ®дҝқжҠӨдёҺиҺ·еҸ–зҡ„еҚҸи°ғжңәеҲ¶пјҢиҜ„жһҗзҺ°жңүз«Ӣжі•е’ҢеҠЁи®®зҡ„д»·еҖјдёҺеұҖйҷҗпјҢиҝӣиҖҢд»Һи®ҫжқғи·Ҝеҫ„е’Ңйқһи®ҫжқғи·Ҝеҫ„жҺўзҙўйҖ»иҫ‘иҮӘжҙҪгҖҒе®һи·өеҸҜиЎҢзҡ„еҜ№зӯ–пјҢдёәжҲ‘еӣҪж•°жҚ®еҹәзЎҖеҲ¶еәҰзҡ„е»әжһ„дёҺе®Ңе–„жҸҗдҫӣеҸӮиҖғгҖӮ 02 еҹҹеӨ–规еҲҷжј”иҝӣпјҡд»Һдҫ§йҮҚдҝқжҠӨиҪ¬еҗ‘дҝқжҠӨдёҺеҲ©з”Ёе№іиЎЎ еңЁдј з»ҹж— еҪўиҙўдә§жқғпјҲзҹҘиҜҶдә§жқғпјүдҪ“зі»дёӢпјҢ并дёҚеӯҳеңЁдёҖз§Қй’ҲеҜ№ж•°жҚ®зҡ„иҙўдә§жқғгҖӮиҷҪ然зүҲжқғе’Ңе•Ҷдёҡз§ҳеҜҶеҲ¶еәҰиғҪеңЁдёҖе®ҡжқЎд»¶дёӢиҫҗе°„йғЁеҲҶж•°жҚ®пјҢдҪҶж•°жҚ®жң¬иә«йҡҫд»ҘжҲҗдёәйҖӮж јзҡ„жқғеҲ©е®ўдҪ“пјҢеӨ§йғЁеҲҶжң¬иә«ж— зӢ¬еҲӣжҖ§еҸҲйқһеӨ„дәҺз§ҳеҜҶзҠ¶жҖҒзҡ„ж•°жҚ®д»ҚеӨ„дәҺжі•еҫӢдҝқжҠӨзҡ„з©әзҷҪең°еёҰгҖӮеӣәжңүзҡ„зҹҘиҜҶдә§жқғеҲ¶еәҰйҡҫд»ҘжҲҗдёәи°ғж•ҙж•°жҚ®еҲ©зӣҠгҖҒи§ЈеҶіе®һи·өдәүи®®зҡ„еҫ—еҠӣдҫқжҚ®пјҢиҝҷж„Ҹе‘ізқҖж•°жҚ®еёӮеңәеӯҳеңЁдәӨжҳ“зҡ„е®үе®ҡжҖ§е’Ңдә§дёҡжҠ•иө„жҝҖеҠұдёҚи¶ізҡ„йЈҺйҷ©гҖӮеңЁжӯӨжғ…еҶөдёӢпјҢи®ёеӨҡеӣҪ家йҖҡиҝҮй…ҚзҪ®жқғеҲ©жҲ–еҲҶй…ҚеҲ©зӣҠиҝӣиЎҢжһ„е»әж–°еһӢж•°жҚ®жІ»зҗҶ规еҲҷзҡ„е°қиҜ•пјҢдёҚеҗҢжі•еҹҹ已然е‘ҲзҺ°еҮәдёҚеҗҢзҡ„ж•°жҚ®и§„еҲ¶жЁЎејҸе’ҢеҸ–еҗ‘гҖӮиҝҷдәӣж–°еһӢ规еҲҷе’Ңи·Ҝеҫ„жӯЈеҪ“жҖ§е’ҢеҗҲзҗҶжҖ§еҰӮдҪ•пјҢеҖјеҫ—ж·ұе…Ҙз ”з©¶гҖӮ 欧зӣҹзҡ„ж•°жҚ®жІ»зҗҶи·Ҝеҫ„гҖӮ欧зӣҹзҡ„ж•°жҚ®з«Ӣжі•иө·жӯҘж—©пјҢеҜ№жҠҖжңҜеҸ‘еұ•еә”еҜ№иҫғдёәж•Ҹй”җе’Ңз§ҜжһҒпјҢе·Із»ҸеҜ№ж•°жҚ®еӨ„зҗҶиҖ…иҙўдә§жқғеҲ©зӣҠеҲҶй…Қзҡ„规еҲҷиҝӣиЎҢдәҶдёҖзі»еҲ—е…ҲиЎҢжҺўзҙўгҖӮ欧зӣҹз«Ӣжі•иҖ…з»ҸиҝҮж•°е№ҙзҡ„и®Ёи®әпјҢд»Һз§ҜжһҒдёәж•°жҚ®еҲӣи®ҫжқғеҲ©иҪ¬еҗ‘и°Ёж…Һи®Өе®ҡиҙўдә§жқғпјҢйј“еҠұж•°жҚ®ејҖж”ҫиҺ·еҸ–гҖҒдҝғиҝӣж•°жҚ®иҰҒзҙ жөҒиҪ¬зҡ„жІ»зҗҶжҖҒеәҰгҖӮд»Һ2014е№ҙ欧зӣҹ委е‘ҳдјҡеҸ‘еёғйўҳдёәгҖҠи·Ёеҗ‘ж¬Јж¬Јеҗ‘иҚЈзҡ„ж•°жҚ®й©ұеҠЁеһӢз»ҸжөҺгҖӢзҡ„йҖҡи®ҜејҖе§ӢпјҢ欧зӣҹејҖе§ӢиҒҡз„ҰеӨ§ж•°жҚ®зҺҜеўғдёӢж•°жҚ®жІ»зҗҶ规еҲҷзҡ„е»әжһ„пјҢжҸҗеҮәе»әз«Ӣжі•еҫӢжЎҶжһ¶жқҘ规иҢғж•°жҚ®зҡ„з»ҸжөҺејҖеҸ‘е’ҢеҸҜдәӨжҳ“жҖ§гҖӮжӯӨеҗҺпјҢеҮ д№ҺжҜҸе№ҙ欧зӣҹйғҪдјҡеҜ№ж•°жҚ®иҺ·еҸ–е’Ңжқғеұһ规еҲҷзӯүеұ•ејҖж·ұе…ҘжҺўи®ЁгҖӮ2020е№ҙ2жңҲ19ж—ҘпјҢ欧зӣҹ委е‘ҳдјҡе…¬еёғдәҶгҖҠ欧жҙІж•°жҚ®жҲҳз•ҘгҖӢпјҢж—ўжүҝиўӯдәҶ欧зӣҹдёҖзӣҙд»ҘжқҘвҖңжҲҗдёәж•°жҚ®иөӢиғҪзӨҫдјҡзҡ„йўҶеҜјиҖ…вҖқзҡ„йҮҺеҝғпјҢеҸҲдҪ“зҺ°дәҶ欧зӣҹж•°жҚ®жІ»зҗҶжҖқи·Ҝзҡ„е…ій”®иҪ¬еҗ‘пјҡе°Ҷж•°жҚ®жІ»зҗҶзҡ„йҮҚеҝғз”ұеҲ©зӣҠдҝқжҠӨиҪ¬дёәиҰҒзҙ з»јеҗҲжІ»зҗҶпјҢејәи°ғеўһејәж•°жҚ®иҺ·еҸ–е’ҢиҮӘз”ұжөҒеҠЁгҖҒи§Јй”ҒжңӘдҪҝз”Ёзҡ„ж•°жҚ®пјҢдҪҝе…¶йҖ зҰҸдәҺзӨҫдјҡеҗ„з§Қдё»дҪ“гҖӮгҖҠ欧жҙІж•°жҚ®жҲҳз•ҘгҖӢйӣҶдёӯжҰӮиҝ°дәҶжңӘжқҘдә”е№ҙ欧зӣҹеҸ‘еұ•ж•°жҚ®з»ҸжөҺзҡ„ж”ҝзӯ–жҺӘж–Ҫе’ҢжҠ•иө„жҲҳз•ҘпјҢ并жҲҗдёәжӯӨеҗҺ欧зӣҹдёҖзі»еҲ—ж•°жҚ®з«Ӣжі•иЎҢеҠЁзҡ„жҖ»зәІгҖӮ 1.ж•°жҚ®иөӢжқғиҝӣи·Ҝзҡ„жҺўзҙўпјҡд»Һж•°жҚ®еә“зү№ж®ҠжқғеҲ°ж•°жҚ®з”ҹдә§иҖ…жқғгҖӮеңЁиҝҲе…ҘеӨ§ж•°жҚ®ж—¶д»Јд№ӢеүҚпјҢ欧зӣҹйҖҡиҝҮ1996е№ҙгҖҠ欧зӣҹж•°жҚ®еә“дҝқжҠӨжҢҮд»ӨгҖӢдёәж— зӢ¬еҲӣжҖ§зҡ„ж•°жҚ®еә“жҺҲдәҲдәҶдёҖйЎ№дёәжңҹ15е№ҙзҡ„жҺ’д»–жҖ§зҡ„зү№ж®ҠжқғеҲ©пјҢеёҢжңӣд»ҘиөӢжқғдҝқжҠӨзҡ„ж–№ејҸжҝҖеҠұ欧зӣҹж•°жҚ®еә“дә§дёҡеҸ‘еұ•пјҢжҠўеҚ еӣҪйҷ…з«һдәүе…ҲжңәгҖӮ вҖңж•°жҚ®еә“зү№ж®ҠжқғвҖқзҡ„и®ҫз«Ӣж—ЁеңЁйҖҡиҝҮиөӢжқғдёәж•°жҚ®еә“зҡ„еҲӣе»әиҖ…жҸҗдҫӣе……еҲҶеҲ©зӣҠдҝқжҠӨд»ҘжҝҖеҠұж•°жҚ®еә“жҠ•иө„пјҢдҪҶе…¶дҝғиҝӣж•°жҚ®еә“дә§дёҡеҸ‘еұ•зҡ„еҲ¶еәҰе®һж•ҲдёҚе°Ҫдәәж„ҸгҖӮ欧зӣҹ2005е№ҙзҡ„иҜ„дј°жҠҘе‘ҠдёӯжҸҗеҲ°пјҡвҖңдё“жңүжқғеҜ№ж•°жҚ®еә“з”ҹдә§зҡ„пјҲз§ҜжһҒпјүз»ҸжөҺеҪұе“Қе°ҡжңӘеҫ—еҲ°иҜҒе®һгҖӮвҖқиҖҢйҡҸзқҖе®һи·өдёӯж•°еӯ—еҲ©з”Ёзҡ„жҠҖжңҜеҸ‘еұ•е’ҢжЁЎејҸйқ©ж–°пјҢж•°жҚ®еә“зү№ж®Ҡжқғзҡ„ж•Ҳз”ЁеҸ‘жҢҘз©әй—ҙж„ҲеҸ‘иҫ№зјҳгҖӮдёҖж–№йқўпјҢйҖҡиҝҮжңәеҷЁгҖҒдј ж„ҹеҷЁиҮӘеҠЁз”ҹжҲҗжҲ–еҹәдәҺзү©иҒ”зҪ‘и®ҫеӨҮгҖҒдәәе·ҘжҷәиғҪзӯүж•°еӯ—еӨ„зҗҶжҠҖжңҜдә§з”ҹзҡ„ж•°жҚ®еә“пјҢйҖҡеёёеӣ ж— жі•ж»Ўи¶іеҲӨдҫӢжі•жүҖ规е®ҡзҡ„вҖң收йӣҶвҖқж ҮеҮҶиҖҢиў«жҺ’йҷӨеңЁж•°жҚ®еә“дҝқжҠӨзҡ„иҢғеӣҙд№ӢеӨ–гҖӮеҸҰдёҖж–№йқўпјҢе·Ҙдёҡ4.0ж—¶д»ЈпјҢж•°жҚ®еҫҖеҫҖжҳҜз”ҹдә§жҲ–жңҚеҠЎиҝҮзЁӢдёӯдҫқйқ з®—жі•иҮӘеҠЁдә§з”ҹзҡ„вҖңеүҜдә§е“ҒвҖқпјҢж•°жҚ®еә“зү№ж®Ҡжқғзҡ„вҖңе®һиҙЁжҖ§жҠ•иө„вҖқиҰҒжұӮд№ҹйҡҫд»ҘиҜҒжҲҗгҖӮеҹәдәҺжӯӨпјҢ欧зӣҹеӯҰиҖ…и®ӨдёәпјҢж•°жҚ®еә“зү№ж®Ҡжқғж— еҠӣеӣһеә”ж•°еӯ—з»ҸжөҺеҸ‘еұ•зҡ„иҜүжұӮпјҢж•°жҚ®жІ»зҗҶйңҖиҰҒж–°зҡ„еҲ¶еәҰе·Ҙе…·гҖӮ е»әжһ„дәҺ20дё–зәӘ90е№ҙд»Јзҡ„ж•°жҚ®еә“зү№ж®ҠжқғеҲ©еҲ¶еәҰе·Ійҡҫд»ҘжҲҗдёәж•°еӯ—з»ҸжөҺеҸ‘еұ•дёӯеҚҸи°ғж•°жҚ®еҲ©зӣҠзҡ„дҫқжҚ®пјҢеӯҰиҖ…ејҖе§ӢжҺўи®ЁеңЁж•°жҚ®д№ӢдёҠй…ҚзҪ®ж–°еһӢзҡ„иҙўдә§жқғгҖӮ2017е№ҙпјҢ欧зӣҹеңЁгҖҠе…ідәҺж•°жҚ®иҮӘз”ұжөҒеҠЁе’Ң欧жҙІж•°жҚ®з»ҸжөҺж–°й—®йўҳе·ҘдҪңж–Ү件гҖӢдёӯпјҢйҳҗиҝ°дәҶе»әжһ„дёҖз§ҚвҖңж•°жҚ®з”ҹдә§иҖ…жқғвҖқзҡ„и®ҫжғіпјҢ并жҸҗеҮәдәҶдёӨз§ҚжқғеҲ©е»әжһ„ж–№жЎҲгҖӮдёҖз§Қе°ҶвҖңж•°жҚ®з”ҹдә§иҖ…жқғвҖқе®ҡд№үдёәдёҖз§ҚеҜ№дё–жҖ§гҖҒжҺ’д»–жҖ§зҡ„жқғеҲ©пјҢжҺ§еҲ¶д»»дҪ•жңӘз»ҸжҺҲжқғи®ҝй—®ж•°жҚ®зҡ„иЎҢдёәгҖӮеңЁиҝҷз§Қжһ„жғідёӯпјҢж•°жҚ®з”ҹдә§иҖ…жқғеҲ©зҡ„иҢғеӣҙеә”вҖңжҜ”дј з»ҹзҡ„дё“жңүжҠҖжңҜдҝқжҠӨжӣҙе№ҝжіӣвҖқпјҢиҖҢдё”еҸҜиғҪдёҚйңҖиҰҒе®һиҙЁжҖ§жҠ•иө„зҡ„жқғеҲ©еҸ–еҫ—иҰҒ件гҖӮйҷӨејәжҺ’д»–жқғеӨ–пјҢ欧зӣҹиҝҳжҸҗеҮәдәҶдёҖз§ҚйҳІеҫЎжқғдҪңдёәжӣҝд»Јж–№жЎҲпјҢиҝҷз§ҚйҳІеҫЎжқғиў«и§ЈйҮҠдёәвҖңзӯүеҗҢдәҺеҜ№еҚ жңүдәӢе®һзҡ„дҝқжҠӨвҖқпјҢж•°жҚ®зҡ„дәӢе®һжҺ§еҲ¶иҖ…еҸҜд»ҘеңЁз¬¬дёүж–№зӣ—з”Ёж•°жҚ®зҡ„жғ…еҶөдёӢеҜ»жұӮзҰҒд»Өж•‘жөҺгҖҒиҺ·еҫ—иө”еҒҝпјҢ并еҸҜиҰҒжұӮжңӘз»ҸжҺҲжқғдҪҝз”Ёж•°жҚ®иҖҢеҲӣе»әзҡ„ж•°жҚ®дә§е“ҒйҖҖеҮәеёӮеңәгҖӮ йңҖиҰҒжҢҮеҮәзҡ„жҳҜпјҢвҖңж•°жҚ®з”ҹдә§иҖ…жқғвҖқи®ҫжғіиғҢеҗҺзҡ„д»·еҖјеҹәзЎҖе·ІйқһеҚ•еҗ‘ејәи°ғеҜ№ж•°жҚ®з”ҹдә§иҖ…зҡ„еҲ©зӣҠдҝқжҠӨпјҢиҖҢжҳҜе°Ҷдә§жқғй…ҚзҪ®и§ҶдёәжҸҗй«ҳж•°жҚ®еҸҜдәӨжҳ“жҖ§гҖҒжү«йҷӨж•°жҚ®иҮӘз”ұжөҒеҠЁйҡңзўҚзҡ„дёҖз§ҚдёҫжҺӘгҖӮдёәжӯӨпјҢ欧зӣҹ委е‘ҳдјҡе»әи®®пјҢж•°жҚ®з”ҹдә§иҖ…жқғеә”еҸӘдҝқжҠӨж•°жҚ®зҡ„еҸҘжі•еұӮпјҲжңәиҜ»ж•°еӯ—иЎЁиҫҫпјүиҖҢйқһиҜӯд№үеұӮпјҲж•°жҚ®дј йҖ’зҡ„дҝЎжҒҜеҶ…е®№пјүпјҢеҚіе°ҶдҝқжҠӨеҜ№иұЎйҷҗзј©дәҺд»Јз ҒпјҢд»ҘйҒҝе…ҚйҖ жҲҗдҝЎжҒҜжҲ–жҖқжғіеһ„ж–ӯгҖӮеҚідҫҝеҰӮжӯӨпјҢеңЁж•°жҚ®дёҠи®ҫзҪ®жҺ’д»–жқғжҲ–иҖ…дёәж•°жҚ®жҺ§еҲ¶иҖ…жҸҗдҫӣзҡ„зҰҒд»Өж•‘жөҺиғҪеҗҰе®һзҺ°дҝғиҝӣж•°жҚ®иҺ·еҸ–еҲ©з”Ёзҡ„еҲ¶еәҰзӣ®ж ҮпјҢд»Қ然еҖјеҫ—жҖҖз–‘гҖӮзӣёиҫғдәҺе…¶дҝғиҝӣдәӨжҳ“зҡ„йў„жңҹд»·еҖјпјҢжқғеҲ©зҡ„жҺ§еҲ¶жҖ§з»ҷж•°жҚ®иҺ·еҸ–е’ҢиҮӘз”ұжөҒеҠЁйҖ жҲҗзҡ„жҪңеңЁеЈҒеһ’жӣҙд»Өдәәе…іжіЁгҖӮз»ҸиҝҮ欧зӣҹеӯҰжңҜе’Ңдә§дёҡз•ҢеӨҡе№ҙзҡ„и®Ёи®әпјҢжһ„е»әж•°жҚ®жҺ’д»–жҖ§жқғеҲ©зҡ„е‘јеЈ°жёҗжёҗиў«жҺ’д»–жҖ§жқғеҲ©еҸҜиғҪйҳ»зўҚж•°жҚ®иҺ·еҸ–е’ҢжөҒеҠЁзҡ„жӢ…еҝ§жүҖиҰҶзӣ–гҖӮеҗҢж—¶пјҢзӣёе…із ”究жҠҘе‘ҠжҳҫзӨәпјҢеҜ№дәҺеҲ©зӣҠзӣёе…іиҖ…вҖңжңҖе…ій”®зҡ„й—®йўҳ并йқһж•°жҚ®жүҖжңүжқғпјҢиҖҢжҳҜеҰӮдҪ•з»„з»Үж•°жҚ®и®ҝй—®вҖқгҖӮ欧зӣҹиҪ¬иҖҢжҺўзҙўиөӢжқғд№ӢеӨ–зҡ„е…¶д»–ж•°жҚ®жІ»зҗҶжЎҶжһ¶гҖӮ 2.йј“еҠұж•°жҚ®иҺ·еҸ–е’Ңе…ұдә«зҡ„з»јеҗҲжІ»зҗҶжЎҶжһ¶гҖӮ2020е№ҙ欧зӣҹе…¬еёғгҖҠ欧жҙІж•°жҚ®жҲҳз•ҘгҖӢпјҢејҖе§Ӣж”ҫејғж•°жҚ®иөӢжқғдҝқжҠӨжҖқи·ҜпјҢиҪ¬иҖҢйҮҮеҸ–дёҖз§ҚиҒҡз„Ұж•°жҚ®иҺ·еҸ–гҖҒзӣҙжҺҘжҺЁеҠЁж•°жҚ®е…ұдә«зҡ„жІ»зҗҶжҖқи·ҜгҖӮ欧зӣҹ委е‘ҳдјҡиЎЁзӨәпјҢж•°жҚ®жҳҜдёҖз§Қйқһз«һдәүжҖ§иө„жәҗпјҢеҚіеҗҢж ·зҡ„ж•°жҚ®еҸҜд»Ҙж”ҜжҢҒеӨҡдёӘж–°дә§е“ҒгҖҒжңҚеҠЎжҲ–з”ҹдә§ж–№жі•зҡ„еҲӣе»әгҖӮиҝҷе…Ғи®ёд»»дҪ•дјҒдёҡд»ҘдёҚеҗҢзҡ„ж•°жҚ®е…ұдә«е®үжҺ’дёҺе…¶д»–еӨ§дјҒдёҡгҖҒдёӯе°ҸдјҒдёҡе’ҢеҲқеҲӣдјҒдёҡпјҢз”ҡиҮіе…¬е…ұйғЁй—ЁжҺҘи§ҰзӣёеҗҢзҡ„ж•°жҚ®гҖӮйҖҡиҝҮиҝҷз§Қж–№ејҸпјҢеҸҜд»ҘжңҖеӨ§йҷҗеәҰең°еҲ©з”Ёж•°жҚ®дә§з”ҹзҡ„д»·еҖјгҖӮ欧зӣҹ委е‘ҳдјҡзү№еҲ«ејәи°ғпјҢз”ұдәҺж•°жҚ®з»ҸжөҺзҡ„жүҖжңүеҸ‘еұ•иҰҒзҙ е°ҡйҡҫд»Ҙе®Ңе…ЁжҠҠжҸЎпјҢеә”зқҖж„ҸйҒҝе…ҚиҝҮдәҺз»ҶиҮҙгҖҒдёҘж јзҡ„дәӢеүҚзӣ‘з®ЎпјҢиҖҢеҖҫеҗ‘дәҺйҮҮз”ЁжӣҙжңүеҲ©дәҺж•°жҚ®е®һи·өзҡ„зҒөжҙ»жІ»зҗҶж–№жі•гҖӮ еңЁжӯӨеҺҹеҲҷжҢҮеј•дёӢпјҢгҖҠ欧жҙІж•°жҚ®жҲҳз•ҘгҖӢдёӯжҸҗеҮәзҡ„ж•°жҚ®з«Ӣжі•жЎҶжһ¶дёҚеҶҚиҜ•еӣҫд»Ҙи®ҫз«Ӣж•°жҚ®иҙўдә§жқғдҪңдёәжҺЁеҠЁж•°жҚ®дәӨжҳ“е’ҢжөҒеҠЁзҡ„еҲ¶еәҰжҝҖеҠұпјҢиҖҢжҳҜзӣҙжҺҘиҒҡз„ҰдәҺеҲ¶е®ҡе…¬е№ігҖҒе®һз”Ёе’Ңжё…жҷ°зҡ„ж•°жҚ®иҺ·еҸ–дёҺдҪҝ用规еҲҷпјҢиҗҘйҖ еҖјеҫ—дҝЎиө–зҡ„ж•°жҚ®е…ұдә«зҺҜеўғгҖӮйҰ–е…ҲпјҢ欧зӣҹзі»еҲ—ж•°жҚ®з«Ӣжі•зҡ„йҰ–иҰҒзӣ®зҡ„жҳҜдёәе®һи·өдёӯзҡ„ж•°жҚ®еҲ©з”ЁвҖңжқҫз»‘вҖқпјҢдҫҝдәҺе®һи·өдё»дҪ“зҗҶи§ЈвҖңе“Әдәӣж•°жҚ®еңЁе“Әдәӣжғ…еҶөдёӢеҸҜд»ҘдҪҝз”ЁвҖқпјҢ并иҖғеҜҹж•°жҚ®зҡ„дә’ж“ҚдҪңжҖ§ж ҮеҮҶгҖҒдҝғиҝӣж•°жҚ®зҡ„и·Ёз•ҢдҪҝз”ЁгҖӮе…¶ж¬ЎпјҢжҸҗй«ҳе…¬е…ұж•°жҚ®зҡ„ејҖж”ҫиҺ·еҸ–ж°ҙе№ід№ҹиў«еҲ—дёәж•°жҚ®жІ»зҗҶзҡ„йҮҚзӮ№зӣ®ж ҮпјҢе°Өе…¶е°Ҷ欧зӣҹ2019е№ҙйҖҡиҝҮзҡ„гҖҠе…ідәҺе…¬е…ұйғЁй—ЁдҝЎжҒҜејҖж”ҫж•°жҚ®еҶҚеҲ©з”Ёзҡ„жҢҮд»ӨгҖӢпјҲPSIжҢҮд»ӨпјүдёӯжҸҗеҮәзҡ„й«ҳд»·еҖјж•°жҚ®йӣҶзҡ„ејҖж”ҫжҺӘж–ҪеҠ д»Ҙжңүж•ҲиҗҪе®һгҖӮжӯӨеӨ–пјҢвҖңжһ„е»әжЁӘеҗ‘ж•°жҚ®е…ұдә«зҡ„жҝҖеҠұжҺӘж–ҪвҖқе’ҢвҖңе»әз«Ӣж•°жҚ®еҲҶжһҗе’ҢжңәеҷЁеӯҰд№ ж•°жҚ®жұ вҖқд№ҹжҳҜ欧зӣҹжҸҗеҮәзҡ„ж•°жҚ®з«Ӣжі•дёҫжҺӘгҖӮ гҖҠ欧жҙІж•°жҚ®жҲҳз•ҘгҖӢдёӯжҸҗеҮәзҡ„еҜ№ж•°жҚ®иҺ·еҸ–е’ҢдҪҝз”Ёзҡ„з«Ӣжі•жІ»зҗҶ规еҲ’иҝ…йҖҹиҗҪең°гҖӮ2020е№ҙ11жңҲпјҢдҪңдёә欧зӣҹвҖңж•°жҚ®жҲҳз•Ҙе®һж–Ҫзҡ„第дёҖжӯҘвҖқпјҢ欧зӣҹ委е‘ҳдјҡеҸ‘еёғдәҶгҖҠж•°жҚ®жІ»зҗҶжі•жЎҲгҖӢпјҢ并дәҺ2022е№ҙ5жңҲжңҖз»ҲйҖҡиҝҮгҖӮгҖҠж•°жҚ®жІ»зҗҶжі•жЎҲгҖӢж—ЁеңЁдҝғиҝӣжҺЁеҠЁж•°жҚ®дҫӣз»ҷе’ҢиҺ·еҸ–пјҢд»ҘвҖңдҝЎд»»вҖқе’ҢвҖңзӨҫдјҡеҲ©зӣҠвҖқдёәж ёеҝғжҰӮеҝөпјҢжҸҗеҮәдәҶеҮ еҘ—дҝғиҝӣж•°жҚ®йҮҚеӨҚеҲ©з”Ёе’Ңе…ұдә«зҡ„зі»з»ҹпјҡе…¶дёҖпјҢеҜ№дәҺдёҚе®ңзӣҙжҺҘејҖж”ҫзҡ„е…¬е…ұйғЁй—Ёж•°жҚ®пјҲдҫӢеҰӮпјҢе…¬е…ұеҒҘеә·ж•°жҚ®гҖҒеҗ«жңүзҹҘиҜҶдә§жқғзҡ„ж•°жҚ®зӯүпјүпјҢи®ҫи®ЎдҫҝдәҺж•°жҚ®еҶҚеҲ©з”Ёе’Ңе®һзҺ°зӨҫдјҡж•ҲзӣҠзҡ„жңәеҲ¶пјӣе…¶дәҢпјҢи®ҫз«Ӣж•°жҚ®иҺ·еҸ–дёӯд»Ӣжңәжһ„вҖңж•°жҚ®е…ұдә«жңҚеҠЎжҸҗдҫӣиҖ…вҖқпјҢдёәж•°жҚ®жҢҒжңүиҖ…дёҺжҪңеңЁж•°жҚ®з”ЁжҲ·жҸҗдҫӣж•°жҚ®иҺ·еҸ–е’Ңе…ұдә«жңҚеҠЎпјҢ并дёәиҝҷз§ҚжңҚеҠЎе»әз«Ӣзӣ‘зқЈе’ҢйҖҡзҹҘжЎҶжһ¶пјҢд»ҘжӯӨжҸҗеҚҮеёӮеңәеҜ№ж•°жҚ®е…ұдә«зҡ„дҝЎд»»е’Ңж„Ҹж„ҝпјӣе…¶дёүпјҢжҺЁиЎҢвҖңж•°жҚ®еҲ©д»–дё»д№үвҖқзҡ„жҰӮеҝөпјҢжҸҗй«ҳе…¬ж°‘е’ҢдјҒдёҡеҹәдәҺе…¬зӣҠиҮӘж„ҝжҸҗдҫӣж•°жҚ®зҡ„з§ҜжһҒжҖ§гҖӮгҖҠж•°жҚ®жІ»зҗҶжі•жЎҲгҖӢжҸҗеҮәдәҶж•°жҚ®жІ»зҗҶзҡ„жҖ»дҪ“жһ¶жһ„пјҢ然иҖҢе…·дҪ“жҖ§дёҚи¶іпјӣе…¶еҜ№ж•°жҚ®е…ұдә«зҡ„жҺЁеҠЁдё»иҰҒеҒңз•ҷеңЁеҲ¶еәҰжһ„жғіеұӮйқўпјҢжңӘиғҪжҸҗдҫӣдҝғиҝӣж•°жҚ®е…ұдә«зҡ„еҝ…иҰҒзҗҶз”ұжҲ–жҝҖеҠұжҺӘж–ҪгҖӮ 2022е№ҙ2жңҲ23ж—ҘпјҢ欧зӣҹ委е‘ҳдјҡжҸҗеҮәзҡ„гҖҠж•°жҚ®жі•жЎҲгҖӢиҚүжЎҲжҳҜгҖҠ欧жҙІж•°жҚ®жҲҳз•ҘгҖӢ规еҲ’зҡ„еҸҰдёҖйЎ№дё»иҰҒж•°жҚ®з«Ӣжі•дёҫжҺӘпјҢ被欧жҙІеӯҰиҖ…з§°дёәвҖң欧зӣҹж•°жҚ®жҲҳз•Ҙзҡ„йЎ¶еі°вҖқгҖӮгҖҠж•°жҚ®жі•жЎҲгҖӢд№ҹжһ„жҲҗдәҶеҜ№гҖҠж•°жҚ®жІ»зҗҶжі•жЎҲгҖӢзҡ„иЎҘе……пјҢеңЁгҖҠж•°жҚ®жІ»зҗҶжі•жЎҲгҖӢжҗӯе»әзҡ„ж•°жҚ®дёӯд»Ӣжңәжһ„е’Ңж•°жҚ®еҲ©д»–дё»д№үзӯүж•°жҚ®е…ұдә«з»“жһ„еҹәзЎҖдёҠпјҢгҖҠж•°жҚ®жі•жЎҲгҖӢиҝӣдёҖжӯҘ规иҢғдәҶе…ұдә«з»“жһ„дёӯе…·дҪ“зҡ„ж•°жҚ®и®ҝй—®е’ҢдҪҝз”Ёж–№ејҸпјҢжҳҺзЎ®дәҶдҪ•з§Қдё»дҪ“гҖҒеңЁдҪ•з§ҚжқЎд»¶дёӢеҸҜд»ҘеҲ©з”Ёж•°жҚ®еҲӣйҖ д»·еҖјгҖӮ зӣёиҫғдәҺйғЁеҲҶеӣҪ家数жҚ®з«Ӣжі•зҡ„дҝқе®ҲгҖҒи§Ӯжңӣз«ӢеңәпјҢ欧зӣҹиЎЁйңІеҮәе…¶еҸ‘жҺҳж•°жҚ®жҪңеҠӣгҖҒдәүеҸ–з«һдәүдјҳеҠҝзҡ„з§ҜжһҒжҖҒеәҰе’ҢеӢғеӢғйҮҺеҝғпјҢд№ҹеұ•зҺ°дәҶеҜ№ж•°жҚ®з«Ӣжі•жІ»зҗҶзҡ„й«ҳеәҰйҮҚи§ҶпјҢе°ҶвҖңе»әз«Ӣж•°жҚ®иҺ·еҸ–е’ҢдҪҝз”Ёзҡ„и·ЁйғЁй—Ёжі•еҫӢжЎҶжһ¶вҖқеҲ—дёә欧жҙІжҲҳз•Ҙе®һж–Ҫзҡ„йҰ–иҰҒиЎҢеҠЁж”ҜжҹұпјҢ并иҝ…йҖҹз”ұз«Ӣ法规еҲ’иө°еҗ‘з«Ӣжі•е®һи·өгҖӮ 然иҖҢпјҢеҜ№ж•°жҚ®з«Ӣжі•жІ»зҗҶзҡ„еҖҡйҮҚ并дёҚж„Ҹе‘ізқҖд»Ҙжі•еҫӢд№ӢеҠӣеҜ№ж•°жҚ®еёӮеңәиҝӣиЎҢејәеҠҝе№Ійў„гҖҒжҲ–еҜ„еёҢжңӣдәҺйҖҡиҝҮи®ҫз«ӢжҺ’д»–жҖ§иҙўдә§жқғеҲ©дёәж•°жҚ®е•Ҷе“ҒеҢ–вҖңж·»зҝјвҖқгҖӮзӣёеҸҚпјҢиҷҪ然欧зӣҹж•°жҚ®з«Ӣжі•иҝӣзЁӢеҰӮзҒ«еҰӮиҚјпјҢдҪҶе·ІеҮәеҸ°зҡ„жі•жЎҲд»ҚжҳҜжЎҶжһ¶ејҸзҡ„пјҢдё”дҪ“зҺ°еҮәеҜ№зҺ°жңүж•°жҚ®еёӮеңәе®һи·өзҡ„е°ҠйҮҚпјҢејәи°ғйҮҚи§Ҷж•°жҚ®з”ҹжҖҒзі»з»ҹзҡ„еј№жҖ§е’ҢеҸ‘еұ•жҙ»еҠӣпјӣеҗҢж—¶пјҢ欧зӣҹж•°жҚ®з«Ӣжі•и®®зЁӢд№ҹдҪ“зҺ°дәҶйІңжҳҺзҡ„з«ӢеңәиҪ¬еҗ‘пјҢд»Һж•°жҚ®жҺ§еҲ¶иҖ…з«Ҝзҡ„еҲ©зӣҠз»ҙжҠӨпјҢиҪ¬еҗ‘ж•°жҚ®и®ҝй—®иҖ…з«Ҝзҡ„еҲ©зӣҠе®һзҺ°пјҢз”ұвҖңдҝқжҠӨвҖқвҖңжҝҖеҠұвҖқиҪ¬дёәвҖңе»әз«ӢдҝЎд»»вҖқвҖңиҺ·еҸ–е…ұдә«вҖқгҖӮеҸҜи§ҒпјҢеҜ№дәҺдёҖз§Қж–°еһӢз”ҹдә§иҰҒзҙ е’Ңдә§дёҡз»“жһ„пјҢжі•еҫӢ规еҲ¶еә”з§ҜжһҒеҮәеҮ»гҖҒйҒҝе…Қиҝҹж»һпјҢдҪҶе№Ійў„зҡ„жүӢж®өд№ҹеә”з¬ҰеҗҲжҜ”дҫӢеҺҹеҲҷпјҢдҝқжҢҒдёҖе®ҡзҡ„и°ҰжҠ‘е…ӢеҲ¶гҖӮеҜ№жІ»зҗҶи·Ҝеҫ„зҡ„и®ҫи®ЎйңҖиҰҒе°ҪеҸҜиғҪе……еҲҶзҡ„иҜ„дј°е’Ңи®әиҜҒгҖӮ зҫҺеӣҪзҡ„ж•°жҚ®жІ»зҗҶ规еҲҷгҖӮзҫҺеӣҪеңЁиҒ”йӮҰеұӮйқўе°ҡж— з»ҹдёҖзҡ„ж•°жҚ®жқғеҲ©зӣ‘з®ЎжҲ–е•Ҷдёҡж•°жҚ®зҡ„и®ҝ问规еҲҷпјҢжӣҙжңӘйҖҡиҝҮз«Ӣжі•еҜ№ж•°жҚ®жқғзӣҠеҪ’еұһиҝӣиЎҢеҲҶй…ҚгҖӮе®һи·өдёӯпјҢж•°жҚ®дё»дҪ“д№Ӣй—ҙд№ҹдё»иҰҒдҫқйқ еҗҲеҗҢи°ғж•ҙж•°жҚ®зҡ„иҺ·еҸ–е’ҢдҪҝз”ЁпјҢдҪ“зҺ°дёәдёҖз§ҚвҖңиҮӘеҫӢвҖқејҸзҡ„ж•°жҚ®еҲ©зӣҠеҚҸи°ғи·Ҝеҫ„гҖӮ 1.ж•°жҚ®жІ»зҗҶзҡ„еҹәжң¬жҖҒеәҰпјҡйҮҚи§ҶдҝЎжҒҜиҮӘз”ұдёҺж•°жҚ®е…¬ејҖгҖӮзҫҺеӣҪеҺҶеҸІдёҠеҲ¶е®ҡдҝЎжҒҜ收йӣҶеҸҚзӣ—зүҲжі•зҡ„з§Қз§Қи®ҫжғіпјҢйғҪеӣ еҸҜиғҪеҜ№ж•°жҚ®е’ҢдҝЎжҒҜйҖ жҲҗжі•еҫӢеһ„ж–ӯйЈҺйҷ©иҖҢеҸ—еҲ°дёҘиӮғзҡ„жү№иҜ„гҖӮзҫҺеӣҪеӯҰз•Ңи®ӨдёәпјҢеҜ№ж•°жҚ®зҡ„жҺ’д»–жқғдҝқжҠӨиҝқеҸҚдәҶзҹҘиҜҶдә§жқғзҡ„еҹәжң¬еҺҹеҲҷвҖ”вҖ”д»»дҪ•дәәйғҪдёҚеә”еҜ№жҖқжғіжҲ–дәӨжөҒзҡ„еҹәзҹіиҺ·еҫ—еһ„ж–ӯжқғгҖӮзҫҺеӣҪеҜ№дҝЎжҒҜиҮӘз”ұе’Ңж•°жҚ®е…¬ејҖзҡ„йҮҚи§Ҷиў«и®ӨдёәжҳҜж•°жҚ®зЎ®жқғзҡ„е®ўи§Ӯйҳ»зўҚгҖӮ е…¶дёҖпјҢж•°жҚ®иөӢжқғдҝқжҠӨз«Ӣжі•зҡ„еӨұиҙҘгҖӮзҫҺеӣҪ1991е№ҙзҡ„вҖңFeistжЎҲвҖқеҘ е®ҡдәҶзҫҺеӣҪеҜ№ж•°жҚ®й—®йўҳзҡ„еӨ„зҗҶеҹәи°ғпјҢеҚіж— зӢ¬еҲӣжҖ§зҡ„ж•°жҚ®жұҮзј–дёҚеҸ—жі•еҫӢдҝқжҠӨгҖӮиҜҘжЎҲдёҚд»…жҳҺзЎ®дәҶдёҚеҫ—д»…дҫқйқ жҠ•иө„жқҘдё»еј зүҲжқғжі•дёҠзҡ„жқғеҲ©пјҢ并жҠҠвҖңдәӢе®һдҝЎжҒҜдёҚеҸ—жҺ’д»–жқғдҝқжҠӨвҖқзҡ„дҝЎжқЎдёҠеҚҮеҲ°дәҶе®Әжі•еұӮйқўгҖӮеӣ жӯӨпјҢеңЁж¬§зӣҹз§ҜжһҒеҜ№ж•°жҚ®еә“иөӢдәҲзү№ж®ҠжқғеҲ©иҖҢиҝӣиЎҢдҝқжҠӨзҡ„ж—¶еҖҷпјҢзҫҺеӣҪ并没жңүдёәж•°жҚ®жҲ–ж•°жҚ®еә“жҸҗдҫӣзү№еҲ«дҝқжҠӨпјҢдё”зҫҺеӣҪеҺҶеҸІдёҠжӣҫиҝӣиЎҢиҝҮзҡ„ж•°жҚ®з«Ӣжі•дҝқжҠӨе°қиҜ•д№ҹеқҮд»ҘеӨұиҙҘе‘Ҡз»ҲгҖӮ зҫҺеӣҪдәҺ1996е№ҙйҰ–ж¬ЎеңЁеӣҪдјҡжҸҗеҮәеҲӣе»әж•°жҚ®еә“дә§жқғзҡ„з«Ӣжі•пјҲHR 3531пјҢж•°жҚ®еә“жҠ•иө„е’ҢзҹҘиҜҶдә§жқғеҸҚзӣ—зүҲжі•жЎҲпјҢDatabase Investment and Intellectual Property Antipiracy Act of 1996пјүгҖӮиҜҘжі•жЎҲжӢҹжҺҲдәҲзҫҺеӣҪж•°жҚ®еә“д»Ҙ欧жҙІж•°жҚ®еә“жҢҮд»ӨжүҖжҸҗдҫӣзҡ„зұ»дјјжқғеҲ©пјҢйҒӯеҲ°ејәзғҲеҸҚеҜ№гҖӮзү№еҲ«жҳҜпјҢзҫҺеӣҪеӣҪ家ж•ҷиӮІеҚҸдјҡгҖҒзҫҺеӣҪеӣҫд№ҰйҰҶеҚҸдјҡгҖҒзҫҺеӣҪеӣҪ家科еӯҰйҷўе’ҢзҫҺеӣҪеӣҪ家е·ҘзЁӢйҷўзӯүз»„з»ҮжӢ…еҝғиҜҘжі•жЎҲдјҡеӣ дёәеҜ№ж•°жҚ®и®ҝй—®зҡ„жҪңеңЁйҷҗеҲ¶иҖҢеүҠејұеӣҪ家зҡ„з ”з©¶иғҪеҠӣгҖӮ еңЁзҫҺеӣҪ第105еұҠеӣҪдјҡдёҠпјҢзҫҺеӣҪж•°жҚ®жқғеҲ©зҡ„дё»еј иҖ…еҶҚж¬ЎжҸҗеҮәдәҶж–°зҡ„и®®жЎҲпјҲHR 2652пјҢдҝЎжҒҜ收йӣҶеҸҚзӣ—з”Ёжі•жЎҲпјҢCollections of Information Antipiracy ActпјүпјҢжҸҗи®®дҝқжҠӨд»»дҪ•вҖңйҖҡиҝҮеӨ§йҮҸйҮ‘й’ұжҲ–е…¶д»–иө„жәҗзҡ„жҠ•иө„收йӣҶгҖҒз»„з»ҮжҲ–з»ҙжҠӨзҡ„дҝЎжҒҜйӣҶеҗҲвҖқе…ҚеҸ—ж•°жҚ®зӣ—з”Ёзҡ„е®һйҷ…жҲ–жҪңеңЁеЁҒиғҒгҖӮ然иҖҢпјҢиҜҘжі•жЎҲеҜ№з¬ҰеҗҲдҝқжҠӨжқЎд»¶зҡ„ж•°жҚ®зұ»еһӢе’ҢеҸҜиғҪеј•еҸ‘иҙЈд»»зҡ„дҪҝз”Ёз§Қзұ»еқҮжІЎжңүиҝӣиЎҢйҷҗеҲ¶пјҢд№ҹжІЎжңүи®ҫзҪ®дҝқжҠӨжңҹйҷҗгҖӮHR 2652жҸҗжЎҲиў«и®Өдёәе®һйҷ…дёҠжҺҲдәҲдәҶеһ„ж–ӯжқғпјҢеҚіж•°жҚ®еә“еҲ¶йҖ е•ҶеҸҜд»Ҙйҳ»жӯўд»»дҪ•дәәжҸҗеҸ–гҖҒдҪҝз”ЁжҲ–йҮҚеӨҚдҪҝз”Ёж•°жҚ®еә“дёӯиў«и®ӨдёәвҖңйҮҚиҰҒвҖқзҡ„д»»дҪ•йғЁеҲҶпјҢеӣ иҖҢиҜҘжі•жЎҲдәҰжңӘиҺ·еҫ—йҖҡиҝҮгҖӮ е…¶дәҢпјҢеҸёжі•е®һи·өеҜ№ж•°жҚ®жқғеұһзҡ„жЁЎзіҠеӨ„зҗҶгҖӮеңЁ2000е№ҙвҖңeBay v. Bidder's EdgeжЎҲвҖқдёӯпјҢзҫҺеӣҪжі•йҷўжӣҫи®Өдёәиў«е‘ҠBidder's EdgeйҖҡиҝҮзҪ‘з»ңзҲ¬иҷ«иҺ·еҸ–eBayж•°жҚ®жһ„жҲҗеҠЁдә§дҫөе®іиЎҢдёәгҖӮиҖҢйҡҸзқҖдә’иҒ”зҪ‘жҠҖжңҜеҸ‘еұ•зҡ„ж·ұе…ҘпјҢиҝҷз§Қи®Өе®ҡйҒӯеҲ°дәҶеҗҺз»ӯеҲӨдҫӢжі•зҡ„е№ҝжіӣжү№иҜ„гҖӮеҚ•зәҜзҲ¬еҸ–д»–дәәж•°жҚ®е№¶дёҚеҪ“然иҝқжі•пјҢеҸӘжңүеҪ“зҲ¬иҷ«з»ҷж•°жҚ®жҺ§еҲ¶иҖ…зҡ„зі»з»ҹеёҰжқҘиҙҹжӢ…жҲ–з ҙеқҸпјҢж•°жҚ®зҲ¬еҸ–жүҚе…·жңүеҸҜиҙЈжҖ§гҖӮдҫӢеҰӮпјҢеңЁвҖңTicketmaster v. TicketsжЎҲвҖқдёӯпјҢжі•йҷўжҢҮеҮәпјҢе№іеҸ°ж•°жҚ®иў«жҠ“еҸ–зҡ„дәӢе®һжң¬иә«дёҚиғҪжҲҗз«ӢеҠЁдә§дҫөе®іпјҢеҪ“дәӢдәәйңҖиҰҒиҜҒжҳҺе…¶и®Ўз®—жңәжҲ–и®Ўз®—жңәзҪ‘з»ңеҸ—еҲ°зҲ¬иҷ«зҡ„дёҚеҲ©еҪұе“ҚгҖӮжҚўиЁҖд№ӢпјҢиҮіе°‘еңЁдёҖзі»еҲ—жЎҲ件дёӯпјҢзҫҺеӣҪжі•йҷўеҗҰи®ӨдәҶж•°жҚ®еұһдәҺе№іеҸ°зӢ¬еҚ иҙўдә§зҡ„и§ӮзӮ№гҖӮиҖҢеңЁиҝ‘еҮ е№ҙзҫҺеӣҪеӨҡиө·ж•°жҚ®зҲ¬еҸ–жЎҲ件дёӯпјҢж•°жҚ®жқғеұһеқҮйқһдәүи®®з„ҰзӮ№гҖӮжі•е®ҳе’ҢеҫӢеёҲ们似д№ҺйғҪеӣһйҒҝдәҶж•°жҚ®еҪ’еұһй—®йўҳпјҢе°Ҷд№ӢжЁЎзіҠеҢ–еӨ„зҗҶпјҢзӣҙжҺҘи§ЈеҶізҲ¬еҸ–иЎҢдёәжң¬иә«зҡ„й—®йўҳпјҢиҖҢдёҚеңЁж•°жҚ®жқғеұһй—®йўҳдёҠиҝҮеӨҡзә з»“гҖӮ 2.е…¬е…ұж•°жҚ®зҡ„ејҖж”ҫиҰҒжұӮгҖӮиҷҪ然жңӘд»Ҙжі•еҫӢзЎ®з«Ӣж•°жҚ®еҲ©з”Ёи§„еҲҷпјҢдҪҶеҜ№дәҺе…¬е…ұж•°жҚ®пјҢзҫҺеӣҪд№ҹе·ІйҖҡиҝҮз«Ӣ法规е®ҡдәҶдҝқжҢҒе…¬е…ұж•°жҚ®ејҖж”ҫеҸҜз”Ёзҡ„иҰҒжұӮгҖӮ зҫҺеӣҪдё“еҲ©е•Ҷж ҮеұҖжӣҫжҢҮеҮәпјҢз”ұж”ҝеәңиө„еҠ©з”ҹжҲҗзҡ„ж•°жҚ®еә“дёҚеә”еңЁжі•еҫӢдёҠжҲ–дәӢе®һдёҠзҪ®дәҺд»»дҪ•з§Ғдәәзҡ„жҺ’д»–жҺ§еҲ¶д№ӢдёӢгҖӮж”ҝеәңиө„еҠ©зҡ„ж•°жҚ®еә“дёҚеҸ—жі•еҫӢдҝқжҠӨзҡ„еҺҹеӣ дё»иҰҒжңүдәҢпјҡйҰ–е…ҲпјҢеҰӮжһңзҫҺеӣҪж”ҝеәңиө„еҠ©зҡ„ж•°жҚ®еә“еҸ—еҲ°жҹҗз§Қзұ»еһӢзҡ„дҝқжҠӨеҲ¶еәҰзҡ„зәҰжқҹпјҢзәізЁҺдәәеҸҜиғҪдјҡеӣ и®ҝй—®ж•°жҚ®иҖҢйҮҚеӨҚд»ҳиҙ№пјӣе…¶ж¬ЎпјҢж”ҝеәңиө„еҠ©е·Із»Ҹдёәж•°жҚ®з”ҹдә§е’Ң收йӣҶжҸҗдҫӣдәҶжҝҖеҠұпјҢеӣ жӯӨдёҚеҝ…жӢ…еҝғеӣ зјәд№ҸеҲ¶еәҰдҝқжҠӨиҖҢйҖ жҲҗзҡ„жҝҖеҠұдёҚи¶ій—®йўҳгҖӮзҫҺеӣҪиҒ”йӮҰжңәжһ„иў«и®Өдёәе…·жңүеҗ‘е…¬дј—жҸҗдҫӣж”ҝеәңж•°жҚ®пјҢ并йҒҝе…Қи®ҫзҪ®йҳ»зўҚе…¬дј—и®ҝй—®зҡ„йҡңзўҚзҡ„е№ҝжіӣдёҖиҲ¬жҖ§д№үеҠЎгҖӮ2009е№ҙпјҢдёәдәҶеҗ‘е…¬дј—ејҖж”ҫвҖңй«ҳд»·еҖјж•°жҚ®вҖқпјҢзҫҺеӣҪж”ҝеәңе»әз«ӢдәҶdata.govзҪ‘з«ҷпјҢзӣҙжҺҘдёәз”ЁжҲ·жҸҗдҫӣжө·йҮҸзҡ„еҺҹе§Ӣж”ҝеәңж•°жҚ®пјҢ并鼓еҠұдҪҝз”ЁиҖ…жҢ–жҺҳиҝҷдәӣж•°жҚ®зҡ„ж–°зҡ„еҲ©з”Ёд»·еҖјгҖӮ 2019е№ҙ1жңҲпјҢзҫҺеӣҪеӣҪдјҡйҖҡиҝҮдәҶгҖҠеҫӘиҜҒеҶізӯ–еҹәзЎҖжі•жЎҲпјҲ2018пјүгҖӢпјҢиҰҒжұӮзҫҺеӣҪиҒ”йӮҰжңәжһ„еңЁзҪ‘дёҠе…¬ејҖеҸ‘еёғж”ҝеәңдҝЎжҒҜдҪҝз”Ёж ҮеҮҶгҖҒжңәеҷЁеҸҜиҜ»зҡ„ж јејҸгҖӮиҝҷж„Ҹе‘ізқҖе…¬е…ұж•°жҚ®зҡ„е…¬ејҖдёҚеҶҚжҳҜж”ҝзӯ–еұӮйқўзҡ„规е®ҡпјҢиҖҢжҲҗдёәж”ҝеәңзҡ„дёҖйЎ№жі•е®ҡд№үеҠЎгҖӮ 3.е®һи·өдёӯж•°жҚ®иҺ·еҸ–зҡ„дё»иҰҒ规еҲҷгҖӮе…¶дёҖпјҢж•°жҚ®еҲ©з”Ёе®һи·өпјҡеҗҲеҗҢзәҰе®ҡдёәдё»гҖӮзҫҺеӣҪжңӘеңЁз«Ӣжі•еұӮйқўеҜ№ж•°жҚ®жҺ§еҲ¶еҲ©зӣҠиҝӣиЎҢеҲҶй…ҚпјҢжӯЈеҰӮ欧зӣҹеҲҶжһҗж–Ү件дҪңеҮәзҡ„иҜ„д»·пјҢзҫҺеӣҪжҳҜвҖңе°Ҷж•°жҚ®жүҖжңүжқғзҡ„й—®йўҳз•ҷз»ҷдәҶеҗ„дёӘеҗҲеҗҢвҖқгҖӮвҖңеҶңеңәж•°жҚ®еҺҹеҲҷвҖқжҳҜзҫҺеӣҪе®һи·өдёӯд»ҘеҗҲеҗҢ规иҢғж•°жҚ®еҲ©з”Ёе’ҢиҺ·еҸ–规еҲҷзҡ„дҫӢеӯҗгҖӮзҫҺеӣҪеҶңеңәеұҖиҒ”еҗҲдјҡдёҺе•Ҷе“ҒеӣўдҪ“гҖҒеҶңеңәз»„з»Үе’ҢеҶңдёҡжҠҖжңҜжҸҗдҫӣе•ҶеҗҲдҪңпјҢдәҺ2014е№ҙе…ұеҗҢеҲ¶е®ҡе’ҢжҺЁе№ҝдәҶдёҖйЎ№еҶңеңәж•°жҚ®еҺҹеҲҷгҖӮеңЁж•°жҚ®жүҖжңүжқғзҡ„规еҲ¶дёҠпјҢе…¶жҸҗеҮәвҖңиӮҜе®ҡеҶңж°‘жӢҘжңүжңүе…іе…¶еҶңдёҡз»ҸиҗҘзҡ„дҝЎжҒҜгҖӮеҗҢж—¶пјҢеҶңж°‘жңүиҙЈд»»дёҺе…¶д»–еҲ©зӣҠзӣёе…іиҖ…пјҲдҫӢеҰӮпјҢз§ҹжҲ·гҖҒеңҹең°жүҖжңүиҖ…гҖҒеҗҲдҪңзӨҫгҖҒзІҫеҮҶеҶңдёҡзі»з»ҹ硬件зҡ„жүҖжңүиҖ…е’ҢпјҸжҲ–еҶңдёҡжҠҖжңҜжҸҗдҫӣе•Ҷзӯүпјүе°ұж•°жҚ®дҪҝз”Ёе’Ңе…ұдә«иҫҫжҲҗдёҖиҮҙвҖқгҖӮеҶңеңәж•°жҚ®еҺҹеҲҷиҝҳеҜ№зӣёе…іеҶңдёҡж•°жҚ®зҡ„收йӣҶи®ҝй—®жҺ§еҲ¶и§„еҲҷгҖҒйҖҸжҳҺеәҰгҖҒеҸҜ移жӨҚжҖ§зӯүиҝӣиЎҢдәҶ规е®ҡгҖӮ е…¶дәҢпјҢзә зә·и§ЈеҶіе®һи·өпјҡCFAAжҲҗдёәдё»иҰҒдҫқжҚ®гҖӮеҜ№дәҺе®һи·өдёӯзҡ„ж•°жҚ®зә зә·пјҢзҫҺеӣҪ1986е№ҙгҖҠи®Ўз®—жңәж¬әиҜҲдёҺж»Ҙз”Ёжі•гҖӢпјҲComputer Fraud and Abuse Act, CFAAпјүжҲҗдёәеӨ„зҗҶж•°жҚ®еҲ©з”Ёзә зә·пјҢе°Өе…¶жҳҜзҲ¬иҷ«зұ»жЎҲ件зҡ„дё»иҰҒдҫқжҚ®гҖӮе…¶1030(a)(5)(A)(2008)жқЎжҳҺ确规еҲ¶дәҶж•°жҚ®и®ҝй—®иЎҢдёәпјҢеҚівҖңжңӘз»ҸжҺҲжқғж•…ж„Ҹи®ҝй—®и®Ўз®—жңәжҲ–и¶…иҝҮжҺҲжқғи®ҝй—®жқғйҷҗпјҢд»ҺиҖҢд»Һд»»дҪ•еҸ—дҝқжҠӨзҡ„и®Ўз®—жңәиҺ·еҸ–дҝЎжҒҜвҖқпјӣжҲ–иҖ…иў«е‘ҠвҖңж•…ж„ҸйҖ жҲҗзЁӢеәҸдј иҫ“пјҢ并且еҜ№жңӘз»ҸжҺҲжқғдё”еҸ—дҝқжҠӨзҡ„и®Ўз®—жңәйҖ жҲҗжҚҹе®івҖқпјҢеқҮеұһзҠҜзҪӘиЎҢдёәгҖӮеңЁжӯӨжЎҶжһ¶дёӢпјҢж•°жҚ®зҲ¬еҸ–иЎҢдёәжҳҜеҗҰе…·жңүеҸҜи°ҙиҙЈжҖ§дҫқиө–дәҺеҜ№вҖңжңӘз»ҸжҺҲжқғжҲ–и¶…и¶ҠжҺҲжқғвҖқдёҺвҖңеҸ—дҝқжҠӨзҡ„и®Ўз®—жңәвҖқзҡ„и®Өе®ҡгҖӮжҚўиЁҖд№ӢпјҢдҫөжқғи®Өе®ҡзҡ„е…ій”®жҳҜж•°жҚ®жүҖеңЁзҡ„и®Ўз®—жңәзі»з»ҹзҡ„и®ҝ问规еҲҷпјҢиҖҢйқһж•°жҚ®жң¬иә«зҡ„жқғеұһгҖӮ иҫғй•ҝдёҖж®өж—¶й—ҙеҶ…пјҢе№іеҸ°еҚ•ж–№йқўзҡ„еЈ°жҳҺгҖҒе‘ҠзҹҘгҖҒиӯҰе‘ҠгҖҒзҰҒжӯўзҲ¬иҷ«зҡ„еј№зӘ—гҖҒжҲ–иҖ…еҗҲеҗҢгҖҒдә§е“ҒжҲ–жңҚеҠЎдёӯзҡ„еӨҮжіЁиҜҙжҳҺи§ЈйҮҠгҖҒжңҖз»Ҳз”ЁжҲ·еҚҸи®®зӯүпјҢйғҪеҸҜд»ҘдҪңдёәйҷҗе®ҡж•°жҚ®и®ҝй—®жқғйҷҗзҡ„дҫқжҚ®гҖӮдҫӢеҰӮпјҢеңЁвҖңCollege Source v. Academy OneжЎҲвҖқдёӯпјҢжі•йҷўи®Өе®ҡеҰӮжһңзҪ‘з«ҷзҡ„дҪҝз”ЁжқЎж¬ҫйҷҗе®ҡдәҶж•°жҚ®и®ҝй—®иҢғеӣҙпјҢи¶…еҮәиҢғеӣҙзҡ„и®ҝй—®еҚіеҸҜжһ„жҲҗCFAAж„Ҹд№үдёҠвҖңжңӘз»ҸжҺҲжқғзҡ„и®ҝй—®вҖқгҖӮеңЁвҖңCraigslist v. 3TapsжЎҲвҖқдёӯпјҢзҪ‘з«ҷдәӢеҗҺйҮҮеҸ–зҡ„еЈ°жҳҺе’ҢжҠҖжңҜжүӢж®өиў«жі•йҷўи®ӨеҸҜдёәзЎ®е®ҡи®ҝй—®жқғйҷҗзҡ„ж–№ејҸгҖӮ然иҖҢпјҢиҝҷз§ҚдёҘж јзҡ„вҖңжңӘз»ҸжҺҲжқғвҖқзҡ„и®Өе®ҡпјҢдәӢе®һдёҠйҖ жҲҗе№іеҸ°еҸҜд»ҘеҮӯеҚ•ж–№йқўж„Ҹеҝ—зүўзүўжҺ§еҲ¶ж•°жҚ®пјҢCFAAд№ҹеӣ иҝҮдәҺе®Ҫжіӣе’ҢдёҚзЎ®е®ҡзҡ„规еҲ¶иҢғеӣҙиҖҢеҸ—еҲ°иҜҹз—…гҖӮ еңЁ2017е№ҙвҖңHiq v. LinkedinжЎҲвҖқдёӯпјҢиҝҷз§Қи¶ӢеҠҝеҫ—еҲ°дәҶдҝ®жӯЈгҖӮзҫҺеӣҪ第д№қе·ЎеӣһдёҠиҜүжі•йҷўи®Өе®ҡпјҢжҠ“еҸ–ж— йңҖжҺҲжқғеҚіеҸҜи®ҝй—®зҡ„ж•°жҚ®е’Ңй»ҳи®Өе…Қиҙ№еҸҜеҫ—зҡ„ж•°жҚ®дёҚеұһдәҺиҝқжі•зҡ„вҖңжңӘз»ҸжҺҲжқғвҖқзҡ„жҠ“еҸ–пјҢ并жҳҺзЎ®д»…еҮӯе№іеҸ°еҚ•ж–№йқўзҡ„вҖңдҪҝз”ЁжқЎж¬ҫвҖқдёҚеҫ—и§ҰеҸ‘CFAAгҖӮеңЁ2021е№ҙвҖңVan Buren v. United StatesжЎҲвҖқдёӯпјҢзҫҺеӣҪжңҖй«ҳжі•йҷўиҝӣдёҖжӯҘжҳҺзЎ®йҷҗзј©дәҶCFAAзҡ„йҖӮз”ЁиҢғеӣҙпјҢжҢҮеҮәеҰӮжһңжҹҗдәәжңүжқғи®ҝй—®и®Ўз®—жңәдёҠзҡ„ж•°жҚ®пјҢеҚідҪҝеҸҜиғҪж»Ҙз”ЁдәҶиҝҷз§Қи®ҝй—®зҡ„жқғйҷҗпјҲдҫӢеҰӮпјҢеҮәдәҺдёҚиў«е…Ғи®ёзҡ„зӣ®зҡ„пјүпјҢ并дёҚиҝқеҸҚCFAAгҖӮеҜ№CFAAзҡ„йҷҗзј©и§ЈйҮҠпјҢе®һйҷ…дёҠйҮҠж”ҫдәҶжӣҙеӨҡж•°жҚ®иҺ·еҸ–зҡ„з©әй—ҙгҖӮ д»Һз«Ӣжі•еұӮйқўпјҢзӣёиҫғдәҺ欧зӣҹеҜ№ж•°жҚ®иҺ·еҸ–дҝқжҠӨзӯүй—®йўҳзҡ„з§ҜжһҒжҺўзҙўпјҢзҫҺеӣҪдјјд№Һ并дёҚзғӯиЎ·дәҺеҸҠж—¶жҺЁиЎҢдёҖеҘ—ж•°жҚ®жІ»зҗҶзҡ„жі•еҫӢжЎҶжһ¶пјҢиҖҢжҳҜеҹәдәҺдҝЎжҒҜиҮӘз”ұеҺҹеҲҷпјҢеҜ№ж•°жҚ®и§„еҲ¶з§үжҢҒиҫғдёәе®Ҫжқҫеј№жҖ§зҡ„жҖҒеәҰпјҢ并йҮҚи§ҶеёӮеңәз«һдәүдёҺж•°жҚ®иҺ·еҸ–иҮӘз”ұгҖӮеҜ№жӯӨпјҢжңүзҫҺеӣҪеӯҰиҖ…жү№иҜ„зҫҺеӣҪеҜ№ж•°жҚ®й—®йўҳзҡ„е…іжіЁйӣҶдёӯдәҺйҡҗз§ҒгҖҒеҸҚеһ„ж–ӯзӯүй—®йўҳпјҢиҝҮдәҺзӢӯйҡҳпјӣиҖҢеҜ№дәҺж•°жҚ®д»·еҖјз•Ңе®ҡе’Ңдҝғиҝӣж•°жҚ®ејҖж”ҫжөҒеҠЁзӯүдёҖзі»еҲ—ж•°жҚ®жҪңеҠӣеҸ‘жҢҘзҡ„е…ій”®жҖ§й—®йўҳпјҢд»Қ然关注дёҚи¶іпјҢе‘јеҗҒвҖңзҫҺеӣҪйңҖиҰҒдёәж•°жҚ®ж—¶д»ЈеҲ¶е®ҡ新规еҲҷвҖқгҖӮиҖҢд»Һзӣ®еүҚзҫҺеӣҪеҸёжі•е®һи·өи§Ӯд№ӢпјҢзҫҺеӣҪе°ҡжңӘеҮәзҺ°ж•°жҚ®жі•еҫӢ规еҲҷдҫӣз»ҷдёҚи¶іиҖҢж— еҠӣи§ЈеҶідјҒдёҡй—ҙж•°жҚ®зә зә·зҡ„жғ…еҶөпјӣд»Һж•°жҚ®дә§дёҡе®һи·өи§Ҷд№ӢпјҢд№ҹе°ҡдёҚеӯҳеңЁеӣ еҜ№ж•°жҚ®дҝқжҠӨеҠӣеәҰдёҚи¶іиҖҢжҠ‘еҲ¶дә§дёҡеҸ‘еұ•зҡ„жғ…еҶөгҖӮ ж—Ҙжң¬зҡ„ж•°жҚ®жІ»зҗҶ规еҲҷгҖӮж—Ҙжң¬еҜ№ж•°жҚ®жІ»зҗҶйҮҮеҸ–иЎҢдёә规еҲ¶и·Ҝеҫ„пјҢйҖҡиҝҮгҖҠеҸҚдёҚжӯЈеҪ“з«һдәүжі•гҖӢ规еҲ¶дёҚжӯЈеҪ“иҺ·еҸ–гҖҒдҪҝз”ЁгҖҒжҠ«йңІж•°жҚ®зҡ„иЎҢдёәгҖӮдҪңдёәдё–з•ҢдёҠжһҒе°‘ж•°жӯЈејҸеӣһеә”ж•°жҚ®иҺ·еҸ–规еҲҷзҡ„з«Ӣжі•пјҢдҝ®и®ўеҗҺзҡ„гҖҠеҸҚдёҚжӯЈеҪ“з«һдәүжі•гҖӢиў«ж—Ҙжң¬дёҡз•Ңз§°дёәвҖңдё–з•ҢдёҠйҰ–йғЁиҜ•еӣҫдҝқжҠӨеӨ§ж•°жҚ®жң¬иә«зҡ„жі•еҫӢвҖқгҖӮ 1.вҖңйҷҗе®ҡжҸҗдҫӣж•°жҚ®вҖқеҸ—гҖҠеҸҚдёҚжӯЈеҪ“з«һдәүжі•гҖӢдҝқжҠӨгҖӮж—Ҙжң¬гҖҠеҸҚдёҚжӯЈеҪ“з«һдәүжі•гҖӢеңЁ2018е№ҙз»ҸиҝҮдәҶдҝ®и®ўпјҢ并дәҺ2019е№ҙ7жңҲ1ж—ҘжӯЈејҸз”ҹж•ҲпјҢж–°жі•е°Ҷ第дёүж–№д»Ҙз»ҸиҗҘдёәзӣ®зҡ„дёҚжӯЈеҪ“иҺ·еҸ–гҖҒдҪҝз”Ёд»ҘеҸҠе…¬ејҖвҖңйҷҗе®ҡжҸҗдҫӣж•°жҚ®вҖқзҡ„иЎҢдёәжҳҺзЎ®дёәдёҖзұ»дёҚжӯЈеҪ“з«һдәүиЎҢдёәгҖӮ е…·дҪ“иҖҢиЁҖпјҢеҸ—гҖҠеҸҚдёҚжӯЈеҪ“з«һдәүжі•гҖӢдҝқжҠӨзҡ„ж•°жҚ®еҝ…йЎ»ж»Ўи¶іеӣӣдёӘиҰҒ件пјҡпјҲ1пјүжҠҖжңҜз®ЎзҗҶжҖ§пјҢжҢҮж•°жҚ®еҝ…йЎ»йҖҡиҝҮйҖӮеҪ“зҡ„з”өзЈҒи®ҝй—®жҺ§еҲ¶жүӢж®өз®ЎзҗҶпјҲеҰӮеҠ еҜҶпјүпјҢдё”еӯҳеңЁжҳҺзЎ®зҡ„з®ЎзҗҶж„ҸеӣҫпјҲзұ»дјјдәҺе•Ҷдёҡз§ҳеҜҶзҡ„дҝқеҜҶиҰҒ件пјүпјӣпјҲ2пјүеҗҲзҗҶзҙҜи®ЎжҖ§пјҢжҢҮеҸ—дҝқжҠӨзҡ„ж•°жҚ®йңҖиҰҒж»Ўи¶ідёҖе®ҡйҮҸзҡ„з§ҜзҙҜпјҢе…·дҪ“зҡ„ж•°йҮҸеә”ж №жҚ®ж•°жҚ®зҡ„жҖ§иҙЁеҶіе®ҡпјӣпјҲ3пјүжңүйҷҗжҸҗдҫӣжҖ§пјҢеҚіж•°жҚ®еҝ…йЎ»еә”жҳҜеә”еӨ–з•ҢиҰҒжұӮвҖңжңүйҖүжӢ©жҖ§вҖқең°д»…еҗ‘зү№е®ҡеҜ№иұЎжҸҗдҫӣпјӣпјҲ4пјүеҶ…е®№зү№е®ҡжҖ§пјҢж•°жҚ®еә”еҪ“еұһдәҺе…·жңүе•Ҷдёҡд»·еҖјзҡ„жҠҖжңҜдҝЎжҒҜжҲ–з»ҸиҗҘдҝЎжҒҜпјҢдё”дёҚеҫ—еҢ…еҗ«д»»дҪ•йқһжі•жҲ–дёҚйҒ“еҫ·еҶ…е®№гҖӮжӯӨеӨ–пјҢдёәдәҶйҒҝе…ҚжқғеҲ©йҮҚеҸ жҲ–йҳ»зўҚдҝЎжҒҜжөҒйҖҡпјҢж—Ҙжң¬гҖҠеҸҚдёҚжӯЈеҪ“з«һдәүжі•гҖӢжҳҺзЎ®дәҶйҷӨеӨ–жқЎж¬ҫпјҢ规е®ҡдҝқжңүиҖ…дҪңдёәз§ҳеҜҶиҝӣиЎҢз®ЎзҗҶзҡ„ж•°жҚ®е’ҢдёҺе…¬дј—еҸҜд»Ҙж— еҒҝеҲ©з”Ёзҡ„дҝЎжҒҜзӣёеҗҢзҡ„ж•°жҚ®пјҢдёҚеҫ—дҪңдёәйҷҗе®ҡжҸҗдҫӣзҡ„ж•°жҚ®иҝӣиЎҢдҝқжҠӨгҖӮ еҜ№дәҺеҸ—дҝқжҠӨзҡ„ж•°жҚ®пјҢвҖңжңӘз»ҸжҺҲжқғзҡ„иҺ·еҸ–вҖқгҖҒвҖңдёҘйҮҚиҝқеҸҚиҜҡдҝЎеҺҹеҲҷвҖқе’ҢвҖңеҗҺз»ӯжҒ¶ж„ҸиҪ¬еҫ—вҖқдёүз§ҚиЎҢдёәе°Ҷиў«и§ҶдёәдёҚжӯЈеҪ“з«һдәүиЎҢдёәгҖӮжңӘз»ҸжҺҲжқғиҺ·еҸ–жҢҮйҖҡиҝҮжҒ¶ж„ҸжүӢж®өпјҲзӣ—зӘғгҖҒж¬әиҜҲгҖҒиғҒиҝ«жҲ–е…¶д»–дёҚжӯЈеҪ“жүӢж®өпјүиҺ·еҸ–еҸ—дҝқжҠӨж•°жҚ®зҡ„иЎҢдёәпјӣвҖңеҮәдәҺдёҚеҪ“收зӣҠжҲ–еҜ№еҸ—дҝқжҠӨж•°жҚ®жүҖжңүиҖ…йҖ жҲҗжҚҹе®ізҡ„зӣ®зҡ„вҖқпјҢ并еҗҢж—¶вҖңиҝӣиЎҢиҝқеҸҚжңүе…іеҸ—дҝқжҠӨж•°жҚ®з®ЎзҗҶиҒҢиҙЈзҡ„иЎҢдёәвҖқеұһдәҺвҖңдёҘйҮҚиҝқеҸҚиҜҡдҝЎеҺҹеҲҷвҖқзҡ„ж•°жҚ®дёҚжӯЈеҪ“з«һдәүиЎҢдёәпјӣ第дёүз§ҚвҖңеҗҺз»ӯжҒ¶ж„ҸиҪ¬еҫ—вҖқеҲҷжҢҮиҺ·еҸ–ж•°жҚ®зҡ„дәәзҹҘйҒ“еҸ‘з”ҹдәҶдёҺиҜҘж•°жҚ®жңүе…ізҡ„дёҚжӯЈеҪ“иЎҢдёәпјҢдҪҶд»Қ然继з»ӯиҺ·еҸ–гҖҒдҪҝз”Ёж•°жҚ®жҲ–е°Ҷж•°жҚ®жҸҗдҫӣз»ҷ第дёүж–№гҖӮ еңЁжі•еҫӢиҙЈд»»ж–№йқўпјҢж—Ҙжң¬иөӢдәҲж•°жҚ®жҺ§еҲ¶иҖ…еҒңжӯўдҫөе®ігҖҒеәҹејғдҫөжқғе·Ҙе…·гҖҒеәҹејғдҫөжқғдә§е“Ғзӯүе·®жӯўиҜ·жұӮжқғгҖҒжҚҹе®іиө”еҒҝиҜ·жұӮжқғе’ҢдҝЎз”ЁжҒўеӨҚзӯүж°‘дәӢж•‘жөҺжҺӘж–ҪгҖӮеңЁдҝ®жі•иҝҮзЁӢдёӯпјҢж—Ҙжң¬жӣҫи®Ёи®әеј•е…ҘеҲ‘дәӢжҺӘж–ҪгҖӮдҪҶеҹәдәҺеҜ№еҲ‘дәӢеҲ¶иЈҒзҡ„еј•е…ҘеҸҜиғҪйҖ жҲҗж•°жҚ®дәӨжҳ“ж»һзј“еҗҺжһңзҡ„жӢ…еҝ§пјҢж—Ҙжң¬гҖҠеҸҚдёҚжӯЈеҪ“з«һдәүжі•гҖӢзҡ„ж•°жҚ®йҷҗе®ҡжқЎж¬ҫ并жңӘи®ҫзҪ®еҲ‘дәӢиҙЈд»»гҖӮ 2.иЎҢдёәжі•дёӢзҡ„ејұдҝқжҠӨжЁЎејҸгҖӮдёҖж–№йқўпјҢеҹәдәҺдҝғиҝӣж•°жҚ®жөҒеҠЁгҖҒйҳІжӯўйҳ»жҠ‘еҗҺз»ӯеҲӣж–°зҡ„иҖғйҮҸпјҢж—Ҙжң¬е№¶жңӘиҖғиҷ‘еҜ№ж•°жҚ®жҸҗдҫӣжҺ’д»–жқғдҝқжҠӨпјҢиҖҢжҳҜд»ҘгҖҠеҸҚдёҚжӯЈеҪ“з«һдәүжі•гҖӢ规еҲ¶ж•°жҚ®еҲ©з”ЁиЎҢдёәпјӣеҸҰдёҖж–№йқўпјҢж¶үеҸҠдҫөзҠҜвҖңйҷҗе®ҡжҸҗдҫӣзҡ„ж•°жҚ®вҖқзҡ„иЎҢдёәиҢғеӣҙд№ҹжҳҫи‘—зӘ„дәҺдҫөзҠҜе•Ҷдёҡз§ҳеҜҶзҡ„иЎҢдёәгҖӮжҚўиЁҖд№ӢпјҢеңЁж—Ҙжң¬пјҢж•°жҚ®еҸ—дҝқжҠӨзҡ„еҠӣеәҰдәӢе®һдёҠдҪҺдәҺе•Ҷдёҡз§ҳеҜҶгҖӮдҫӢеҰӮпјҢж—Ҙжң¬гҖҠеҸҚдёҚжӯЈеҪ“з«һдәүжі•гҖӢ规е®ҡжҒ¶ж„ҸжҲ–иҖ…йҮҚеӨ§иҝҮеӨұиҖ…иҪ¬еҫ—гҖҒдҪҝз”ЁгҖҒжҠ«йңІе•Ҷдёҡз§ҳеҜҶзҡ„иЎҢдёәпјҢеқҮеұһдёҚжӯЈеҪ“з«һдәүиЎҢдёәпјӣиҖҢйҮҚеӨ§иҝҮеӨұзҡ„жғ…еҶөдёӢиҪ¬еҫ—гҖҒдҪҝз”ЁгҖҒжҠ«йңІйҷҗе®ҡжҸҗдҫӣж•°жҚ®е№¶дёҚжһ„жҲҗдёҚжӯЈеҪ“з«һдәүгҖӮеҜ№жӯӨпјҢд№ҹжңүеӯҰиҖ…иҙЁз–‘ж—Ҙжң¬еҜ№ж•°жҚ®зҡ„дҝқжҠӨеҠӣеәҰдёҚи¶іпјҢйҡҫд»Ҙжңүж•Ҳз»ҙжҠӨж•°жҚ®д»ҺдёҡиҖ…зҡ„еҲ©зӣҠгҖӮеҗҢж—¶пјҢзӣёиҫғдәҺеҜ№жі„йңІе•Ҷдёҡз§ҳеҜҶиЎҢдёәзҡ„еҲ‘дәӢеӨ„зҪҡпјҢж—Ҙжң¬е№¶жңӘеҜ№дёҚжӯЈеҪ“иҺ·еҸ–гҖҒдҪҝз”ЁжҲ–иҖ…жҠ«йңІж•°жҚ®зҡ„з«һдәүиЎҢдёәи®ҫзҪ®еҲ‘дәӢиҙЈд»»гҖӮиҝҷдҪ“зҺ°еҮәеҪ“еүҚж—Ҙжң¬з«Ӣжі•иҖ…еҜ№дәҺж•°жҚ®зҡ„жҖҒеәҰд»Қ然жҳҜиҫғдёәи°Ёж…Һзҡ„гҖӮиҷҪ然дёҺе…¶д»–еӣҪ家зӣёжҜ”пјҢж—Ҙжң¬иҫғж—©ең°д»Ҙз«Ӣжі•еҪўејҸжҳҺзЎ®дәҶж•°жҚ®еҲ©зӣҠеҪ’еұһпјҢдҪҶе…¶д»Қ然йқһеёёйҮҚи§Ҷж•°жҚ®жҺ§еҲ¶дёҺиҺ·еҸ–дҪҝз”Ёй—ҙзҡ„е№іиЎЎпјҢйҳІжӯўе°Ҷж•°жҚ®еҲ©зӣҠд№ӢвҖңзҪ‘вҖқй“әеҫ—иҝҮеӨ§пјҢйҷҗеҲ¶ж•°жҚ®дҪҝз”Ёжҙ»еҠӣгҖӮ д»ҺеҹҹеӨ–е·Іжңүзҡ„з«Ӣжі•е®һи·өи§Ӯд№ӢпјҢ欧зӣҹеёҢжңӣе»әжһ„ж•°жҚ®з»јеҗҲжІ»зҗҶзҡ„е®Ңе–„жЎҶжһ¶пјҢзҫҺеӣҪејәи°ғж•°жҚ®зҡ„еҲ©з”ЁиҮӘз”ұпјҢж—Ҙжң¬д»ҘиЎҢдёә法规еҲ¶ж•°жҚ®иҺ·еҸ–гҖҒдҪҝз”ЁжҠ«йңІиЎҢдёәгҖӮиҷҪ然еҗ„еӣҪеҜ№ж•°жҚ®зҡ„жІ»зҗҶжҖҒеәҰе’Ң规еҲ¶жҖқи·ҜдёҚе°ҪзӣёеҗҢпјҢдҪҶйғҪеҸҚжҳ еҮәеҜ№ж•°жҚ®ејҖж”ҫиҺ·еҸ–зҡ„йҮҚи§ҶпјҢд»ҘеҸҠеҜ№е…¬е…ұж•°жҚ®зҡ„е…¬ејҖеҸҜз”ЁжҖ§зҡ„е…іжіЁгҖӮжӯӨеӨ–пјҢеҗ„еӣҪеқҮејәи°ғж•°жҚ®дҝқжҠӨдёҺж•°жҚ®еҲ©з”Ёзҡ„е№іиЎЎгҖӮеҰӮдҪ•иө°еҮәдёҖжқЎж—ўиғҪдҝқжҠӨж•°жҚ®жҠ•иө„зҡ„е…¬е№іеҲ©зӣҠгҖҒеҸҲиғҪдҝғиҝӣж•°жҚ®жөҒеҠЁе’ҢеҲ©з”Ёзҡ„е№іиЎЎжІ»зҗҶи·Ҝеҫ„пјҢд№ҹжҳҜеӣҪйҷ…зҗҶи®әз•Ңд»ҚеңЁдәүи®әжҺўзҙўзҡ„з„ҰзӮ№й—®йўҳгҖӮ 03 еҚҸи°ғж•°жҚ®иҺ·еҸ–дёҺдҝқжҠӨзҡ„зҗҶи®әдәүйёЈ еҗ„жі•еҹҹж•°жҚ®жІ»зҗҶз«Ӣжі•гҖҒеҸёжі•е®һи·өзҡ„иғҢеҗҺпјҢжҳҜеӯҰжңҜи®Ёи®әдёӯжңүе…іж•°жҚ®жІ»зҗҶи·Ҝеҫ„жҝҖзғҲзҡ„зҗҶи®әдәүйёЈгҖӮе…¶дёӯпјҢж•°жҚ®иҙўдә§жқғзҡ„жһ„йҖ е’ҢжқғиЎЎжҳҜж•°жҚ®жІ»зҗҶз„ҰзӮ№и®әйўҳгҖӮ ж•°жҚ®иөӢжқғиҝӣи·ҜдёҺеҸҚжҖқгҖӮеҗҢдёәж— дҪ“иҙўдә§пјҲеҸҲз§°ж— еҪўиҙўдә§пјүпјҢж•°жҚ®дјјд№Һе’ҢзҹҘиҜҶдә§жқғзҡ„е®ўдҪ“е…·жңүеӨ©з„¶зҡ„дәІзјҳе…ізі»гҖӮеҗҢж—¶пјҢзҹҘиҜҶдә§жқғеҲ¶еәҰиў«и®ӨдёәжҳҜдёҖз§ҚдҝғиҝӣеҲӣж–°гҖҒйј“еҠұзҹҘиҜҶдј ж’ӯзҡ„жңүж•ҲжҝҖеҠұжңәеҲ¶пјҢиҝҷдёҺдҝғиҝӣж•°жҚ®д»·еҖје®һзҺ°зҡ„йҖ»иҫ‘дјјд№ҺзӣёеҘ‘еҗҲгҖӮеӣ жӯӨпјҢжӢҹе®ҡвҖңзҹҘиҜҶдә§жқғејҸвҖқзҡ„иҙўдә§жқғдҝқжҠӨжЁЎејҸпјҢдјјд№ҺжҲҗдёәи®әеҸҠж•°жҚ®и§„еҲҷжһ„е»әзҡ„дёҖз§Қзӣҙи§үгҖӮ 1.ж— еҪўиҙўдә§дҝқжҠӨзҡ„иҢғжң¬пјҡдәӨжҳ“дҫҝеҲ©дёҺжҠ•иө„йј“еҠұгҖӮвҖңиөӢжқғдҝқжҠӨиҜҙвҖқзҡ„йҖ»иҫ‘иө·зӮ№еёёеёёжҳҜе°Ҷе®һи·өдёӯзҡ„ж•°жҚ®еҲ©з”Ёдәүи®®пјҢеҪ’з»“дәҺж•°жҚ®жқғеұһзјәд№Ҹжі•еҫӢз•Ңе®ҡе’ҢдҝқйҡңгҖӮдёҖж–№йқўпјҢжҲ‘еӣҪеӨҡ家еӨ§ж•°жҚ®дәӨжҳ“жүҖзӣёз»§жҢӮзүҢпјҢж•°жҚ®дәӨжҳ“зҡ„зғӯеҲҮйңҖжұӮж—©е·Іиў«еӣҪеҶ…еӨ–ж•°жҚ®е®һи·өиҜҒжҲҗпјӣеҸҰдёҖж–№йқўпјҢе°ҶжқғеҲ©еҪ’еұһе°ҡеӨ„вҖңжҡ§жҳ§зҠ¶жҖҒвҖқзҡ„е®ўдҪ“иҝӣиЎҢеёӮеңәдәӨжҳ“пјҢдјјд№Һйҡҗеҗ«зқҖжҹҗз§ҚдёҚжӯЈеҪ“жҖ§е’ҢйЈҺйҷ©жҖ§гҖӮдё»еҠЁзҡ„ж•°жҚ®дәӨжҳ“д№ӢеӨ–пјҢж•°жҚ®зҲ¬еҸ–е’ҢзӘғеҸ–зӯүдёҚжӯЈеҪ“еҲ©з”ЁиЎҢдёәпјҢд№ҹдҪҝдјҒдёҡеӮ¬з”ҹеҮәејәзғҲзҡ„ж•°жҚ®дҝқжҠӨиҜүжұӮгҖӮдҫқйқ зҺ°жңүзҡ„жі•еҫӢиө„жәҗвҖ”вҖ”зҹҘиҜҶдә§жқғжі•гҖҒе•Ҷдёҡз§ҳеҜҶе’ҢеҗҲеҗҢгҖҒжҠҖжңҜжҺӘж–ҪзӯүжүӢж®өпјҢеҸҜиғҪж— жі•е®Ңе…Ёи§ЈеҶіж•°жҚ®жҺ§еҲ¶иҖ…жӢ…еҝғзҡ„ж•°жҚ®жҢӘз”Ёй—®йўҳгҖӮж•°жҚ®жҺ§еҲ¶иҖ…еҸҜиғҪеҖҫеҗ‘дәҺйҮҮеҸ–еҗ„з§ҚжүӢж®өеҠ ејәеҜ№ж•°жҚ®зҡ„зӢ¬еҚ пјҢ并жҺ’ж–Ҙж•°жҚ®е…ұдә«гҖҒйҳ»жҠ‘ж•°жҚ®зҡ„еҸҜиҺ·еҸ–жҖ§гҖӮеҗҢж—¶пјҢеңЁж•°жҚ®дәӨжҳ“е®һи·өдёӯпјҢе®Ңе…Ёдҫқиө–еҗҲеҗҢжқЎж¬ҫеӨ„зҗҶж•°жҚ®жҺ§еҲ¶иҖ…е’ҢдҪҝз”ЁиҖ…д№Ӣй—ҙзҡ„е…ізі»пјҢд№ҹиў«и®Өдёәзјәд№Ҹжі•еҫӢдёҠзҡ„зЎ®е®ҡжҖ§пјҢз”ұжӯӨдә§з”ҹзҡ„жі•еҫӢйЈҺйҷ©е’Ңе’ЁиҜўжҲҗжң¬жҲҗдёәж•°жҚ®иҺ·еҸ–зҡ„йҮҚиҰҒйҡңзўҚд№ӢдёҖгҖӮ дә§жқғеҲ¶еәҰзҡ„йҮҚиҰҒж„Ҹд№үеңЁдәҺеҪўжҲҗеёӮеңәпјҢеҜ№жҹҗдёҖзү©жҺҲдәҲжқғеҲ©еҸҜд»ҘдҪҝжҪңеңЁзҡ„дәӨжҳ“иҖ…жҳҺзҷҪеҗ‘и°Ғд»ҳиҙ№пјҢиҖҢдә§жқғз»“жһ„жҳҜеҲӣйҖ жңүж•ҲзҺҮзҡ„еёӮеңәзҡ„е…ій”®пјҢеёӮеңәзҡ„жңүж•ҲжҖ§йҖҡеёёиў«и®Өдёәдҫқиө–дәҺдә§жқғзҡ„е……еҲҶз•Ңе®ҡе’ҢиЎҢдҪҝгҖӮзҺ°д»ЈзҹҘиҜҶдә§жқғеҲ¶еәҰеҚіжҳҜеңЁж— еҪўе®ўдҪ“дёҠпјҢжҜ”з…§жңүдҪ“зү©зҡ„дә§жқғз»“жһ„пјҢйҖҡиҝҮжі•еҫӢиөӢдәҲзҡ„зҰҒз”ЁжқғжқҘй“ёе°ұеёӮеңәзҡ„жҲҗеҠҹиҢғдҫӢгҖӮдёҺжӯӨеҗҢж—¶пјҢж–°еҲ¶еәҰз»ҸжөҺеӯҰејәи°ғдә§жқғдҝқжҠӨе…·жңүйј“еҠұжҠ•иө„зҡ„еҠЁжҖҒ收зӣҠпјҢеҚіжқғеҲ©дәәеҹәдәҺеҜ№е…¶еҲ©зӣҠеҸ—дҝқжҠӨзҡ„зЎ®и®ӨпјҢдҫҝеҸҜж”ҫеҝғеҜ№е…¶иө„жәҗиҝӣиЎҢжҠ•иө„пјҢд»ҘеҲӣйҖ жҲ–ж”№е–„иө„жәҗгҖӮ жҜӢеәёзҪ®з–‘пјҢе……еҲҶжҢ–жҺҳж•°жҚ®жҪңеҠӣгҖҒдҝғиҝӣж•°жҚ®дәӨжҳ“е’ҢдҪҝз”ЁгҖҒж·ұеҢ–ж•°жҚ®жҠ•иө„дёҺиөӢиғҪжҳҜж•°жҚ®жІ»зҗҶзҡ„йҮҚиҰҒзӣ®ж ҮгҖӮеӣ жӯӨпјҢеңЁж•°жҚ®дёҠи®ҫз«ӢдёҖз§Қж–°еһӢиҙўдә§жқғд»ҚжҳҜеӯҰиҖ…жҸҗеҮәзҡ„еҪ»еә•вҖңи§Јй”ҒвҖқеә•еұӮж•°жҚ®пјҢдҝғиҝӣж•°жҚ®иҺ·еҸ–еҲ©з”Ёзҡ„йҮҚиҰҒж–№жЎҲд№ӢдёҖгҖӮ 2.ж•°жҚ®иөӢжқғиҝӣи·Ҝзҡ„еҸҚжҖқгҖӮдёәж•°жҚ®ж–°и®ҫиҙўдә§жқғиғҪеҗҰеӣһеә”еёӮеңәзҡ„йңҖжұӮпјҢе°ҡеҖјеҫ—е®Ўж…ҺжҖқиҖғгҖӮе°Өе…¶жҳҜдёҚе°‘еӯҰиҖ…жҸҗзӨәпјҢж–°еҲӣи®ҫдёҖз§ҚвҖңзҹҘиҜҶдә§жқғејҸвҖқзҡ„ж•°жҚ®жқғпјҢеҸҜиғҪдёҺзҺ°жңүзҹҘиҜҶдә§жқғеҲ¶еәҰеӯҳеңЁдёҖе®ҡзҡ„зҹӣзӣҫе’ҢеҶІзӘҒпјҢеңЁжқғеҲ©жһ„йҖ д№Ӣж—¶еә”еҪ“дәҲд»ҘйҮҚи§ҶгҖӮ е…¶дёҖпјҢжӯЈеҪ“жҖ§зҡ„йҖЎе·ЎгҖӮжқғеҲ©зҡ„е»әжһ„йңҖиҰҒе……еҲҶзҡ„зҗҶи®әж”ҜжҢҒдҪңдёәе…¶жӯЈеҪ“жҖ§еҹәзЎҖгҖӮзҹҘиҜҶдә§жқғеҲ¶еәҰзҡ„дё»иҰҒжӯЈеҪ“жҖ§еҹәзЎҖжҳҜеҠіеҠЁиҙўдә§зҗҶи®әе’ҢеҠҹеҲ©дё»д№үзҡ„жҝҖеҠұзҗҶи®әгҖӮиҖҢеҜ№дәҺж•°жҚ®жІ»зҗҶиҖҢиЁҖпјҢиҝҷдёӨз§ҚзҗҶи®әзҡ„и§ЈйҮҠеҠӣдјјд№ҺйғҪеҖјеҫ—жҖҖз–‘гҖӮ жҙӣе…Ӣз”ЁеҠіеҠЁи®әиҜҒз§Ғжңүиҙўдә§жқғдә§з”ҹзҡ„еҹәзЎҖгҖӮд»–и®Өдёәиҙўдә§еә”иў«е®ҡд№үдёәдёҖз§ҚвҖңзү©еҢ–вҖқзҡ„еҠіеҠЁпјҢжӯЈеҰӮвҖңи°ҒжҠҠд»Һж ‘дёӢжӢҫеҫ—зҡ„ж©ЎжһңжҲ–ж ‘дёҠж‘ҳдёӢзҡ„иӢ№жһңжһңи…№пјҢи°Ғе°ұеҸҜд»ҘжҠҠе®ғ们еҪ’дёәе·ұжңүвҖқгҖӮж•°жҚ®д»ҺеҺҹе§Ӣж•°жҚ®иў«ж•ҙзҗҶжҲҗдёәе…·жңүвҖңеҸҜз”ЁжҖ§вҖқвҖңд»·еҖјжҖ§вҖқзҡ„еўһеҖјж•°жҚ®пјҢдё»иҰҒеҫ—зӣҠдәҺдјҒдёҡеңЁж•°жҚ®ж”¶йӣҶгҖҒеҠ е·ҘгҖҒеӨ„зҗҶиҝҮзЁӢдёӯзҡ„еҠіеҠЁгҖҒиө„йҮ‘зӯүжҠ•е…ҘгҖӮиҝҷз§ҚеҠіеҠЁзҡ„д»·еҖјжҳҜеҖјеҫ—иӮҜе®ҡе’ҢдҝқжҠӨзҡ„пјҢиҝҷд№ҹжҳҜйғЁеҲҶеӯҰиҖ…и®ӨдёәжӯӨзұ»ж•°жҚ®йңҖвҖңиөӢжқғвҖқз»ҷдјҒдёҡзҡ„дё»иҰҒеҺҹеӣ гҖӮ然иҖҢпјҢжҙӣе…Ӣзҡ„еҠіеҠЁиөӢжқғзҗҶи®әж—ЁеңЁиҜҙжҳҺиҙўдә§жқғзҡ„жӯЈеҪ“жҖ§жҳҜе…ҲдәҺж”ҝеәңеӯҳеңЁзҡ„гҖҒеұһдәҺиҮӘ然法дёҠзҡ„жқғеҲ©пјҲиҷҪ然жңүдёҖе®ҡе·Ҙе…·и®әж„Ҹд№үдёҠзҡ„жқғеҲ©пјҢдҪҶд»Қ然ж„ҸеңЁиҰҒжұӮж”ҝеәң规иҢғиҙўдә§ж—¶дёҺиҮӘ然法зҡ„зӣ®ж ҮдҝқжҢҒдёҖиҮҙпјүгҖӮдҪҶж•°жҚ®зҡ„жІ»зҗҶдёҺдҝқжҠӨдё»иҰҒжҳҜеҹәдәҺдёҖе®ҡж”ҝзӯ–зӣ®ж Үзҡ„вҖңеҗҺеӨ©е»әжһ„ејҸвҖқзҡ„пјҢи·қзҰ»иҮӘ然法дёҠжүҖе…·жңүзҡ„зӢ¬з«ӢгҖҒеӨ©з„¶жқғеҲ©жҲ–и®ёзӣёи·қиҫғиҝңгҖӮеҗҢж—¶пјҢжҙӣе…Ӣзҡ„зҗҶи®әеҸӘиғҪдёәиҙўдә§жқғеҲ©вҖңеӯҳеңЁвҖқжҸҗдҫӣдёҖе®ҡзҡ„еҹәзЎҖпјҢиҖҢжӯЈеҰӮиҜәйҪҗе…ӢвҖңи•ғиҢ„й…ұеҖ’иҝӣеӨ§жҙӢвҖқзҡ„з»Ҹе…ёжҜ”е–»пјҢеҠіеҠЁе№¶дёҚиғҪдёәиҙўдә§жқғе®ўдҪ“зҡ„иҢғеӣҙеҲ’е®ҡжҸҗдҫӣд»Җд№Ҳеё®еҠ©гҖӮиҝҷеҜ№еңЁдјҒдёҡж•°жҚ®жқғеҲ©й—®йўҳдёҠе……еҲҶең°иӮҜе®ҡдјҒдёҡдёәж•°жҚ®еӨ„зҗҶжүҖжҠ•е…Ҙзҡ„вҖңеҠіеҠЁвҖқзҡ„д»·еҖјпјҢд»Ҙи®әиҜҒиҝҷйғЁеҲҶвҖңеҠіеҠЁвҖқи¶ід»Ҙиө·еҲ°з•ҢеҲҶдә§жқғиҫ№з•Ңе’Ңеӣәе®ҡжқғеҲ©зҡ„дҪңз”Ёзҡ„дјҒдёҡиҜүжұӮеӣһеә”дёҚи¶ігҖӮ дәӢе®һдёҠпјҢжҙӣе…Ӣзҡ„еҠіеҠЁиөӢжқғзҗҶи®әжңҖеҲқжҳҜй’ҲеҜ№жңүеҪўиҙўдә§жҸҗеҮәзҡ„пјҢд»…йҷҗдәҺвҖңеҜҢйҘ¶зҡ„иҮӘ然зҠ¶жҖҒж—¶жңҹвҖқгҖӮеҪ“иҝҷз§ҚзҗҶи®әзҡ„и§ЈйҮҠеҠӣжү©еұ•еҲ°жҠҪиұЎзү©дёҠпјҢеҜ№иҝҷз§Қе…·жңүжҷ®йҒҚж„Ҹд№үзҡ„иҙўдә§еҠіеҠЁи®әеҲҷеә”и¶іеӨҹи°Ёж…ҺгҖӮеңЁи°Ҳи®әж•°жҚ®иҙўдә§жқғзҡ„жӯЈеҪ“жҖ§еҹәзЎҖж—¶пјҢжӣҙдёҚеә”зүҮйқўең°гҖҒеҝҪи§ҶиҜӯеўғең°зҗҶи§Јжҙӣе…Ӣзҡ„еҠіеҠЁиҙўдә§зҗҶи®әпјҢе°ҶвҖңеҠіеҠЁвҖқдёҺвҖңиҙўдә§жқғвҖқз®ҖеҚ•жҢӮй’©пјҢд№ жғҜдәҺвҖңеҠіеҠЁеә”еҸ—дҝқжҠӨвҖқзҡ„зӣҙи§үжҖ§еҺҹеҲҷпјҢи®ӨдёәдјҒдёҡеҜ№ж•°жҚ®д»ҳеҮәдәҶзІҫеҠӣжҲ–иө„жң¬пјҢжі•еҫӢеҰӮиҰҒиӮҜе®ҡе’ҢдҝқжҠӨиҝҷз§ҚжҠ•е…ҘпјҢе°ұеә”еҪ“з»ҷдәҲжҺ’д»–жҖ§зҡ„иҙўдә§жқғгҖӮеҠіеҠЁиөӢжқғзҡ„иҝҮеәҰжҺЁжј”еҸҜиғҪеёҰжқҘжқғеҲ©жіӣеҢ–зҡ„йЈҺйҷ©пјҢеңЁдјҒдёҡж•°жҚ®й—®йўҳдёҠпјҢд№ҹеә”и°Ёж…Һи®әиҜҒпјҢдёҚеә”еӣ дјҒдёҡзҡ„жҠ•е…Ҙдҫҝе°Ҷиҙўдә§жқғж…·ж…Ёзӣёиө гҖӮ д»ҺиҮӘ然法иҪ¬еҗ‘еҠҹеҲ©дё»д№үпјҢжҠ•иө„жҝҖеҠұеҝ…иҰҒжҖ§зҡ„иҜҒжҲҗд№ҹиҮіе°‘иҰҒе…ҲйҳҗжҳҺдёӨдёӘй—®йўҳпјҡж•°жҚ®з”ҹдә§йўҶеҹҹжҳҜеҗҰзңҹзҡ„еӯҳеңЁжҝҖеҠұдёҚи¶ізҡ„й—®йўҳпјҹиөӢжқғзҡ„жҝҖеҠұж–№ејҸжҳҜеҗҰдёҖе®ҡиғҪеҜ№зӨҫдјҡдә§з”ҹжҖ»дҪ“жӯЈеҗ‘зҡ„жҝҖеҠұж•Ҳжһңпјҹ иҙўдә§жқғзҡ„жі•еҫӢзЎ®и®Өж— з–‘жҳҜдёҖз§ҚжҝҖеҠұжүӢж®өпјҢдҪҶ并йқһе”ҜдёҖзҡ„жүӢж®өгҖӮе°Өе…¶жҳҜеңЁж•°жҚ®й—®йўҳдёҠпјҢжҲ–и®ёеӨёеӨ§дәҶжі•еҫӢжүӢж®өзҡ„дҪңз”ЁпјҢеёӮеңәжҸҗдҫӣзҡ„еә”жҳҜжң¬жәҗжҖ§иҖҢйқһжӣҝд»ЈжҖ§зҡ„жҝҖеҠұжңәеҲ¶гҖӮе°Ҫз®ЎжҲ‘们иҒҡз„ҰдәҺвҖңж•°жҚ®вҖқдёҖиҜҚпјҢдҪҶдјҒдёҡзҡ„еҲ©зӣҠж ёеҝғжҳҫ然并йқһж•°жҚ®жң¬иә«пјҢиҖҢжҳҜж•°жҚ®дёҺе…¶д»–дёҡеҠЎзӣёз»“еҗҲзҡ„йғЁеҲҶгҖӮд»ҺиҝҷдёӘж„Ҹд№үдёҠи®ІпјҢдјҒдёҡж•°жҚ®е…·жңүжӣҙеҠ жө“еҺҡзҡ„е·Ҙе…·жҖ§е’ҢйқһзӢ¬з«ӢжҖ§пјҢеҚіе…¶жң¬иә«е№¶йқһиҙўдә§д»·еҖјд№ӢжәҗпјҢиҖҢйңҖдҫқиө–дёҖз§ҚеӨ–йғЁзҡ„иЎҢдёәзі»з»ҹгҖӮеҚідҪҝдјҒдёҡж•°жҚ®з»Ҹж·ұеәҰеҠ е·ҘпјҢе…·жңүдәҶдёҖе®ҡзҡ„еҸҜи§ҶеҢ–еұһжҖ§пјҢд»Қ然дёҚиғҪеҚіж—¶ең°иҜҒжҲҗд»·еҖјзҡ„дә§з”ҹпјҢж•°жҚ®з”ҹдә§жҳҜд»·еҖјдә§з”ҹзҡ„иө·зӮ№пјҢиҖҢйқһжүҖиҝҪжұӮзҡ„д»·еҖјз»Ҳз«ҜпјҢз”ҡиҮіжңүеҸҜиғҪжҲҗдёәдјҒдёҡдё»иҗҘдёҡеҠЎиҮӘеҠЁдә§з”ҹзҡ„вҖңеүҜдә§е“ҒвҖқгҖӮеңЁж•°еӯ—з»ҸжөҺж—¶д»ЈпјҢдјҒдёҡеңЁиҝӣиЎҢжң¬йўҶеҹҹдёҡеҠЎеҸ‘еұ•зҡ„иҝҮзЁӢдёӯпјҢдёәеҸ–еҫ—з«һдәүдјҳеҠҝйҖҡеёёеҝ…然еӮ¬з”ҹеҮәж•°жҚ®ж”¶йӣҶе’ҢеӨ„зҗҶзӣёе…ізҡ„йңҖжұӮпјҢжӣҙдёҚеҝ…иҜҙеңЁдәәе·ҘжҷәиғҪзӯүжһҒеәҰдҫқиө–ж•°жҚ®зҡ„зү№ж®ҠйўҶеҹҹгҖӮж•°жҚ®жҳҜжҳҫиҖҢжҳ“и§Ғзҡ„еҹәзЎҖиө„жәҗпјҢеҸҜиғҪж— йңҖжӣҙеӨҡзҡ„еӨ–йғЁеҲәжҝҖгҖӮеңЁжӯӨиғҢжҷҜдёӢпјҢеёӮеңәз«һдәүзҡ„еұһжҖ§е’ҢзҺ°е®һзҡ„еҲ©зӣҠй©ұеҠЁи¶ід»ҘжҲҗдёәдёҖз§ҚејәжңүеҠӣзҡ„жҝҖеҠұпјҢвҖңжІЎжңүжі•еҫӢиөӢжқғдҫҝдјҡжҝҖеҠұдёҚи¶івҖқеҫҲеҸҜиғҪеҸӘжҳҜдёҖз§ҚжғіиұЎдёӯзҡ„жӢ…еҝ§пјҢиҮіе°‘е®ғдёҚиғҪеҚ•зӢ¬жҲҗдёәж•°жҚ®иөӢжқғзҡ„е……еҲҶзҗҶз”ұгҖӮ еҗҢж—¶пјҢеҲӣи®ҫиҙўдә§жқғзҡ„жҝҖеҠұж–№ејҸзҗҶи®әдёҠжҳҜйҖ»иҫ‘йҖҡз•…зҡ„пјҢиҖҢеҪ“ж•°жҚ®дјҒдёҡйқўеҜ№еӨҚжқӮзҡ„еёӮеңәзҺҜеўғпјҢиҙўдә§жқғзҡ„еј•е…Ҙ并йқһе…¶йңҖиҰҒйқўеҜ№зҡ„еҚ•дёҖеӣ зҙ пјҢжҲ–и®ёж— жі•еҪ“然ең°е®ҡд№үжҲҗз®ҖеҚ•еҚҡејҲжЁЎеһӢдёӢвҖңз ”еҸ‘-еӣһжҠҘвҖқзҡ„з»“жһңзҹ©йҳөгҖӮжқғеҲ©зҡ„еҚ жңүеҠҹиғҪжҺЁеҜјеҮәдёҖз§ҚжҺ’д»–еұһжҖ§пјҢдҪҝеҸ–еҫ—иҙўдә§жқғзҡ„дјҒдёҡеҫ—д»Ҙеӣәе®ҡе…¶з»“жһңпјҢд№ҹиҮӘ然еҲ¶йҖ дәҶдёҖз§ҚеҗҲжі•зҡ„еһ„ж–ӯгҖӮжңүеӯҰиҖ…жҢҮеҮәпјҢиҙўдә§жң¬иә«е…·жңүйј“еҠұвҖңе°ҸйӣҶеӣўдё»д№үвҖқзҡ„еҶ…еңЁйҖ»иҫ‘пјҢеҪ“иҙўдә§жҠҠжңәдјҡиҪ¬з§»еҲ°жқғеҲ©жҢҒжңүиҖ…жүӢдёӯд»ҘжҺ§еҲ¶иө„жәҗзҡ„еҗҢж—¶пјҢдәҰжҳҜд»ҘеҮҸе°‘д»–дәәзҡ„жңәдјҡйӣҶеҗҲдёәд»Јд»·гҖӮйӮЈд№Ҳд»ҘзӨҫдјҡж•ҙдҪ“зҰҸеҲ©зҡ„и§Ҷи§’и§Ӯд№ӢпјҢеңЁз«һдәүжң¬дёҚе……еҲҶзҡ„ж•°жҚ®ејҖеҸ‘еёӮеңәеј•е…Ҙиҙўдә§жқғзҡ„жҝҖеҠұжүӢж®өиғҪеӨҹеҸ–еҫ—жҖҺж ·зҡ„иЎҢдёҡе®һж•Ҳпјҹ е…¶дәҢпјҢз•Ңжқғзҡ„еӣ°еўғгҖӮеҰӮжһңдёәж•°жҚ®и®ҫз«ӢдёҖз§ҚжҺ’д»–жҖ§жқғеҲ©пјҢеә”еҪ“дҝқиҜҒжқғеҲ©дҝқжҠӨзҡ„ж Үзҡ„гҖҒиҢғеӣҙзӯүе…·жңүи¶іеӨҹзҡ„жі•еҫӢзЎ®е®ҡжҖ§гҖӮ йҰ–е…ҲпјҢжқғеҲ©е®ўдҪ“зҡ„еҶ…ж¶өе’ҢеӨ–延жңүеҫ…жҳҺзЎ®гҖӮж•°жҚ®гҖҒеӨ§ж•°жҚ®гҖҒжңәеҷЁз”ҹжҲҗж•°жҚ®зӯүйғҪдёҚжҳҜдёҖдёӘзЁіе®ҡзҡ„жҰӮеҝөпјҢжңүеӯҰиҖ…жҸҗеҮәпјҢжҲ‘еӣҪзҺ°иЎҢз«Ӣжі•е’Ңж–Ү件еҜ№ж•°жҚ®еҶ…ж¶өеӨ§иҮҙе°ұжңүдә”з§ҚдёҚеҗҢзҗҶи§ЈгҖӮеҚідҪҝжҳҺзЎ®дәҶж ёеҝғжҰӮеҝөпјҢеҜ№иҫ№з•Ңзҡ„иҫЁиҜҶд№ҹ并йқһжҳ“дәӢгҖӮеӨ§ж•°жҚ®иў«и®Өдёәе…·жңүвҖң4VвҖқзү№еҫҒпјҢе…¶дёӯд№ӢдёҖжҳҜвҖңVelocityвҖқпјҲйҖҹеәҰпјүгҖӮе·Ҙдёҡж•°жҚ®з”ҹжҲҗеӨ§еӨҡе®һж—¶еҸ‘з”ҹпјҢж•°жҚ®еҸҜиғҪжҢҒз»ӯдёҚж–ӯең°й«ҳйҖҹжӣҙж–°пјҢе®ўдҪ“иҢғеӣҙ并дёҚзЁіе®ҡпјҢеҫҲйҡҫз§°еҫ—дёҠе…·жңүдёҖдёӘзЁіе®ҡеҸҜиҫЁзҡ„иҫ№з•Ңе’ҢиҢғеӣҙгҖӮжқғеҲ©з©¶з«ҹеә”дҝқжҠӨе“Әдәӣж•°жҚ®пјҹжңәеҷЁеңЁз»ҷе®ҡж—¶й—ҙиҢғеӣҙеҶ…з”ҹжҲҗзҡ„жүҖжңүж•°жҚ®пјҲдҫӢеҰӮпјҢдёҖе°Ҹж—¶гҖҒдёҖеҲҶй’ҹжҲ–дёҖз§’пјүпјҢжҠ‘жҲ–з”ұзү№е®ҡжңәеҷЁдә§з”ҹзҡ„жүҖжңүж•°жҚ®пјҹ欧зӣҹзҡ„дёҖйЎ№з ”з©¶и®ӨдёәпјҢ欧зӣҹзҡ„ж•°жҚ®еә“зү№ж®Ҡжқғд№ҹйқўдёҙзұ»дјје®ўдҪ“йҡҫиҫЁзҡ„й—®йўҳпјҢеҚівҖңж•°жҚ®еә“дёӯзҡ„ж•°жҚ®дёҚж–ӯжӣҙж–°пјҢеҸ—дҝқжҠӨж•°жҚ®еә“зҡ„зЎ®еҲҮжһ„жҲҗжҳҜд»Җд№ҲвҖқпјҹиҖҢеңЁж•°жҚ®еә“зү№ж®ҠжқғдёӯпјҢвҖңж•°жҚ®еә“вҖқзҡ„е®ҡд№үе’ҢеӨ§йҮҸжҠ•иө„зҡ„иҰҒжұӮиҮіе°‘еңЁе®ўдҪ“е’ҢжқғеҲ©иҢғеӣҙж–№йқўзЎ®з«ӢдәҶдёҖз§ҚзЁіе®ҡжҖ§гҖӮеҗҢж—¶пјҢжғіиҰҒи®ҫз«Ӣзҡ„ж•°жҚ®жқғе®һйҷ…дёҠе°ұжӣҙйҡҫд»Ҙе»әз«ӢдёҖз§ҚзЁіе®ҡжҖ§гҖӮиҝҷж ·дёҖз§ҚжөҒеҠЁжҖ§еӨ§гҖҒдёҚжҳ“иҜҶеҲ«е№¶дёҚж–ӯеҸ‘еұ•зҡ„еҜ№иұЎйҡҫд»Ҙз¬ҰеҗҲзҹҘиҜҶдә§жқғзҡ„е®ўдҪ“йңҖжұӮгҖӮ е…¶ж¬ЎпјҢеңЁжқғеҲ©дё»дҪ“зҡ„зЎ®и®Өж–№йқўпјҢжүҖжңүжқғй—®йўҳйҡҫд»ҘжҳҺжҷ°гҖӮз”ҹжҲҗе’ҢеӨ„зҗҶж•°жҚ®зҡ„д»·еҖјй“ҫдёҠпјҢдё»дҪ“еӨҚжқӮгҖҒеҲ©зӣҠжқӮзі…пјҢдёҠжёёе’ҢдёӢжёёеӨҡдёӘиЎҢдёәдё»дҪ“жҲ–еҲ©зӣҠзӣёе…іиҖ…йғҪеҸҜиғҪиҰҒжұӮеҜ№ж•°жҚ®жӢҘжңүжүҖжңүжқғпјҢеҗҢдёҖдё»дҪ“д№ҹеҸҜиғҪжү®жј”зқҖеӨҡдёӘи§’иүІгҖӮеҰӮжһңиҝӣиЎҢиөӢжқғпјҢж•°жҚ®з”ҹдә§иҖ…гҖҒ收йӣҶиҖ…гҖҒеҠ е·ҘиҖ…зҡ„еҲ©зӣҠйҡҫд»ҘеҲҶй…ҚпјҢеҚійҡҫд»ҘеҲ’е®ҡдёҖдёӘзӢ¬еҚ жқғеҲ©зҡ„дё»дҪ“иҢғеӣҙгҖӮ жңҖеҗҺпјҢеңЁжқғеҲ©иҢғеӣҙзҡ„з•Ңе®ҡж–№йқўпјҢз”ұдәҺж•°жҚ®еӨ„зҗҶеҲ©зӣҠй“ҫжқЎеӨҚжқӮпјҢеңЁз•Ңе®ҡжқғеҲ©иҢғеӣҙе’Ңи®ҫе®ҡжқғеҲ©дҫӢеӨ–жҲ–йҷҗеҲ¶ж—¶пјҢеҗ„ж–№еҲ©зӣҠе№іиЎЎзҡ„иҖғйҮҸд№ҹиҫғдёәеӨҚжқӮгҖӮеҫ·еӣҪ马е…Ӣж–ҜВ·жҷ®жң—е…ӢеҲӣж–°дёҺз«һдәүз ”з©¶жүҖ2016е№ҙзҡ„з ”з©¶жҠҘе‘Ҡи®ӨдёәпјҢйҡҫд»Ҙе№іиЎЎеҸ—жӯӨзұ»жқғеҲ©еҪұе“Қзҡ„еҗ„ж–№еҲ©зӣҠпјҢз•Ңе®ҡдҝқжҠӨиҢғеӣҙгҖӮеҰӮжһңиҙўдә§жқғйҮҚеҸ гҖҒжқғеҲ©дәәж•°йҮҸиҝҮеӨҡпјҢеҫҲеҸҜиғҪеҸ‘з”ҹж— жі•жңүж•ҲдҪҝз”Ёиҙўдә§зҡ„вҖңеҸҚе…¬ең°жӮІеү§вҖқгҖӮиҖҢеңЁж•°жҚ®й—®йўҳдёҠпјҢвҖңеҸҚе…¬ең°жӮІеү§вҖқзҡ„зҗҶи®әдёҚд»…еҗҢж ·йҖӮз”ЁпјҢиҖҢдё”еҸҜиғҪиЎЁзҺ°еҫ—жӣҙдёәзӘҒеҮәгҖӮеҪ“дёҚеҗҢжқҘжәҗгҖҒеҹәдәҺдёҚеҗҢи®ёеҸҜжқЎд»¶дёӢзҡ„ж•°жҚ®иў«ж··еҗҲпјҢ并еңЁж•°жҚ®д»·еҖјй“ҫзҡ„жҹҗз«Ҝиў«еҶҚж¬ЎеҠ е·ҘгҖҒеӨ„зҗҶпјҢз”ҹжҲҗж–°ж•°жҚ®пјҢеҸҜиғҪдә§з”ҹдёҖеј йҡҫд»ҘеҺҳжё…зҡ„иҙўдә§е…ізі»зә зј зҪ‘з»ңгҖӮжңүеӯҰиҖ…жҸҗйҶ’пјҢж•°жҚ®дёҠеӨҚжқӮеҲ©зӣҠе…ізі»ж„Ҹе‘ізқҖжі•еҫӢдёҠзҡ„дёҚзЎ®е®ҡжҖ§йҡҫд»Ҙе®Ңе…Ёе…ӢжңҚпјҢиҖҢиҝҷвҖңдёҚеҸҜйҒҝе…Қең°е°ҶеҜјиҮҙж•°жҚ®зҡ„дҪҝз”ЁдёҚи¶івҖқгҖӮеҰӮжһңдёҚиҝӣиЎҢиөӢжқғпјҢйҖҡиҝҮеҪ“дәӢж–№зҡ„еҗҲеҗҢеӨ„зҗҶж•°жҚ®д№Ӣй—ҙзҡ„е…ізі»пјҢеҸҚиҖҢеңЁеӨҡж•°жғ…еҶөдёӢеҸҜд»ҘйҷҚдҪҺжғ…еҶөзҡ„еӨҚжқӮжҖ§пјҢ并дҪҝж•°жҚ®иҺ·еҸ–е’Ңдј иҫ“жӣҙдёәе®№жҳ“гҖӮ е…¶дёүпјҢдҪ“зі»еҶІзӘҒзҡ„йЈҺйҷ©гҖӮйҷӨдәҶжқғеҲ©жң¬иә«зҡ„з•Ңе®ҡе’Ңжһ„йҖ й—®йўҳпјҢж–°еһӢвҖңж•°жҚ®дә§жқғвҖқе’ҢзҺ°жңүзҹҘиҜҶдә§жқғдҪ“зі»зҡ„еҶІзӘҒй—®йўҳдәҰдёҚе®№еӣһйҒҝгҖӮ йҰ–иҰҒйқўеҜ№зҡ„жҳҜжқғеҲ©йҮҚеҸ й—®йўҳпјҢеҰӮжһңдёҖйғЁеҲҶж•°жҚ®жң¬иә«иў«иөӢдәҲиҙўдә§жқғпјҢеңЁеҗҢдёҖе®ўдҪ“дёҠеҸҜиғҪеӯҳеңЁвҖңеӨҡдёӘзӣёдә’еҶІзӘҒзҡ„жүҖжңүжқғдё»еј вҖқгҖӮдҫӢеҰӮпјҢдҪҝз”Ёж•°з ҒзӣёжңәжӢҚж‘„зҡ„иғ¶зүҮдёҚд»…еҸҜд»ҘдҪңдёәеҸ—зүҲжқғдҝқжҠӨзҡ„дҪңе“ҒпјҢиҖҢдё”жңүиө„ж јдҪңдёәеҸ—вҖңж•°жҚ®еҲ¶дҪңдәәжқғеҲ©вҖқзәҰжқҹзҡ„жңәеҷЁз”ҹжҲҗпјҲдј ж„ҹеҷЁпјүж•°жҚ®пјӣз”өеҪұзҡ„еҲӣдҪңиҖ…еҸҜд»Ҙдё»еј иҮӘе·ұжҳҜз”өеҪұдҪңе“Ғдёӯзҡ„дҪңиҖ…пјҢдҪҶзӣёжңәзҡ„жүҖжңүиҖ…жҲ–ж“ҚдҪңе‘ҳеҸҜиғҪдјҡеңЁз…§зүҮж•°жҚ®дёӯиҰҒжұӮвҖңж•°жҚ®дә§жқғвҖқгҖӮеҗҢж ·пјҢйҮ‘иһҚж•°жҚ®еә“дёӯзҡ„иӮЎзҘЁеёӮеңәжҖ»ж•°жҚ®е°ҶеҸ—еҲ°ж•°жҚ®еә“жқғе’ҢвҖңж•°жҚ®з”ҹдә§иҖ…зҡ„жқғеҲ©вҖқзҡ„дҝқжҠӨпјҢеӣ дёәж•°жҚ®з”ұи®Ўз®—жңәеҢ–зҡ„иҜҒеҲёдәӨжҳ“жүҖиҮӘеҠЁи®°еҪ•гҖҒз”ҹжҲҗгҖӮж•°жҚ®еә“еҲ¶дҪңдәәеҸҜиғҪдјҡйқўдёҙиҜҒеҲёдәӨжҳ“жүҖжҲ–дәӨжҳ“жүҖи®Ўз®—жңҚеҠЎе…¬еҸёзҡ„вҖңж•°жҚ®дә§жқғвҖқдё»еј гҖӮжқғеҲ©зҡ„йҮҚеҸ дәҰдјҡеҜјиҮҙжқғеҲ©еҶІзӘҒгҖӮдҫӢеҰӮпјҢж–°зҡ„ж•°жҚ®жқғеҸҜиғҪе®һзҺ°еҜ№жҠ—ж•°еӯ—еҢ–зүҲжқғдҪңе“Ғзҡ„д»»дҪ•ж•°еӯ—еӨҚеҲ¶гҖӮеҗҢж—¶пјҢзҹҘиҜҶдә§жқғдҪ“зі»еҶ…йғЁжңүдёҖеҘ—еҲ©зӣҠе№іиЎЎжңәеҲ¶пјҢжқғеҲ©д№ҹеҜ№еә”иҜёеӨҡдҫӢеӨ–е’ҢйҷҗеҲ¶гҖӮеҰӮжһңжһ„йҖ еҮәдёҖз§Қж•°жҚ®зҹҘиҜҶдә§жқғпјҢеҝ…然иҰҒеј•е…Ҙе®Ңе–„зҡ„жқғеҲ©дҫӢеӨ–е’ҢйҷҗеҲ¶и§„еҲҷгҖӮжңүеӯҰиҖ…и®ӨдёәпјҢж•°жҚ®жқғиҮіе°‘еә”еҪ“иғҪеӨҹвҖңеӨҚеҲ¶вҖқзҹҘиҜҶдә§жқғзҡ„жүҖжңүдҫӢеӨ–规еҲҷпјҢеҗҰеҲҷе°ҶеүҠејұеҹәжң¬з”ЁжҲ·иҮӘз”ұгҖӮеңЁж•°жҚ®жҢ–жҺҳж–№йқўпјҢиҝҷз§ҚеұҖйҷҗдҪ“зҺ°еҫ—е°ӨдёәжҳҺжҳҫгҖӮ жӯӨеӨ–пјҢжңүеӯҰиҖ…жҸҗеҮәпјҢеҚідҪҝе°ҶжүҖжңүеҸҜиғҪеҸ—дј з»ҹзҹҘиҜҶдә§жқғеҲ¶еәҰдҝқжҠӨзҡ„ж•°жҚ®жҳҺзЎ®жҺ’йҷӨеңЁж–°ж•°жҚ®жқғдҝқжҠӨе®ўдҪ“д№ӢеӨ–пјҢд»ҘйҒҝе…ҚжқғеҲ©йҮҚеҸ пјҢд»Қ然дјҡеҜ№зҺ°жңүзҡ„зҹҘиҜҶдә§жқғеҲ¶еәҰйҖ жҲҗвҖңи…җиҡҖжҖ§вҖқзҡ„еҪұе“ҚгҖӮдҫӢеҰӮпјҢ欧зӣҹи®ҫз«Ӣж•°жҚ®еә“зү№ж®ҠжқғеҲ©жҳҜдёәйј“еҠұд»ҺзҺ°жңүж•°жҚ®е’Ңе…¶д»–жқҗж–ҷдёӯе»әз«Ӣж•°жҚ®еә“зҡ„жҠ•иө„гҖӮеҰӮжһңж–°и®ҫзҡ„ж•°жҚ®жқғиғҪеӨҹдҪҝдҪңдёәе·ҘдёҡвҖңеүҜдә§е“ҒвҖқзҡ„жңәеҷЁз”ҹжҲҗж•°жҚ®пјҢиҺ·еҫ—дёҖз§Қй—Ёж§ӣиҫғдҪҺзҡ„жқғеҲ©пјҢжҠ•иө„ж•°жҚ®еә“зҡ„еҠЁжңәжҳҫ然дјҡеҸ—еҲ°еүҠејұгҖӮжӯӨеӨ–пјҢж— и®әжҳҜеҹәдәҺеҠҹеҲ©дё»д№үиҝҳжҳҜиҮӘ然法зҗҶи®әпјҢзҹҘиҜҶдә§жқғеҲ¶еәҰзҡ„дёҖиҲ¬еҺҹеҲҷжҳҜдјҳе…ҲдҝқжҠӨеҲӣйҖ дёҺеҲӣж–°гҖӮеҰӮжһңдё»иҰҒеҮәдәҺдҝқжҠӨз»ҸжөҺиө„дә§зҡ„еҠЁжңәжқҘеҲӣи®ҫзҹҘиҜҶдә§жқғпјҢйӮЈд№ҲеҸҜиғҪеј•иө·еҜ№зҹҘиҜҶдә§жқғеҗҲжі•жҖ§зҡ„дәүи®®гҖӮ 3.и®ҫз«Ӣж•°жҚ®жқғзҡ„иҜ„дј°гҖӮеӨ§ж•°жҚ®еҖјеҫ—жңҹеҫ…зҡ„жңӘжқҘеә”еҪ“жҳҜж•°жҚ®иө„жәҗзҡ„ејҖеҸ‘жӣҙиҮӘз”ұгҖҒеҲ©з”Ёжӣҙе……еҲҶгҖӮеј•е…ҘдёҖз§Қж–°еһӢзҡ„вҖңж•°жҚ®жқғвҖқд»ҘжҺ§еҲ¶жңӘз»ҸжҺҲжқғи®ҝй—®ж•°жҚ®зҡ„иЎҢдёәпјҢдёҺиҝҷз§Қзӣ®ж Үзӣёе®ңжҲ–зӣёжӮ–пјҹжҲ–и®ёиҮіе°‘еә”е…·дҪ“жқғиЎЎд»ҘдёӢеӣ зҙ гҖӮ е…¶дёҖпјҢжқғеҲ©еј•е…Ҙзҡ„еҠЁжңәе’Ңеҝ…иҰҒжҖ§ж–№йқўпјҢеә”иҖғеҜҹж•°жҚ®йўҶеҹҹжҳҜеҗҰеӯҳеңЁжҝҖеҠұдёҚи¶іпјҢеҢ…жӢ¬ж•°жҚ®з”ҹдә§е’Ңе…¬ејҖзҡ„жҝҖеҠұгҖӮиҝҷеҸҜиғҪдё»иҰҒеҸ–еҶідәҺе®һи·өдёӯе•Ҷдёҡз§ҳеҜҶдҝқжҠӨгҖҒеҗҲеҗҢе’ҢжҠҖжңҜжҺӘж–Ҫд№ғиҮідәӨжҳ“жғҜдҫӢзӯүжүӢж®өпјҢдёәж•°жҚ®жҺ§еҲ¶иҖ…жүҖжҸҗдҫӣзҡ„дәӢе®һдёҠзҡ„жҺ’д»–жҖ§дҝқжҠӨж•ҲжһңжҳҜеҗҰе……еҲҶпјҢжҳҜеҗҰзЎ®е®һж— еҠӣжҺ§еҲ¶еҲ©зӣҠиҖҢдә§з”ҹж•°жҚ®дҝқеҜҶзҡ„еҖҫеҗ‘гҖӮеҜ№вҖңе……еҲҶвҖқзҡ„зҗҶи§ЈпјҢеә”еҪ“д»Һдә§дёҡеҸ‘еұ•е’ҢзӨҫдјҡжҖ»дҪ“收зӣҠз»ҙеәҰз»јеҗҲиҖғйҮҸпјҢдёҚиғҪд»…д»…д»Һж•°жҚ®жҺ§еҲ¶иҖ…зҡ„з«ӢеңәеҮәеҸ‘пјҢиҰҒжұӮ规йҒҝжүҖжңүжңӘз»ҸжҺ§еҲ¶иҖ…жҺҲжқғзҡ„ж•°жҚ®и®ҝй—®иЎҢдёәгҖӮе…¶дәҢпјҢиҙўдә§жқғзҡ„дҪңз”ЁжңәзҗҶж–№йқўпјҢеҜ№дәҺж•°жҚ®иҝҷж ·дёҖз§Қе…·жңүиҜёеӨҡзӢ¬зү№жҖ§зҡ„з”ҹдә§иҰҒзҙ пјҢйңҖиҰҒзҗҶжҖ§еҲҶжһҗиҙўдә§жқғзҡ„еӯҳеңЁиғҪеҗҰиҫғеҘҪең°иө·еҲ°жҳҺзЎ®еҲ©зӣҠеҪ’еұһзҡ„дҪңз”ЁпјӣжҳҜеҗҰеҫ—д»ҘзЁіе®ҡең°з•ҢеҲҶеҲ©зӣҠпјҢж¶Ҳи§Јж•°жҚ®дәӨжҳ“иҖ…еҜ№еҲ©зӣҠеҪ’еұһдёҚзЎ®е®ҡзҡ„йЎҫиҷ‘пјҢиҝҳжҳҜеңЁж–°ж—§жқғеҲ©гҖҒеӨҡж–№дё»дҪ“зҡ„жқӮзі…дёӢжңүдҪҝиҙўдә§е…ізі»жӣҙдёәеӨҚжқӮд№Ӣиҷһпјҹе…¶дёүпјҢз«Ӣжі•жҠҖжңҜж–№йқўпјҢеә”е®Ўи§ҶиғҪеҗҰй…ҚзҪ®еҮәдёҖз§ҚиҫғдёәзҗҶжғізҡ„жқғеҲ©жһ„йҖ пјҢзЎ®дҝқж–°и®ҫз«Ӣзҡ„жқғеҲ©дёҺеҺҹжңүзҹҘиҜҶдә§жқғжі•еҫӢ秩еәҸеҚҸи°ғиһҚеҗҲпјҢйҒҝе…Қдә§з”ҹиҝҮеӨҡзҡ„еҸёжі•жҲҗжң¬гҖӮ еҪ“еӨ§ж•°жҚ®еӨ„зҗҶжҠҖжңҜиў«жҺЁе№ҝеә”з”Ёд№ӢеҲқгҖҒж•°жҚ®и•ҙи—Ҹзҡ„е·ЁеӨ§з»ҸжөҺд»·еҖјеҲқи§Ғз«ҜеҖӘд№Ӣж—¶пјҢж•°жҚ®дҝқжҠӨд»·еҖје’ҢжҝҖеҠұеҠЁеӣ иў«й«ҳеәҰйҮҚи§Ҷе’ҢеҸҚеӨҚејәи°ғпјӣиҖҢеҪ“ж•°жҚ®з»ҸжөҺдёҚж–ӯеҪ°жҳҫеҮәжөҒеҠЁејҖж”ҫзҡ„еҶ…еңЁйҖ»иҫ‘е’Ңж•°жҚ®иҺ·еҸ–еҲ©з”Ёзҡ„е®һи·өйңҖжұӮж—¶пјҢеӯҰз•ҢеҜ№дәҺж•°жҚ®иөӢжқғдҝқжҠӨзҡ„еұҖйҷҗжҖ§и®ӨиҜҶйҖҗжёҗж·ұе…ҘпјҢж•°жҚ®жІ»зҗҶзҡ„зҗҶи®әи§ҶйҮҺд№ҹзӣёеә”и°ғж•ҙгҖӮзӣёиҫғдәҺеӣәеҢ–зҡ„жқғеҲ©дҝқжҠӨжҖқи·ҜпјҢжӣҙеҠ з»јеҗҲејҖж”ҫзҒөжҙ»зҡ„ж•°жҚ®жІ»зҗҶи§ҶйҮҺжҲ–и®ёжӣҙз¬ҰеҗҲж•°жҚ®з»ҸжөҺзҡ„зҗҶи®әйҖ»иҫ‘е’Ңе®һи·өйңҖжұӮгҖӮ еӨ„зҗҶж•°жҚ®иҺ·еҸ–й—®йўҳзҡ„йқһи®ҫжқғиҝӣи·ҜгҖӮзӣёиҫғдәҺйҖҡиҝҮе»әз«Ӣж•°жҚ®дә§жқғд»Ҙжңҹдҝғиҝӣж•°жҚ®зҡ„е•ҶдёҡжөҒиҪ¬еҲ©з”ЁпјҢдёҚеҗҢеӯҰиҖ…жҸҗеҮәдәҶдҝғиҝӣж•°жҚ®иҺ·еҸ–е’Ңж•°жҚ®жҢ–жҺҳзҡ„дёҚеҗҢдё»еј гҖӮ 1.ејәеҲ¶ж•°жҚ®е…ұдә«гҖӮе»әз«Ӣе·Ҙе•Ҷдёҡж•°жҚ®зҡ„е№ҝжіӣж•°жҚ®ејәеҲ¶е…ұдә«жңәеҲ¶пјҢжҳҜеҸҚеҜ№иөӢдәҲж•°жҚ®жҺ’д»–жқғгҖҒеқҡжҢҒйҖҡиҝҮеҲ¶е®ҡзӣҙжҺҘзҡ„ж•°жҚ®иҺ·еҸ–规еҲҷдҝғиҝӣж•°жҚ®е…ұдә«дёҖжҙҫзҡ„йІңжҳҺдё»еј гҖӮе…ёеһӢеҰӮгҖҠеӨ§ж•°жҚ®ж—¶д»ЈгҖӢзҡ„дҪңиҖ…з»ҙе…ӢжүҳВ·иҝҲе°”-иҲҚжҒ©дјҜж је’Ңжүҳ马ж–ҜВ·е…°ж јпјҢ他们жҸҗеҮәпјҢеӨ§ж•°жҚ®з»ҷдёҖдәӣе…¬еҸёеёҰжқҘдәҶдёҚе…¬е№ізҡ„з«һдәүдјҳеҠҝпјҢж”ҝеәңеә”ејәеҲ¶иҰҒжұӮеӨ§ж•°жҚ®е…¬еҸёвҖңе°Ҷе®ғ们收йӣҶзҡ„еҢҝеҗҚж•°жҚ®зүҮж®өдёҺе…¶д»–е…¬еҸёе…ұдә«вҖқгҖӮ йҷӨдәҶд»Һж•°жҚ®жҺ§еҲ¶иҖ…з«Ҝзҡ„д№үеҠЎеұӮзӣҙжҺҘжҸҗеҮәж•°жҚ®ејәеҲ¶е…ұдә«жҰӮеҝөпјҢд№ҹжңүеӯҰиҖ…д»Һж•°жҚ®дҪҝз”ЁиҖ…жқғеҲ©еұӮжҸҗеҮәвҖңж•°жҚ®и®ҝй—®иҖ…жқғвҖқжҰӮеҝөпјҢиҰҒжұӮж•°жҚ®дҪҝз”ЁиҖ…еҜ№дәҺеҺҹе§ӢйқһдёӘдәәж•°жҚ®жңүвҖңж•°жҚ®иҺ·еҸ–дёҚеҸ—йҷҗеҲ¶вҖқзҡ„жқғеҲ©пјҢдәӢе®һдёҠд№ҹжҳҜдёҖз§Қж•°жҚ®йқһиҮӘж„ҝе…ұдә«и§„еҲҷзҡ„жһ„е»әжЁЎејҸгҖӮ е…¶дёҖпјҢејәеҲ¶е…ұдә«зҡ„жӯЈеҪ“жҖ§еҹәзЎҖпјҡеҹәдәҺж•°жҚ®зҡ„е…¬е…ұеұһжҖ§гҖӮиҝҷз§Қдё»еј зҡ„зҗҶи®әж ёеҝғжҳҜе°Ҷж•°жҚ®пјҲе°Өе…¶жҳҜеҺҹе§ӢйқһдёӘдәәж•°жҚ®пјүи§Ҷдёәе…¬жңүйўҶеҹҹзҡ„дёҖйғЁеҲҶпјҢдё»еј жі•еҫӢеә”еҪ“зЎ®е®ҡвҖңж•°жҚ®и®ҝй—®дёҚеҸ—йҷҗеҲ¶вҖқзҡ„规еҲҷпјҢж–ҪеҠ зӣ‘з®ЎжҺӘж–ҪпјҢдҝғиҝӣеҒ¶з„¶зҡ„ж•°жҚ®жҺ§еҲ¶иҖ…зҡ„ж•°жҚ®е…¬ејҖгҖӮ дёҖж–№йқўпјҢж•°жҚ®иў«и®Өдёәе…·жңүе…¬е…ұзү©е“ҒеұһжҖ§пјҢе…Ғи®ёйқһз«һдәүжҖ§ж¶Ҳиҙ№гҖӮдёҖдёӘеҸӮдёҺиҖ…е…ұдә«е’ҢйҮҚеӨҚдҪҝз”Ёж•°жҚ®дёҚдјҡйҷҚдҪҺиҜҘж•°жҚ®еҜ№е…¶д»–еҸӮдёҺиҖ…зҡ„д»·еҖјпјҢ并且дјҡдә§з”ҹжҳҫи‘—зҡ„жәўеҮәж•Ҳеә”гҖӮеӣ жӯӨпјҢиҰҒжұӮдјҒдёҡе…ұдә«ж•°жҚ®дёҚзӯүеҗҢдәҺеҜ№дјҒдёҡж•°жҚ®зҡ„еҫҒ收жҲ–еүҘеӨәпјҢдјҒдёҡиҝӣиЎҢж•°жҚ®е…ұдә«йҖҡ常并дёҚйңҖиҙҹжӢ…д»»дҪ•зӣҙжҺҘжҲҗжң¬гҖӮеҸҰдёҖж–№йқўпјҢе·Ҙдёҡ4.0ж—¶д»ЈпјҢзј–з ҒдҝЎжҒҜзҡ„жҲҗжң¬иҫғдҪҺпјҢж•°жҚ®з”ҹдә§йҖҡеёёжҳҜж ёеҝғдёҡеҠЎжҙ»еҠЁзҡ„вҖңеүҜдә§е“ҒвҖқгҖӮж•°еӯ—еҢ–еёӮеңәеҸӮдёҺиҖ…зҡ„з«һдәүдјҳеҠҝдёҚд»…д»…жҳҜж•°жҚ®жң¬иә«пјҢжӣҙе…ій”®еңЁдәҺж•°жҚ®зҡ„еҲҶжһҗеӨ„зҗҶиғҪеҠӣгҖӮеҰӮжһңж•°жҚ®еӨ„дәҺж•°жҚ®еҲҶжһҗеӨ„зҗҶиғҪеҠӣдёҚи¶ізҡ„дё»дҪ“жҺ§еҲ¶дёӢзјәд№Ҹе…ұдә«пјҢеҸҜиғҪйҖ жҲҗж•°жҚ®еҲ©з”Ёж•ҲзҺҮзҡ„дёҘйҮҚдёҚи¶ігҖҒж•°жҚ®д»·еҖјйҡҫд»ҘеҸ‘жҢҘпјӣиҖҢеҰӮжһңжӣҙеӨҡз«һдәүдё»дҪ“иҺ·еҫ—дәҶжӣҙдёәе…¬е№іејҖж”ҫзҡ„ж•°жҚ®иҺ·еҸ–жңәдјҡпјҢеёӮеңәз«һдәүдјҡжҝҖеҠұдјҒдёҡдёҚж–ӯеҸ‘еұ•жӣҙдёәжҷәиғҪзҡ„з®—жі•е’ҢеҲҶжһҗжүӢж®өпјҢжңүеҲ©дәҺдҝғиҝӣеҲӣж–°е’ҢжҖ»дҪ“ж•°жҚ®еҲ©з”ЁиғҪеҠӣзҡ„жҸҗеҚҮпјҢдҪҝзӨҫдјҡжҖ»дҪ“д»Һж•°жҚ®еҲ©з”ЁдёӯиҺ·зӣҠгҖӮ е…¶дәҢпјҢејәеҲ¶е…ұдә«зҡ„еҝ…иҰҒжҖ§пјҡе®һи·өдёӯж•°жҚ®е…ұдә«йҳҷеҰӮгҖӮеңЁзјәд№Ҹж”ҝеәңе№Ійў„зҡ„жғ…еҶөдёӢпјҢе®һи·өдёӯиҮӘж„ҝзҡ„ж•°жҚ®е…ұдә«йқһеёёеҢ®д№ҸгҖӮеҫ·еӣҪ马е…Ӣж–ҜВ·жҷ®жң—е…ӢеҲӣж–°дёҺз«һдәүз ”з©¶жүҖзҡ„з ”з©¶иҖ…жӣҫеҹәдәҺ欧жҙІзҡ„жғ…еҶөеҲҶжһҗеёӮеңәдё»дҪ“иҮӘеҸ‘зҡ„ж•°жҚ®иҺ·еҸ–е’ҢжҺ’д»–дҪҝз”ЁиЎҢдёәпјҢжҢҮеҮәе№іеҸ°з»ҸжөҺжЁЎејҸжҳҜвҖңж•°жҚ®й©ұеҠЁзҡ„еёӮеңәвҖқпјҢдёҖж—Ұж•°жҚ®и§„жЁЎе’ҢиҢғеӣҙз§ҜзҙҜиҮівҖңдёҙз•ҢеҖјвҖқпјҢе°ұдјҡдә§з”ҹжҳҫи‘—зҡ„зҪ‘з»ңж•Ҳеә”пјҢе‘ҲзҺ°еҮәвҖңејәиҖ…ж„ҲејәвҖқзҡ„ж•ҲжһңгҖӮеҚ жҚ®еёӮеңәдјҳеҠҝең°дҪҚзҡ„еҸӮдёҺиҖ…еҸҜд»ҘйҖҡиҝҮеүҠеҮҸеҗ‘з«һдәүеҜ№жүӢжҸҗдҫӣз”ЁжҲ·ж•°жҚ®зҡ„ж–№ејҸпјҢжңүж•ҲжҠ‘еҲ¶з«һдәүеҜ№жүӢйқ иҝ‘з«һдәүдјҳеҠҝзҡ„вҖңдёҙз•ҢеҖјвҖқгҖӮеӣ жӯӨпјҢдёҚйҡҫзҗҶ解收йӣҶжҲ–жҢҒжңүж•°жҚ®зҡ„дјҒдёҡйҖҡеёёжӣҙж„ҝж„Ҹе°Ҷж•°жҚ®зҡ„дҪҝз”ЁжҺ§еҲ¶дәҺдјҒдёҡеҶ…йғЁпјҢдёҚж„ҝдёҺе…¶д»–еёӮеңәеҸӮдёҺиҖ…гҖҒе°Өе…¶жҳҜз«һдәүеҜ№жүӢе…ұдә«ж•°жҚ®иө„жәҗгҖӮиҖҢеңЁж•°жҚ®дәӨжҳ“зҡ„еңәжҷҜдёӢпјҢж•°жҚ®жҺ§еҲ¶дё»дҪ“йҖҡеёёжӢҘжңүжӣҙејәзҡ„и®®д»·иғҪеҠӣпјҢж•°жҚ®дҪҝз”ЁиҖ…йңҖиҰҒд»ҳеҮәиҫғй«ҳзҡ„дәӨжҳ“жҲҗжң¬пјҢж•°жҚ®и®ҝй—®е’ҢиҺ·еҸ–еҸҜиғҪеҚҒеҲҶеӣ°йҡҫдё”жҳӮиҙөгҖӮ иҖҢе®һи·өдёӯе·Із»ҸеӯҳеңЁзҡ„вҖңејәеҲ¶ж•°жҚ®е…ұдә«вҖқдё»иҰҒж №жҚ®еҸҚеһ„ж–ӯзЁӢеәҸеҗҜеҠЁпјҢдҪҶеҗҜеҠЁй—Ёж§ӣиҫғй«ҳгҖҒеңәжҷҜиҝҮдәҺеұҖйҷҗгҖӮеңЁж¶үеҸҠдјҒдёҡеҗҲ并зҡ„еҸҚеһ„ж–ӯе®ЎжҹҘдёӯпјҢеёӮеңәз«һдәүжңәжһ„еҸҜд»ҘиҰҒжұӮеҗҲ并еҗҺзҡ„е®һдҪ“д»ҘеёӮеңәд»·ж јеҗ‘з«һдәүеҜ№жүӢеҮәе”®ж•°жҚ®гҖӮдҪҶиҝҷз§Қж•°жҚ®е…ұдә«зҡ„д№үеҠЎд»…еңЁеӯҳеңЁе№¶иҙӯе’Ңзү№е®ҡеҸҚз«һдәүиЎҢдёәзҡ„жғ…еҶөдёӢеҗҜеҠЁпјҢеҜ№жӯӨеӯҰз•ҢдёҚд№Ҹжү©еӨ§жӯӨз§Қе…ұдә«д№үеҠЎзҡ„е‘јеЈ°гҖӮжӯӨеӨ–пјҢеҸҚеһ„ж–ӯжі•дёӯзҡ„вҖңеҝ…иҰҒи®ҫж–ҪзҗҶи®әвҖқиҰҒжұӮдёҖдёӘеһ„ж–ӯеҚ жңүвҖңеҹәзЎҖи®ҫж–ҪвҖқзҡ„з»ҸиҗҘиҖ…дёҺе…¶д»–з«һдәүиҖ…е…ұдә«еҹәзЎҖи®ҫж–ҪгҖӮ然иҖҢпјҢж•°жҚ®иғҪеҗҰжһ„жҲҗеҝ…иҰҒи®ҫж–Ҫд»ҚеӯҳеңЁдёҚе°‘дәүи®®пјҢжңүеӯҰиҖ…и®ӨдёәвҖңеҸҜиҺ·еҸ–зҡ„ж•°жҚ®ж°ёиҝңдёҚжҳҜеҝ…дёҚеҸҜе°‘зҡ„вҖқпјӣжңүеӯҰиҖ…жҸҗеҮәж•°жҚ®зҡ„еҸҜжӣҝд»ЈжҖ§йҖҡеёёйҡҫд»ҘиҜ„дј°гҖӮ жҚ®жӯӨпјҢдҫқйқ еёӮеңәдё»дҪ“иҮӘдё»иҮӘж„ҝзҡ„ж•°жҚ®иҺ·еҸ–е’Ңе…ұдә«иҝңиҝңдёҚи¶іпјҢзҺ°жңү规еҲҷиғҪеӨҹе®һзҺ°зҡ„ејәеҲ¶е…ұдә«жһҒдёәжңүйҷҗпјҢеә”еҪ“еј•е…ҘжҳҺзЎ®е…·дҪ“зҡ„ж•°жҚ®е…ұдә«д№үеҠЎпјҢ并зӣ‘зқЈе’Ңдҝқйҡңзӣёе…іејәеҲ¶е…ұдә«и§„еҲҷзҡ„е®һж–ҪгҖӮдёҖж–№йқўпјҢеә”еҪ“е»әз«ӢеҸҜиЎҢзҡ„е…ұдә«д№үеҠЎжЎҶжһ¶пјҢзЎ®е®ҡе…ұдә«д№үеҠЎж¶үеҸҠзҡ„ж•°жҚ®йӣҶеҗҲиҢғеӣҙгҖҒж—¶й—ҙиҢғеӣҙгҖҒи®ёеҸҜжқЎж¬ҫзӯүпјӣеҸҰдёҖж–№йқўпјҢжңүеҝ…иҰҒе»әз«ӢйҖӮеҪ“зҡ„иЎҘеҒҝи®ЎеҲ’пјҢд»ҘеңЁж•°жҚ®жҢҒжңүиҖ…е’Ңи®ҝй—®иҖ…зҡ„еҲ©зӣҠеҶІзӘҒд№Ӣй—ҙеҸ–еҫ—е№іиЎЎгҖӮ е…¶дёүпјҢеҜ№ејәеҲ¶ж•°жҚ®е…ұдә«зҡ„иҜ„д»·гҖӮеҜ№дәҺејәеҲ¶ж•°жҚ®е…ұдә«зҡ„дё»еј пјҢд№ҹеӯҳеңЁдёҖдәӣдёҚе®№еҝҪи§Ҷзҡ„й—®йўҳгҖӮйҰ–е…ҲжҳҜеҹәдәҺжҲҗжң¬зҡ„еҸҜиЎҢжҖ§еҲӨж–ӯгҖӮжңүеӯҰиҖ…ејәи°ғпјҢејәеҲ¶ж•°жҚ®е…ұдә«е°ҶжҳҜдёҖдёӘеӨҚжқӮзҡ„иҝҮзЁӢпјҢдё”е°Ҷз»ҷж”ҝеәңеёҰжқҘз№ҒйҮҚзҡ„зӣ‘з®ЎжҲҗжң¬пјҢиӯ¬еҰӮпјҢзЎ®е®ҡдјҒдёҡжҸҗдҫӣж•°жҚ®зҡ„ж•°йҮҸгҖҒж•°жҚ®зҡ„йҡҸжңәжҖ§дёҺж•°жҚ®иҙЁйҮҸгҖӮд№ҹеҹәдәҺжӯӨпјҢејәеҲ¶е…ұдә«д№үеҠЎжЎҶжһ¶зҡ„еӨҚжқӮжҖ§дёҚе®№иҪ»и§ҶгҖӮжӯӨеӨ–пјҢиғҪеҗҰе°Ҷж•°жҚ®е®Ңе…Ёз•Ңе®ҡдёәе…¬жңүйўҶеҹҹзҡ„дә§зү©пјҹеҚідҪҝе°Ҷе…ұдә«зҡ„д№үеҠЎиҢғеӣҙд»…йҷҗдәҺжңӘз»Ҹж·ұеәҰеӨ„зҗҶзҡ„ж•°жҚ®пјҢжҳҜеҗҰд№ҹжңүиҝҮдәҺжһҒз«Ҝең°еҗҰе®ҡдәҶдјҒдёҡеңЁж•°жҚ®з”ҹдә§гҖҒ收йӣҶгҖҒж•ҙзҗҶзӯүж–№йқўзҡ„еҲ©зӣҠд№Ӣе«ҢпјҹеңЁж•°жҚ®ејәеҲ¶е…ұдә«зҡ„жЎҶжһ¶дёӢпјҢеҰӮдҪ•дҝқиҜҒйӮЈдәӣеҲӣйҖ жҠҖжңҜжқЎд»¶е№¶жҠ•е…Ҙиө„жәҗзҡ„еёӮеңәеҸӮдёҺиҖ…иҺ·еҫ—е…¬е№ізҡ„жҠ•иө„еӣһжҠҘпјҹеҶҚиҖ…пјҢиҝҷз§ҚејәеҲ¶е…¬ејҖд№үеҠЎзҡ„иҢғеӣҙи®ҫе®ҡиғҪеҗҰеӨ„зҗҶеҘҪдёҺе•Ҷдёҡз§ҳеҜҶгҖҒзҹҘиҜҶдә§жқғдҝқжҠӨзӯүд№Ӣй—ҙзҡ„е…ізі»пјҹеҰӮжһңдјҒдёҡиҙҹжңүе№ҝжіӣзҡ„ж•°жҚ®е…ұдә«д№үеҠЎпјҢжңүеҸҜиғҪдә§з”ҹвҖңдҪңдёәе•Ҷдёҡз§ҳеҜҶдҝқжҠӨвҖқзҡ„ж•°жҚ®е’ҢвҖңйңҖиҰҒејәеҲ¶еҗ‘жүҖжңүеёӮеңәдё»дҪ“е…¬ејҖвҖқзҡ„ж•°жҚ®е®һиҙЁе·®ејӮдёҚеӨ§иҖҢжүҖеҸ—еҫ…йҒҮиҝҘејӮзҡ„еұҖйқўгҖӮжңҖеҗҺпјҢејәеҲ¶е…ұдә«еёҰжқҘзҡ„ж•°жҚ®е®үе…Ёе’Ңйҡҗз§Ғй—®йўҳдёҚе®№еҝҪи§ҶгҖӮеҚідҪҝж•°жҚ®иў«еҢҝеҗҚеҢ–еӨ„зҗҶпјҢеҰӮжһңе…¶д»–дјҒдёҡжңүеҗҢдёҖдёӘдәәзҡ„ж•°жҚ®пјҢеҲҷеӯҳеңЁж•°жҚ®иў«еӨҡж¬ЎиҜҶеҲ«зҡ„йЈҺйҷ©гҖӮ з»јдёҠжүҖиҝ°пјҢеңЁиҮӘз”ұз«һдәүзҡ„еёӮеңәдёӯжҺЁиЎҢе…ЁйқўгҖҒе№ҝжіӣзҡ„ж•°жҚ®ејәеҲ¶е…ұдә«д№үеҠЎеҸҜиғҪеҖјеҫ—е®Ўж…ҺиҖғиҷ‘гҖӮдёҖж—Ұе®һж–ҪпјҢеә”жңүдёҖзі»еҲ—жңүе…іиҙЈд»»гҖҒзӣ‘з®ЎгҖҒе®үе…ЁгҖҒжҝҖеҠұзӯүзҡ„й…ҚеҘ—жҖ§жңәеҲ¶дҪңдёәдҝқйҡңгҖӮиҖҢеҜ№йғЁеҲҶж•°жҚ®зҡ„ејәеҲ¶е…¬ејҖиҰҒжұӮеә”жҳҜеҸҜиЎҢзҡ„гҖӮдҫӢеҰӮпјҢеҜ№дәҺж¶үеҸҠе…¬е…ұеҲ©зӣҠжҲ–е…·еӨҮжӣҙејәе…¬е…ұеұһжҖ§зҡ„ж•°жҚ®пјҢеңЁжҳҺзЎ®йҷҗе®ҡиҢғеӣҙгҖҒ规е®ҡжқЎд»¶гҖҒзЎ®е®ҡйўҶеҹҹзҡ„еҹәзЎҖдёҠж–ҪеҠ ж•°жҚ®е…¬ејҖзҡ„д№үеҠЎгҖӮжӯӨеӨ–пјҢйғЁеҲҶж•°жҚ®зҡ„ејәеҲ¶е…ұдә«д№ҹеҸҜд»ҘдҪңдёәдёҺе…¶д»–жІ»зҗҶи·Ҝеҫ„зӣёй…ҚеҗҲзҡ„е№іиЎЎе’ҢжқғеҲ©йҷҗеҲ¶жңәеҲ¶пјҢзұ»дјјдәҺзҹҘиҜҶдә§жқғжі•дёӯвҖңејәеҲ¶и®ёеҸҜвҖқ规еҲҷдәҲд»Ҙйҷ„йҡҸжҖ§еј•е…ҘгҖӮ 2.ж•°жҚ®зҡ„еҗҲеҗҢжІ»зҗҶгҖӮеҪ“жі•еҫӢеңЁж•°жҚ®жқғеұһй—®йўҳе°ҡеӨ„иёҢиәҮеҫҳеҫҠд№Ӣж—¶пјҢж•°жҚ®дәӨжҳ“е’ҢйҖҡиҝҮеҗҲеҗҢе®үжҺ’еҲҶй…Қж•°жҚ®еҲ©зӣҠеҪ’еұһзҡ„е®һи·өе·ІиҮӘеҸ‘ејҖеұ•е№¶дёҚж–ӯж·ұе…ҘгҖӮж—©еңЁ2016е№ҙпјҢеҚўжЈ®е ЎвҖңйҖӮеҗҲй«ҳж•ҲгҖҒе…¬е№іең°иҺ·еҸ–гҖҒдҪҝз”Ёе’ҢдәӨжҚўж•°жҚ®зҡ„жі•еҫӢеҲ¶еәҰвҖқеҗ¬иҜҒдјҡдёҠпјҢдә§дёҡз•Ңзҡ„зӣёе…ідәәеЈ«е°ұдёҖиҮҙеЈ°з§°пјҢ他们е®Ңе…ЁеҸҜд»Ҙдҫқйқ еҗҲеҗҢжі•е®һж–Ҫж¶үеҸҠж•°жҚ®е…ұдә«зҡ„е•ҶдёҡжЁЎејҸпјҢ并д»ҘжӯӨдҪңдёәеҸҚеҜ№еј•е…Ҙж–°еһӢжқғеҲ©зҡ„зҗҶз”ұпјӣ欧зӣҹ委е‘ҳдјҡ2017е№ҙзҡ„е·ҘдҪңж–Ү件дёӯд№ҹжҢҮеҮәпјҢеңЁе°ҡж— е…¶д»–жі•еҫӢжҸҗдҫӣжҳҺ确规еҲҷзҡ„жғ…еҶөдёӢпјҢеҹәдәҺеҗҲеҗҢиҮӘз”ұеҺҹеҲҷзҡ„иҮӘж„ҝж•°жҚ®дәӨжҳ“иў«и§ҶдёәеёӮеңәз»ҸжөҺжңҖйҖӮеҗҲзҡ„и§ЈеҶіж–№жЎҲгҖӮиҖҢеҹәдәҺж•°жҚ®дәӨжҳ“зҡ„зү№ж®ҠжҖ§пјҢд»…еҮӯеҗҲеҗҢжі•дёҖиҲ¬еҺҹеҲҷе°ҡжңүдёҖдәӣй—®йўҳйҡҫд»Ҙи§ЈеҶіпјҢйңҖиҰҒй’ҲеҜ№жҖ§зҡ„规еҲҷдәҲд»Ҙеј•еҜје’ҢеӨ„зҗҶгҖӮ е…¶дёҖпјҢж•°жҚ®дәӨжҳ“зҡ„зү№ж®ҠжҖ§дҪҝеҗҲеҗҢжі•йқўеҜ№ж–°и®®йўҳзҡ„жҢ‘жҲҳгҖӮж•°жҚ®з»ҸжөҺдёӯеҸҜдәӨжҳ“зҡ„еҜ№иұЎж—ўйқһдј з»ҹзҡ„дә§е“ҒжҲ–жқғеҲ©вҖ”вҖ”жңүеӯҰиҖ…и®Өдёәд№ҹйқһж•°жҚ®жңҚеҠЎвҖ”вҖ”иҖҢе°ұжҳҜвҖңж•°жҚ®вҖқжң¬иә«гҖӮд»ҺжҠҖжңҜи§’еәҰиҖҢиЁҖпјҢж•°жҚ®дәӨжҳ“еҗҲеҗҢдёӯиў«вҖңеҮәе”®вҖқзҡ„并йқһжҳҜдҪҝз”Ёж— еҪўж•°жҚ®зҡ„и®ёеҸҜпјҢиҖҢжҳҜе…·жңүзү№е®ҡеҗ«д№үзҡ„дәҢиҝӣеҲ¶и„үеҶІпјҲbinary impulsesпјүпјҢйҖҡеёёиЎЁзҺ°дёәвҖңжү№йҮҸвҖқжҲ–вҖңдёІиЎҢвҖқж•°жҚ®зҡ„еҪўејҸгҖӮиҝҷз§ҚдәҢиҝӣеҲ¶и„үеҶІеҸҜд»ҘеңЁжңәеҷЁзҡ„дҪңз”ЁдёӢе®һзҺ°еӯҳеӮЁгҖҒдј иҫ“е’ҢеӨ„зҗҶгҖӮеӣ жӯӨпјҢеӯҰиҖ…е°Ҷе…¶еҢәеҲ«дәҺдј з»ҹдҝЎжҒҜжңҚеҠЎпјҢи®Өдёәдј з»ҹзҡ„дҝЎжҒҜжңҚеҠЎеҗҲеҗҢзҡ„дё»еҗҲеҗҢд№үеҠЎжҳҜвҖңеҒҡжҹҗ件дәӢвҖқпјҲдҫӢеҰӮпјҢд»Ҙзү№е®ҡж јејҸжҸҗдҫӣдҝЎжҒҜпјүпјӣиҖҢж•°жҚ®еҗҲеҗҢзҡ„дё»иҰҒд№үеҠЎжҳҜвҖңжҸҗдҫӣжҹҗдәӣдёңиҘҝвҖқпјҲеҚізү№е®ҡж јејҸгҖҒзү№е®ҡеҗ«д№үзҡ„еӨ§йҮҸдәҢиҝӣеҲ¶и„үеҶІпјүгҖӮ дёҚд»…ж•°жҚ®жҲҗдёәдёҖз§Қе…Ёж–°зұ»еһӢзҡ„еҗҲеҗҢж Үзҡ„пјҢж•°жҚ®дәӨжҳ“зҡ„еӨ–и§Ӯд№ҹе‘ҲзҺ°еҮәзӢ¬зү№зҡ„еҪўејҸгҖӮдҫӢеҰӮпјҢж•°жҚ®з»ҸжөҺдёӯдёҖзұ»жҷ®йҒҚзҡ„дәӨжҳ“жЁЎејҸжҳҜж•°жҚ®жҺ§еҲ¶иҖ…Aе…Ғи®ёдҪҝз”ЁиҖ…BеҲ©з”Ёжҹҗдәӣз®—жі•и®ҝй—®AжңҚеҠЎеҷЁеҶ…зү№е®ҡз©әй—ҙзҡ„ж•°жҚ®пјҢиҖҢиҝҷз§ҚдәӨжҳ“еңЁж—ўжңүзҡ„еҗҲеҗҢжі•дҪ“зі»дёӯйҡҫд»ҘжүҫеҲ°еҜ№еә”зҡ„规еҲ¶и§„еҲҷгҖӮеҶҚиҖ…пјҢж•°жҚ®йқһз«һдәүгҖҒйқһжҺ’д»–зҡ„зү№жҖ§д№ҹеҖјеҫ—е…іжіЁгҖӮдҫӢеҰӮпјҢеҗҲеҗҢи§ЈйҷӨеҗҺзҡ„иҙўдә§иҝ”иҝҳиҙЈд»»еңЁж•°жҚ®еҗҲеҗҢдёҠзҡ„иЎЁиҫҫпјҢдёҚеә”еҪ“жҳҜиҝ”иҝҳж•°жҚ®пјҢиҖҢжҳҜеҲ йҷӨжҺ§еҲ¶ж•°жҚ®гҖӮ з”ұдәҺеӨҡж•°еӣҪ家й’ҲеҜ№ж•°жҚ®жІ»зҗҶзҡ„и·Ҝеҫ„йҖүжӢ©е’ҢйҖӮ用规еҲҷд»ҚеңЁжҺўзҙўд№ӢдёӯпјҢ规еҲҷзҡ„дёҚзЎ®е®ҡжҖ§иў«и®Өдёәз ҙеқҸдәҶж•°жҚ®дәӨжҳ“жүҖеҝ…йңҖзҡ„еҸҜйў„и§ҒжҖ§гҖӮдёҖж–№йқўпјҢеҜ№жі•еҫӢйЈҺйҷ©е’ҢжҲҗжң¬зҡ„жӢ…еҝ§еҸҜиғҪжҠ‘еҲ¶еёӮеңәдё»дҪ“иҝӣиЎҢдәӨжҳ“зҡ„з§ҜжһҒжҖ§пјӣеҸҰдёҖж–№йқўпјҢзјәд№Ҹй’ҲеҜ№ж•°жҚ®дәӨжҳ“зҡ„规еҲ¶и§„еҲҷд№ҹиў«иҙЁз–‘дјҡеј•иҮҙеёӮеңәеӨұзҒөе’ҢдёҚе…¬е№іпјҢе°Өе…¶жҳҜдёҚеҲ©дәҺи®®д»·иғҪеҠӣиҫғејұеҠҝзҡ„дёҖж–№гҖӮжӯӨеӨ–пјҢз”ұдәҺзјәд№ҸжңүзӣҠзҡ„жҢҮеј•зӨәиҢғпјҢеҪ“дәӢдәәжӢҹе®ҡзҡ„ж•°жҚ®еҗҲеҗҢжқЎж¬ҫеҸҜиғҪйқһеёёеӨҚжқӮдё”дҪҺж•ҲпјҢеҗҢж ·дёҚеҲ©дәҺж•°жҚ®дәӨжҳ“зҡ„ејҖеұ•гҖӮеӣ жӯӨпјҢж•°жҚ®еҗҲеҗҢзҡ„зӨәиҢғжҖ§ж–Үжң¬еҜ№дәҺе®һи·өдёӯзҡ„ж•°жҚ®з»ҸжөҺзҡ„еҸ‘еұ•д№ҹеҫҲжңүд»·еҖјгҖӮ е…¶дәҢпјҢвҖңж•°жҚ®з»ҸжөҺеҮҶеҲҷвҖқпјҡж•°жҚ®еҗҲеҗҢжІ»зҗҶ规еҲҷзҡ„йӣҶдёӯжҸҗеҮәгҖӮй’ҲеҜ№ж•°жҚ®еҗҲеҗҢе…ізі»дёӯе…·дҪ“й—®йўҳзҡ„з ”з©¶жңүдёҖдәӣж–°иҝӣеұ•гҖӮ欧жҙІжі•еҫӢз ”з©¶жүҖе’ҢзҫҺеӣҪжі•еҫӢеҚҸдјҡпјҲд»Һ2016е№ҙејҖе§ӢиҒ”еҗҲејҖеұ•дәҶдёҖйЎ№еҗҚдёәвҖңж•°жҚ®з»ҸжөҺеҮҶеҲҷвҖқпјҲдёӢз§°вҖңеҮҶеҲҷвҖқпјүзҡ„з ”з©¶пјҢеҜ№ж•°жҚ®еҗҲеҗҢеұ•ејҖй’ҲеҜ№жҖ§зҡ„еҲҶжһҗпјҢжҺўзҙўе»әз«Ӣж•°жҚ®дәӨжҳ“дёӯиғҪе’Ңеҗ„з§Қжі•еҫӢдҪ“зі»е…је®№зҡ„йҖҡиЎҢеҺҹеҲҷпјҢ并жңҹеҫ…дёәж•°жҚ®з«Ӣжі•жҸҗдҫӣе»әи®®е’ҢеҗҜзӨәгҖӮ2021е№ҙ9жңҲпјҢеҮҶеҲҷзҡ„жңҖз»ҲзүҲиҚүжЎҲиҺ·еҫ—йҖҡиҝҮгҖӮ еҮҶеҲҷеңЁж•°жҚ®еҗҲеҗҢзұ»еһӢеҢ–зҡ„и§ҶйҮҺдёӢеұ•ејҖеҗҲеҗҢ规еҲҷгҖӮйҰ–е…ҲпјҢе®ҡд№ү并з•ҢеҲҶдәҶвҖңж•°жҚ®жҸҗдҫӣеҗҲеҗҢвҖқдёҺвҖңж•°жҚ®жңҚеҠЎеҗҲеҗҢвҖқгҖӮж №жҚ®е…·дҪ“ж•°жҚ®жҸҗдҫӣж–№ејҸзҡ„е·®ејӮпјҢж•°жҚ®жҸҗдҫӣеҗҲеҗҢеҲҶдёәж•°жҚ®дј иҫ“еҗҲеҗҢгҖҒз®ҖеҚ•и®ҝй—®ж•°жҚ®еҗҲеҗҢгҖҒдҪҝз”Ёж•°жҚ®жәҗеҗҲеҗҢгҖҒи®ҝй—®жҺҲжқғеҗҲеҗҢгҖҒж•°жҚ®жұ еҗҲеҗҢдә”зұ»гҖӮеҮҶеҲҷи®ӨдёәпјҢж•°жҚ®жҸҗдҫӣиЎҢдёәзҡ„жҖ§иҙЁжҳҜвҖңй”Җе”®вҖқиҖҢйқһвҖңи®ёеҸҜвҖқпјҢиҝҷж„Ҹе‘ізқҖж•°жҚ®жҺҘ收方иҺ·еҫ—дәҶж•°жҚ®жң¬иә«пјҢ并еҸҜд»Ҙе°Ҷж•°жҚ®з”ЁдәҺд»»дҪ•еҗҲжі•зӣ®зҡ„гҖӮй’ҲеҜ№жҜҸзұ»е…ёеһӢзҡ„ж•°жҚ®жҸҗдҫӣеҗҲеҗҢпјҢеҮҶеҲҷеҜ№ж•°жҚ®жҸҗдҫӣиҖ…еұҘиЎҢжүҝиҜәзҡ„ж–№ејҸгҖҒжүҖжҸҗдҫӣж•°жҚ®зҡ„зү№еҫҒгҖҒжүҖжҸҗдҫӣж•°жҚ®зҡ„жҺ§еҲ¶зӯүе…·дҪ“й—®йўҳжҸҗдҫӣдәҶй»ҳзӨәжқЎж¬ҫгҖӮе…¶ж¬ЎпјҢеҮҶеҲҷи®Өдёәж•°жҚ®жңҚеҠЎеҗҲеҗҢеҢ…жӢ¬ж•°жҚ®еӨ„зҗҶеҗҲеҗҢе’Ңж•°жҚ®дҝЎжүҳеҗҲеҗҢпјҢ并жҸҗеҮәдәҶжңүе…іж•°жҚ®жңҚеҠЎеҗҲеҗҢдёӯж•°жҚ®еӨ„зҗҶиҖ…е’ҢжҺ§еҲ¶иҖ…жқғеҲ©дёҺд№үеҠЎзҡ„еҗ„з§Қе…·дҪ“规еҲ¶и§„еҲҷгҖӮжӣҙиҝӣдёҖжӯҘпјҢеҮҶеҲҷеҲҶжһҗдәҶж•°жҚ®з»ҸжөҺдёӯжі•еҫӢеә”еҪ“е…·дҪ“дҝқжҠӨзҡ„еҲ©зӣҠпјҢдҪңдёәе®Ўи§Ҷж•°жҚ®еҗҲеҗҢ规иҢғжҖ§зҡ„еҮәеҸ‘зӮ№е’ҢдёҠдҪҚйҖ»иҫ‘гҖӮеҮҶеҲҷе»әи®®жүҝи®Өж•°жҚ®дҪҝз”ЁиҖ…еҜ№жҠ—ж•°жҚ®жҺ§еҲ¶иҖ…зҡ„зү№е®ҡжқғеҲ©пјҢеҢ…жӢ¬еңЁйҖӮеҪ“жғ…еҶөдёӢиҰҒжұӮж•°жҚ®и®ҝй—®гҖҒиҰҒжұӮж•°жҚ®жҺ§еҲ¶иҖ…еҒңжӯўж•°жҚ®жҙ»еҠЁгҖҒиҰҒжұӮж•°жҚ®жҺ§еҲ¶иҖ…жӣҙжӯЈдёҚжӯЈзЎ®жҲ–дёҚе®Ңж•ҙзҡ„ж•°жҚ®д»ҘеҸҠд»ҺдҪҝз”Ёж•°жҚ®дә§з”ҹзҡ„еҲ©ж¶ҰдёӯиҺ·еҫ—з»ҸжөҺд»ҪйўқзӯүжқғеҲ©гҖӮжӯӨеӨ–пјҢеҮҶеҲҷжҸҗеҮәдәҶеҜ№дәҺеҸҢж–№е…ұеҗҢз”ҹжҲҗзҡ„ж•°жҚ®пјҢзӣёеә”зҡ„еҲ©зӣҠеҲҶй…Қеә”еҪ“еҹәдәҺе…¬е№іеҺҹеҲҷпјҢиҝӣиЎҢзҒөжҙ»зҡ„дёӘжЎҲеҲҶжһҗпјҢ并иҖғиҷ‘еҢ…жӢ¬еҸҢж–№еңЁж•°жҚ®з”ҹжҲҗдёӯзҡ„иҙЎзҢ®д»ҪйўқгҖҒи®®д»·иғҪеҠӣгҖҒе…¬е…ұеҲ©зӣҠзӯүеӣ зҙ гҖӮжңҖеҗҺпјҢеҮҶеҲҷд№ҹиҖғиҷ‘дәҶж¶үеҸҠе…¬е…ұеҲ©зӣҠзҡ„ж•°жҚ®дёӯж•°жҚ®жҺ§еҲ¶иҖ…зҡ„иҙЈд»»е’ҢжҺҘеҸ—иҖ…зҡ„ж•°жҚ®дҪҝз”Ёй—®йўҳпјҢжҸҗеҮәж¶үеҸҠе…¬е…ұеҲ©зӣҠзҡ„ж•°жҚ®жҺ§еҲ¶иҖ…еә”еҹәдәҺе…¬е№ігҖҒеҗҲзҗҶгҖҒж— жӯ§и§Ҷзҡ„еҺҹеҲҷжҸҗдҫӣж•°жҚ®и®ҝй—®жқғйҷҗпјӣиҖҢж•°жҚ®и®ҝй—®иҖ…еә”еҪ“еҹәдәҺдә’жғ еҺҹеҲҷпјҢе…Ғи®ёж•°жҚ®жҸҗдҫӣиҖ…и®ҝй—®еҸҜжҜ”ж•°жҚ®гҖӮжӯӨеӨ–пјҢеҮҶеҲҷиҝҳи®әиҝ°дәҶж•°жҚ®жҙ»еҠЁдёӯпјҢдәӨжҳ“еҸҢж–№еҜ№з¬¬дёүж–№йқһе№Іж¶үд№үеҠЎеҸҠеұҘиЎҢпјҢд»ҘеҸҠж•°жҚ®и·ЁеўғдәӨжҳ“дёӯзҡ„еӣҪйҷ…з§Ғ法规еҲҷгҖӮ е…¶дёүпјҢеҜ№ж•°жҚ®еҗҲеҗҢ规еҲ¶и·Ҝеҫ„зҡ„иҜ„д»·гҖӮйҖҡиҝҮжҳҺзЎ®ж•°жҚ®дәӨжҳ“зҡ„еҗҲеҗҢ规еҲҷиҝӣиЎҢж•°жҚ®жІ»зҗҶпјҢж—ўжңүзқҖе……еҲҶзҡ„зҺ°е®һеҝ…иҰҒпјҢеҸҲжңүзқҖзҒөжҙ»гҖҒе…·дҪ“зҡ„зҺ°е®һдјҳеҠҝгҖӮж•°жҚ®еёӮеңәзҡ„дәӨжҳ“е®һи·өе·Із»ҸдҫқжҚ®дёҖиҲ¬жҖ§зҡ„еҗҲеҗҢиҮӘз”ұзӯүеҺҹеҲҷпјҢйҖҡиҝҮеҪ“дәӢдәәд№Ӣй—ҙзҡ„иҮӘж„ҝеҚҸе•Ҷе»әз«ӢдәҶж•°жҚ®дәӨжҳ“еҲқжӯҘ秩еәҸгҖӮиҝҷз§ҚиҮӘеҸ‘秩еәҸдёӯе…¬е№іеҗҲзҗҶзҡ„йғЁеҲҶйңҖиҰҒжі•еҫӢжүҝи®Өе’Ңз»ҙжҠӨпјҢжңүиҝқе…¬е№ізҡ„йңҖиҰҒжі•еҫӢ规иҢғдәҲд»Ҙ规еҲ¶гҖӮ然иҖҢпјҢдёҖж–№йқўпјҢеңЁж•°жҚ®дәӨжҳ“зҡ„еңәжҷҜдёӯж–°жҠҖжңҜгҖҒж–°жЁЎејҸгҖҒж–°еҲ©зӣҠд№ӢдёӢпјҢиҮӘж„ҝгҖҒе…¬е№ігҖҒиҜҡе®һдҝЎз”ЁзӯүжҰӮеҝөеҸҜиғҪдёҚеҶҚжҳҜдёҚиЁҖиҮӘжҳҺзҡ„пјҢйңҖиҰҒе…·дҪ“еҢ–дёәзӣёеә”зҡ„规еҲҷдәҲд»ҘиҫЁиҜҶгҖӮеӣ жӯӨпјҢжі•еҫӢйңҖиҰҒжңүй’ҲеҜ№жҖ§ең°йҳҗйҮҠдёҖиҲ¬жҖ§зҡ„еҗҲеҗҢеҺҹеҲҷеҰӮдҪ•е…·дҪ“дҪңз”ЁдәҺеҜҢжңүзү№ж®ҠжҖ§зҡ„ж•°жҚ®е®һи·өдёӯгҖӮеҸҰдёҖж–№йқўпјҢе°Ҷж•°жҚ®еҗҲеҗҢиҝӣиЎҢзұ»еһӢеҢ–зҡ„з»ҶеҲҶд№ҹжҳҜдёҖз§ҚжңүзӣҠзҡ„е°қиҜ•гҖӮзӣёиҫғдәҺвҖңж•°жҚ®еҗҲеҗҢвҖқзҡ„жЁЎзіҠжҰӮеҝөпјҢеҺҳжё…ж•°жҚ®жҸҗдҫӣеҗҲеҗҢе’Ңж•°жҚ®жңҚеҠЎеҗҲеҗҢзҡ„иҫ№з•ҢпјҢ并еңЁе…·дҪ“зұ»еһӢдёӢжҳҺзЎ®жіЁж„ҸиҰҒзҙ гҖҒжҸҗдҫӣзӨәиҢғжҖ§ж–Үжң¬пјҢиғҪеӨҹеҠ©еҠӣж•°жҚ®еёӮеңәдәӨжҳ“зҡ„е№ізЁій«ҳж•ҲиҝҗиЎҢгҖӮ жі•еҫӢеҜ№ж•°жҚ®еҗҲеҗҢзҡ„е№Ійў„жҳҜеҝ…иҰҒзҡ„пјҢеҗҢж—¶д№ҹеә”е®Ўж…ҺжҠҠжҸЎд»Ӣе…Ҙе°әеәҰгҖӮжңүеӯҰиҖ…жҸҗйҶ’пјҢеңЁеҗҲеҗҢжі•дёӯеҜ№еҘ‘зәҰиҮӘз”ұзҡ„е№Ійў„еә”еҪ“еҹәдәҺеёӮеңәеӨұзҒөзҡ„жҳҺзЎ®иҜҒжҚ®гҖӮд»…д»…еҹәдәҺеҜ№е…¬е№ізҡ„иҝҪжұӮпјҢеӣ дёәж•°жҚ®еҗҲеҗҢеҸҢж–№еҠӣйҮҸзҡ„дёҚеқҮиЎЎдҫҝж¬ІеҮәжүӢе№Ійў„пјҢеҸҜиғҪиҗҪе…ҘвҖңжі•еҫӢзҲ¶зҲұдё»д№үвҖқпјҢе…¶еҗҲзҗҶжҖ§е№¶жңӘеҫ—еҲ°е……еҲҶи®әиҜҒгҖӮ жҖ»зҡ„жқҘиҜҙпјҢеңЁж•°жҚ®еҗҲеҗҢжІ»зҗҶй—®йўҳдёҠпјҢйңҖиҰҒд»ҺзҗҶи®әеұӮйқўи§ЈеҶізҡ„дҪ“зі»е»әжһ„е’ҢжқғеҲ©еҶІзӘҒзӯүй—®йўҳеҸҜиғҪдёҚз”ҡжҳҫи‘—пјӣиҖҢж·ұе…Ҙж•°жҚ®дәӨжҳ“е…·дҪ“е®һи·өпјҢзҗҶйЎәж•°жҚ®дәӨжҳ“зҡ„зҺ°е®һйңҖжұӮдёҺеӣ°йҡҫпјҢ并жҳҺзӨәй’ҲеҜ№жҖ§зҡ„规еҲҷеҸҜиғҪжӣҙдёәйҮҚиҰҒгҖӮеӣ жӯӨпјҢж— и®әз«Ӣжі•жҳҜеҗҰе·Із»ҸжҳҺзЎ®дәҶж•°жҚ®жІ»зҗҶзҡ„и·Ҝеҫ„йҖүжӢ©пјҢж•°жҚ®дәӨжҳ“дёӯи®ўз«ӢеҗҲеҗҢзҡ„йңҖжұӮе§Ӣз»ҲеӯҳеңЁпјӣеҗҲеҗҢжІ»зҗҶзӣёеҜ№жқҘиҜҙд№ҹжӣҙе…·еҢ…е®№жҖ§пјҢж— и®әжі•еҫӢжңҖз»ҲеҶіе®ҡиөӢжқғвҖ”вҖ”йҳІеҫЎжқғиҝҳжҳҜжҺ’д»–жқғпјӣиөӢжқғзҡ„еҜ№иұЎж— и®әжҳҜж•°жҚ®з”ҹдә§иҖ…гҖҒеӨ„зҗҶиҖ…жҲ–жҳҜи®ҝй—®иҖ…пјҢдёҖеҘ—ж•°жҚ®дәӨжҳ“еҗҲеҗҢзҡ„жІ»зҗҶеҺҹеҲҷйғҪеҸҜд»ҘдёҺд№Ӣе…је®№гҖӮеӣ жӯӨпјҢеңЁж•°жҚ®жқғеҲ©еҪ’еұһгҖҒж•°жҚ®дҝқжҠӨжЁЎејҸзҗҶи®әдәүйёЈдёҚдј‘пјҢе°ҡйҡҫеҪўжҲҗе№ҝжіӣзҡ„йҖҡиҜҙе…ұиҜҶд№Ӣж—¶пјҢжҲ–и®ёеә”еҪ“иҖғиҷ‘еҖҹйүҙ欧зҫҺзҡ„ж•°жҚ®з»ҸжөҺеҮҶеҲҷпјҢд»ҺеҗҲеҗҢ规еҲҷеұӮйқўеҜ№ж•°жҚ®дәӨжҳ“зҡ„е®һи·өйңҖжұӮдәҲд»ҘеҸҠж—¶еӣһеә”гҖӮ 04 дҪҷи®әпјҡж•°жҚ®жІ»зҗҶзҡ„вҖңдёҚиҰҒвҖқдёҺвҖңиҰҒвҖқ еҪ“еүҚпјҢеҗ„еӣҪж•°жҚ®жІ»зҗҶзҡ„жі•еҫӢеә”еҜ№д»ҚеңЁжҺўзҙўйҳ¶ж®өпјҢиЎЁзҺ°еҮәдёҚеҗҢзҡ„жІ»зҗҶжҖҒеәҰе’Ңи·Ҝеҫ„йҖүжӢ©пјҢеӯҰжңҜз•Ңд№ҹеӣҙз»•ж•°жҚ®жІ»зҗҶз§ҜжһҒгҖҒжҙ»и·ғең°иҙЎзҢ®еҮәдёҚеҗҢзҡ„и§Ҷи§’е’ҢжҖқи·ҜгҖӮжң¬ж–Ү并йқһж„ҸеңЁе°ҶзҺ°жңүж•°жҚ®жІ»зҗҶзҡ„дёҚеҗҢжҖқи·ҜиҝӣиЎҢжЁӘеҗ‘жҜ”иҫғпјҢжҸҗеҮәдёҖдёӘвҖңжңҖдјҳи§ЈвҖқгҖӮзӣёеҸҚпјҢд»…еҮӯз»ҸйӘҢжҖ§зҡ„жҜ”иҫғз ”з©¶еҫҲйҡҫзӣҙжҺҘеҫ—еҮәе“Әз§Қж•°жҚ®жІ»зҗҶжЁЎејҸжңҖиғҪдҪҝж•°жҚ®дә§дёҡеҸ‘еұ•еҸ—зӣҠпјҢжӣҙйҡҫд»ҘжҚ®жӯӨзӣҙжҺҘеӣһзӯ”е“Әз§Қж•°жҚ®жІ»зҗҶжЁЎејҸжӣҙеҗҲд№ҺжҲ‘еӣҪжң¬еңҹж•°жҚ®дә§дёҡеҸ‘еұ•зҺҜеўғгҖӮиҖҢж•°жҚ®жІ»зҗҶзҡ„еҹҹеӨ–еҲ¶еәҰе’ҢеӯҰиҜҙеҸӮиҖғжҲ–и®ёеҸҜд»ҘжҸҗзӨәжҲ‘们пјҢдҪ•з§ҚиҰҒзҙ еә”дәҲиҖғиҷ‘гҖҒдҪ•з§ҚжЁЎејҸеә”дәҲиӯҰжғ•гҖӮ жң¬ж–Үи®ӨдёәпјҢйҰ–е…Ҳеә”еҪ“ж‘’ејғзҡ„жҖқи·ҜжҳҜиЁҖвҖңдҝқжҠӨвҖқеҝ…иЁҖвҖңжҺ’д»–жқғвҖқгҖӮдёәж•°жҚ®жҺ§еҲ¶иҖ…и®ҫз«ӢжҺ’д»–жқғд»ҘжҝҖеҠұж•°жҚ®з”ҹдә§е’Ңж•°жҚ®еӨ„зҗҶе·ІдёҚеҶҚжҳҜдё»жөҒзҡ„жІ»зҗҶж–№жЎҲпјӣеӯҰжңҜз•Ңд№ҹд»ҺжҝҖеҠұзҡ„еҝ…иҰҒжҖ§гҖҒз•Ңжқғзҡ„еҸҜиғҪжҖ§гҖҒдҪ“зі»зҡ„еҚҸи°ғжҖ§гҖҒжҺ’д»–жқғзҡ„еұҖйҷҗжҖ§зӯүиҜёеӨҡж–№йқўеҜ№иөӢжқғи®әиҝӣиЎҢеҸҚжҖқгҖӮжі•еҫӢжІ»зҗҶжЎҶжһ¶зҡ„жҸҗеҮәйңҖиҰҒеҘ‘еҗҲж•°жҚ®з»ҸжөҺдёӯзҡ„жҠҖжңҜйҖ»иҫ‘гҖҒеёӮеңәйҖ»иҫ‘гҖӮйқһз«һдәүжҖ§е’ҢйқһжҺ’д»–жҖ§жҳҜж•°жҚ®еҢәеҲ«дәҺдј з»ҹз”ҹдә§иҰҒзҙ зҡ„е…ій”®зү№зӮ№пјҢеҖјеҫ—ж•°жҚ®и§„еҲҷзҡ„и®ҫи®ЎиҖ…жӣҙеӨҡе…іжіЁгҖӮжӣҙдёәе…ій”®зҡ„жҳҜпјҢеҢәеҲ«дәҺдҪңе“ҒжҲ–е…¬ејҖзҡ„жҠҖжңҜж–№жЎҲпјҢж•°жҚ®йҖҡеёёиғҪеӨҹеҸ—еҲ°дёҖе®ҡзЁӢеәҰзҡ„иҮӘеҠӣжҺ§еҲ¶пјҢж— йңҖжі•еҫӢд№ӢеҠӣйўқеӨ–иөӢдәҲзҡ„зҰҒжӯўжқғеҚіиғҪжҲҗдёәдәӨжҳ“еҜ№иұЎгҖҒе®һзҺ°з»ҸжөҺд»·еҖјгҖӮиҝҷдёҖзӮ№жӣҙзұ»дјјдәҺе•Ҷдёҡз§ҳеҜҶгҖӮеӣ жӯӨпјҢеҰӮжһңжӯӨж—¶з»ҷдәҲж•°жҚ®еӨ„зҗҶжҲ–жҺ§еҲ¶иҖ…д»ҘжҺ’д»–жқғпјҢжһҒжңүеҸҜиғҪжҠ‘еҲ¶ж•°жҚ®зҡ„еҸҜеҫ—жҖ§е’ҢжөҒеҠЁжҖ§пјҢе°ҶдёҺж•°жҚ®з»ҸжөҺејҖж”ҫгҖҒе…ұдә«зҡ„еҹәжң¬йҖ»иҫ‘зӣҙжҺҘзӣёжӮ–гҖӮеӣ жӯӨпјҢж•°жҚ®зҡ„жІ»зҗҶеә”еҪ“йҒҝе…ҚеҜ№дёҠдёҖдёӘж— дҪ“иҙўдә§дҝқжҠӨзҡ„жҲҗеҠҹе…ҲдҫӢвҖ”вҖ”вҖңзҹҘиҜҶдә§жқғејҸвҖқзҡ„жҺ’д»–жқғжһ„йҖ зҡ„и·Ҝеҫ„дҫқиө–пјҢдёҚе®ңи®ҫз«ӢвҖңж•°жҚ®зҹҘиҜҶдә§жқғвҖқжҲ–д»Ҙз»қеҜ№жқғзҡ„еҪўејҸжһ„йҖ ж•°жҚ®иҙўдә§жқғгҖӮ е…¶ж¬ЎпјҢж•°жҚ®жІ»зҗҶзҡ„дёӯеҝғд»·еҖјд№ҹ并йқһвҖңдҝқжҠӨвҖқпјҢиҖҢеңЁдәҺејҖж”ҫе’ҢеҲ©з”ЁгҖӮеҜ№дәҺзҹҘиҜҶдә§жқғе®ўдҪ“иҖҢиЁҖпјҢвҖңдҝқжҠӨвҖқж—ўжҳҜеҜ№дәәзұ»еҲӣйҖ еҠӣжҠ•е…Ҙзҡ„еҝ…иҰҒвҖңеҳүеҘ–вҖқпјҢд№ҹжҳҜе®һзҺ°зӨҫдјҡе…¬зӣҠзҡ„дёӯй—ҙжүӢж®өгҖӮ然иҖҢпјҢеңЁж•°жҚ®йўҶеҹҹпјҢж—ўдёҚеӯҳеңЁиҮӘ然жқғеҲ©зҡ„дҝқжҠӨиҜүжұӮпјҢеҸҲйҡҫд»ҘиҜҒз«ӢжҝҖеҠұдёҚи¶ізҡ„е®һи·өзҺҜеўғгҖӮжҠ•иө„йј“еҠұжҲ–дәӨжҳ“е®үе®ҡжҖ§зҡ„иҜүжұӮеҖјеҫ—жӯЈи§ҶпјҢеҚҙеҸҲ并йқһжңҖдјҳдҪҚзҡ„д»·еҖјгҖӮеә”еҪ“и®ӨиҜҶеҲ°пјҢж•°жҚ®е®һи·өдёӯзЁҖзјәзҡ„并йқһжҠ•иө„еӣһжҠҘпјҢиҖҢжҳҜз•…йҖҡгҖҒжңүеәҸзҡ„ж•°жҚ®иҺ·еҸ–е’ҢеҲ©з”ЁзҺҜеўғгҖӮдёҺе…¶иҝӮеӣһең°з”ұдҝқжҠӨжҺ§еҲ¶еҲ°дҝғиҝӣжөҒеҠЁпјҢдёҚеҰӮе°ҶжІ»зҗҶи§ҶйҮҺзӣҙжҺҘиҒҡз„ҰеҲ°дҫҝеҲ©ж•°жҚ®иҺ·еҸ–зҡ„жңәеҲ¶гҖӮ еҜ№дәҺвҖңиҰҒвҖқзҡ„йғЁеҲҶпјҢйҰ–е…Ҳжі•еҫӢиҰҒеӣһеә”е®һи·өдёӯж•°жҚ®дәӨжҳ“еҹәзЎҖдёҚжҳҺзЎ®зҡ„еӣ°жғ‘пјҢе»әз«Ӣеҝ…иҰҒзҡ„规еҲҷгҖӮйқһи®ҫжҺ’д»–жқғзҡ„жІ»зҗҶжҖқи·Ҝ并дёҚж„Ҹе‘ізқҖеҗҰе®ҡе…¶д»–еҪўејҸзҡ„ж•°жҚ®з•ҢжқғеҸҜиғҪжҖ§пјӣжҲ–жҳҜи®Өдёәе…ҚдәҺеј•е…Ҙз»ҹдёҖ规еҲҷпјҢж”ҫд»»е°Ҷж•°жҚ®ж°‘дәӢзә зә·з»ҹдёҖз•ҷз»ҷгҖҠеҸҚдёҚжӯЈеҪ“з«һдәүжі•гҖӢдёҖиҲ¬жқЎж¬ҫжҲ–вҖңдә’иҒ”зҪ‘дё“жқЎвҖқзҡ„е…ңеә•жҖ§жқЎж¬ҫпјҢеңЁдёӘжЎҲдёӯеҲҶеҲ«еӨ„зҗҶгҖӮзҺ°д»Јиҙўдә§жқғдҪ“зі»иў«и®ӨдёәжҳҜвҖңејҖж”ҫгҖҒеҠЁжҖҒгҖҒдёҚж–ӯеҸ‘еұ•вҖқзҡ„еј№жҖ§дҪ“зі»пјҢз»қйқһж— жі•е®№зәіжҺ’д»–жқғд№ӢеӨ–зҡ„е…¶д»–жқғеҲ©жһ„йҖ еҪўејҸгҖӮеҸӘжҳҜеңЁеҲ©зӣҠзҡ„з•ҢеҲҶд№Ӣж—¶пјҢеә”еҪ“зҗҶжё…иғҢеҗҺзҡ„д»·еҖјеҹәзЎҖе’Ңж ёеҝғе…іеҲҮпјҢйҮҚи§Ҷж•°жҚ®иҺ·еҸ–д»·еҖјпјҢ并审ж…ҺиҜ„дј°жі•еҫӢе№Ійў„зҡ„з•Ңйҷҗе’Ңж•ҲжһңгҖӮ йҷӨдәҶжқғеұһз•ҢеҲҶзҡ„еҚ•еҗ‘规еҲ¶и·Ҝеҫ„пјҢиҝҳеә”еҪ“з»јеҗҲиҖғиҷ‘ж•°жҚ®жІ»зҗҶзҡ„规еҲҷгҖӮеҜ№зү№е®ҡиҢғеӣҙж•°жҚ®зҡ„ејәеҲ¶е…ұдә«и§„еҲҷз•ҷжңүдёҖе®ҡйҖӮз”Ёз©әй—ҙгҖӮжҚўиЁҖд№ӢпјҢеҰӮжһңиҝӣиЎҢеҲ©зӣҠеҲҶй…ҚпјҢжҲ–и®ёиҖғиҷ‘е°ҶжӣҙеӨҡзҡ„ж•°жҚ®еҲ’е…Ҙе…¬жңүйўҶеҹҹпјҢиҖҢдёҚжҳҜд»»еёӮеңәиҮӘеҸ‘иҝӣиЎҢвҖңеңҲең°вҖқпјҲи°ҒйҰ–е…ҲжҺ§еҲ¶дәҶж•°жҚ®е°ұиҰҒжұӮдә«жңүж•°жҚ®д№ӢдёҠзҡ„е…ЁйғЁеҲ©зӣҠпјүгҖӮжӯӨеӨ–пјҢж•°жҚ®еҗҲеҗҢзҡ„规еҲ¶и§„еҲҷд№ҹеә”з•ҷжңүжӣҙеӨҡзҡ„зҗҶи®әжҺўи®Ёз©әй—ҙгҖӮзҺ°жңүз ”з©¶еӨҡжіЁйҮҚB2CеҗҲеҗҢж¶үеҸҠзҡ„з”ЁжҲ·еҗҢж„ҸгҖҒдёӘдәәдҝЎжҒҜдёӘдәәйҡҗз§ҒгҖҒж¶Ҳиҙ№иҖ…зҰҸеҲ©зӯүй—®йўҳпјҢиҖҢж•°жҚ®еёӮеңәдәӨжҳ“дёӯзҡ„B2BеҗҲеҗҢпјҢд»ҘеҸҠй…ҚеҘ—зҡ„еҸҚеһ„ж–ӯ规еҲҷйҖӮз”Ёзӯүй—®йўҳеҖјеҫ—жӣҙеӨҡе…іжіЁпјҢд№ҹеә”еҪ“жҸҗеҮәжӣҙжҳҺзЎ®зҡ„еҗҲеҗҢ规еҲҷдәҲд»ҘжҢҮеј•е’Ң规иҢғгҖӮпјҲжқҘжәҗпјҡгҖҠеӯҰжңҜеүҚжІҝгҖӢжқӮеҝ—2023е№ҙ3жңҲдёӢпјҲеҫ®дҝЎжңүеҲ иҠӮпјүпјү
| 
 еҶңдёҡж–°иҙЁз”ҹдә§еҠӣпјҡеҶ…ж¶ө
еҶңдёҡж–°иҙЁз”ҹдә§еҠӣпјҡеҶ…ж¶ө еҲҳдҝҠжқ°зӯүпјҡжһ„е»әйҖӮеә”еҶң
еҲҳдҝҠжқ°зӯүпјҡжһ„е»әйҖӮеә”еҶң 11жңҲе…Ёзҗғи°·зү©еёӮеңәдёҺиҙё
11жңҲе…Ёзҗғи°·зү©еёӮеңәдёҺиҙё з®Ўж¶ӣзӯүпјҡпјҡдәәж°‘еёҒжұҮзҺҮ
з®Ўж¶ӣзӯүпјҡпјҡдәәж°‘еёҒжұҮзҺҮ й’ҹжӯЈз”ҹпјҡеҗ‘е®ҢжҲҗйў„з®—зӣ®
й’ҹжӯЈз”ҹпјҡеҗ‘е®ҢжҲҗйў„з®—зӣ® жқҺиҝ…йӣ·пјҡжҳҺе№ҙиҙўж”ҝиөӨеӯ—
жқҺиҝ…йӣ·пјҡжҳҺе№ҙиҙўж”ҝиөӨеӯ— еј зәўе®Үпјҡжһ„е»әе…·жңүдёӯеӣҪ
еј зәўе®Үпјҡжһ„е»әе…·жңүдёӯеӣҪ ж—әеӯЈдёҚж—ә еҪ“еүҚз”ҹзҢӘеёӮ
ж—әеӯЈдёҚж—ә еҪ“еүҚз”ҹзҢӘеёӮ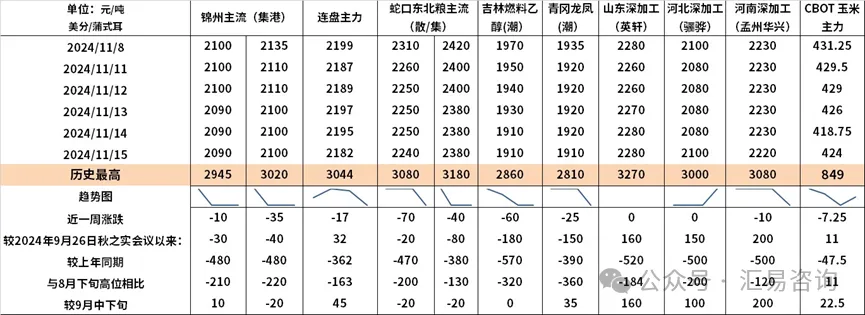 д»ҺеҪ“еүҚеӣҪеҶ…зҺүзұіеёӮеңәең°
д»ҺеҪ“еүҚеӣҪеҶ…зҺүзұіеёӮеңәең° з®Ўж¶ӣпјҡзү№жң—жҷ®еӣһеҪ’еҜ№дёӯ
з®Ўж¶ӣпјҡзү№жң—жҷ®еӣһеҪ’еҜ№дёӯ д»ҺеўғеӨ–з»ҸйӘҢзңӢиӮЎеёӮе№іеҮҶ
д»ҺеўғеӨ–з»ҸйӘҢзңӢиӮЎеёӮе№іеҮҶ







 еҸ‘иЎЁдәҺ 2023-7-12 09:54:48
еҸ‘иЎЁдәҺ 2023-7-12 09:54:48
 жҸҗеҚҮеҚЎ
жҸҗеҚҮеҚЎ зҪ®йЎ¶еҚЎ
зҪ®йЎ¶еҚЎ
 еҶңдёҡж–°иҙЁз”ҹдә§еҠӣпјҡеҶ…ж¶өдёҺеӨ–延гҖҒжҪңеҠӣдёҺжҢ‘жҲҳе’ҢеҸ‘еұ•жҖқи·Ҝ
еҶңдёҡж–°иҙЁз”ҹдә§еҠӣпјҡеҶ…ж¶өдёҺеӨ–延гҖҒжҪңеҠӣдёҺжҢ‘жҲҳе’ҢеҸ‘еұ•жҖқи·Ҝ еҰӮдҪ•жһ„е»әејҳжү¬ж•ҷиӮІе®¶зІҫзҘһзҡ„жңәеҲ¶дҪ“зі»пјҹжҠҠжҸЎеҘҪ
еҰӮдҪ•жһ„е»әејҳжү¬ж•ҷиӮІе®¶зІҫзҘһзҡ„жңәеҲ¶дҪ“зі»пјҹжҠҠжҸЎеҘҪ иҙўж”ҝйғЁпјҡжҸҗеүҚдёӢиҫҫ566дәҝе…ғпјҒ
иҙўж”ҝйғЁпјҡжҸҗеүҚдёӢиҫҫ566дәҝе…ғпјҒ зҺӢдәҡеҚҺпјҡд»Ҙжңүж•ҲжІ»зҗҶжҺЁиҝӣд№Ўжқ‘е…ЁйқўжҢҜе…ҙ
зҺӢдәҡеҚҺпјҡд»Ҙжңүж•ҲжІ»зҗҶжҺЁиҝӣд№Ўжқ‘е…ЁйқўжҢҜе…ҙ еҘҪз”ҹжҖҒдәҰжңүвҖңеҘҪд»·й’ұвҖқ зӨҫдјҡиө„жң¬йҰ–ж¬ЎеҸӮдёҺж°ҙ
еҘҪз”ҹжҖҒдәҰжңүвҖңеҘҪд»·й’ұвҖқ зӨҫдјҡиө„жң¬йҰ–ж¬ЎеҸӮдёҺж°ҙ


