马дёҠжіЁеҶҢе…ҘдјҡпјҢз»“дәӨ专家еҗҚжөҒпјҢдә«еҸ—иҙөе®ҫеҫ…йҒҮпјҢи®©дәӢдёҡз”ҹжҙ»еҸҢиөўгҖӮ
жӮЁйңҖиҰҒ зҷ»еҪ• жүҚеҸҜд»ҘдёӢиҪҪжҲ–жҹҘзңӢпјҢжІЎжңүеёҗеҸ·пјҹз«ӢеҚіжіЁеҶҢ


x
жўҒе№іжұүпјҲдёӯеұұеӨ§еӯҰдёӯеӣҪе…¬е…ұз®ЎзҗҶз ”з©¶дёӯеҝғз ”з©¶е‘ҳгҖҒж”ҝжІ»дёҺе…¬е…ұдәӢеҠЎз®ЎзҗҶеӯҰйҷўж•ҷжҺҲпјү ж•°жҚ®и¶ҠеӨҡи¶ҠеҘҪеҗ—
ж•°жҚ®зҡ„жң¬иҙЁжҳҜдҝЎжҒҜгҖӮвҖңдҝЎжҒҜи®әд№ӢзҲ¶вҖқйҰҷеҶңи®ӨдёәпјҢвҖңдҝЎжҒҜе°ұжҳҜз”ЁжқҘж¶ҲйҷӨдёҚзЎ®е®ҡжҖ§зҡ„дёңиҘҝвҖқгҖӮд№ҹе°ұжҳҜиҜҙпјҢж•°жҚ®дҪңдёәдёҖз§ҚиҰҒзҙ пјҢе…¶д»·еҖјжқҘиҮӘдәҺеҮҸе°‘дәәзұ»еҜ№дәҺеӨ–з•Ңи®ӨиҜҶзҡ„дёҚзЎ®е®ҡжҖ§пјҢд»ҺиҖҢжҸҗеҚҮеҶізӯ–иҙЁйҮҸгҖӮж•°жҚ®дёәеҶізӯ–жңҚеҠЎпјҢе…¶д»·еҖјжқҘиҮӘдәҺеҜ№дәҺзҹҘиҜҶгҖҒжҠҖжңҜгҖҒз®ЎзҗҶзӯүе…¶д»–з”ҹдә§иҰҒзҙ зҡ„иҙЁйҮҸзҡ„ж”№иҝӣпјҢиҖҢиҝҷдәӣз”ҹдә§иҰҒзҙ еҲҷйҖҡиҝҮдёҺиө„жң¬гҖҒеҠіеҠЁгҖҒеңҹең°зӯүз”ҹдә§иҰҒзҙ з»“еҗҲпјҢз”ҹдә§еҮәжӣҙеӨҡжӣҙж–°зҡ„дә§е“Ғе’ҢжңҚеҠЎгҖҒеҲӣйҖ еҮәжӣҙеӨҡжӣҙеӨ§зҡ„д»·еҖјгҖӮеҸҜд»ҘиҜҙж•°жҚ®иҰҒзҙ 并дёҚиғҪзӣҙжҺҘиҝӣе…Ҙз”ҹдә§иҝҮзЁӢпјҢе…¶д»·еҖјжҙҫз”ҹдәҺе…¶д»–иҰҒзҙ гҖӮд»ҺиҝҷдёҖи§’еәҰзңӢпјҢиҷҪ然еӨ§ж•°жҚ®зҡ„иҝҗз”ЁжҳҜжҷәж…§жІ»зҗҶзҡ„еүҚжҸҗпјҢдҪҶжҳҜжҲ‘们дёҚеә”иҝ·жҒӢдәҺжҗңйӣҶжӣҙеӨҡжӣҙй«ҳз»ҙеәҰзҡ„е…ЁйҮҸж•°жҚ®пјҢиҖҢеә”д»”з»ҶжҖқиҖғж•°жҚ®жң¬иә«еҸҜд»ҘеҸ‘жҢҘзҡ„дҪңз”ЁгҖӮ
д»ҺеҶізӯ–зҡ„и§’еәҰзңӢпјҢж•°жҚ®жҗңйӣҶд№ҹ并йқһи¶ҠеӨҡи¶ҠеҘҪгҖӮд»ҺжҰӮзҺҮи®әдёӯзҡ„иҙқеҸ¶ж–ҜзҗҶи®әжқҘзңӢпјҢж•°жҚ®йҖҡиҝҮжӣҙж–°дәә们еҜ№дәҺеҺҹжңүдәӢзү©зҡ„дҝЎеҝөеҸ‘жҢҘдҪңз”ЁгҖӮиҝҷе°ұдёҚеҸҜйҒҝе…ҚдјҡеҜјиҮҙеҶізӯ–иҖ…еңЁз»ҹи®ЎеӯҰдёҠзҡ„вҖң第дёҖзұ»й”ҷиҜҜвҖқпјҲжӢ’зңҹпјүе’ҢвҖң第дәҢзұ»й”ҷиҜҜвҖқпјҲе®№еҒҮпјүд№Ӣй—ҙжқғиЎЎгҖӮиҝҷдёҺж•°жҚ®жҗңйӣҶзҡ„жҲҗжң¬жҳҜеҗҰйқһеёёдҪҺе»үгҖҒж•°жҚ®иҰҒзҙ жң¬иә«жҳҜеҗҰе…·жңү规模з»ҸжөҺжҖ§ж— е…іпјҢеҸӘдёҺеҶізӯ–д»»еҠЎжң¬иә«зҡ„收зӣҠжҲҗжң¬жқғиЎЎжңүе…ігҖӮдҫӢеҰӮпјҢеңЁиҲӘз©әиҲӘеӨ©зӯүйўҶеҹҹпјҢиЎҢеҠЁеҮәй”ҷйҖ жҲҗзҡ„жҚҹеӨұйқһеёёй«ҳжҳӮпјҢеӣ жӯӨйңҖиҰҒе°ҪйҮҸеҮҸе°‘еҮәй”ҷзҡ„еҸҜиғҪжҖ§пјҢйңҖиҰҒеӨ§йҮҸж–°ж•°жҚ®д»ҘжңҖе°ҸеҢ–вҖңжӢ’зңҹвҖқзҡ„жҰӮзҺҮгҖӮдҪҶжҳҜпјҢеңЁж—Ҙеёёз”ҹжҙ»дёӯзҡ„и®ёеӨҡеҶізӯ–йўҶеҹҹпјҢеҰӮе…¬е®үеҮәиӯҰж•‘еҠ©гҖҒжҺҘеҲ°дёҫжҠҘйҮҮеҸ–иЎҢеҠЁзӯүпјҢй”ҷиҜҜеҮәиӯҰдә§з”ҹзҡ„жҲҗжң¬еҸҜиғҪиҝңе°ҸдәҺжңӘеҸҠж—¶еҮәиӯҰзҡ„жҲҗжң¬пјҢеҖҳиӢҘдёҚж–ӯжҗңйӣҶж•°жҚ®пјҢзүҮйқўйҷҚдҪҺвҖңжӢ’зңҹвҖқзҡ„жҰӮзҺҮпјҢеҸҚиҖҢдјҡжҸҗй«ҳвҖңе®№еҒҮвҖқзҡ„жҰӮзҺҮпјҢйҖ жҲҗжӣҙеӨ§жҚҹеӨұгҖӮз”ұжӯӨеҸҜи§ҒпјҢжҷәж…§жІ»зҗҶдёӯж•°жҚ®зҡ„收йӣҶдёҺжІ»зҗҶд»»еҠЎе’ҢеҶізӯ–зҡ„жҖ§иҙЁжҒҜжҒҜзӣёе…іпјҢйңҖиҰҒеҹәдәҺеә”з”Ёжғ…еўғиҝӣиЎҢжҲҗжң¬-收зӣҠеҲҶжһҗпјҢеҶіе®ҡж•°жҚ®ж”¶йӣҶзҡ„иҫ№з•ҢгҖӮ
дҪҶйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеңЁж•°жҚ®ж”¶йӣҶе’ҢдҪҝз”ЁдёӯпјҢжҲ‘们дёҚиғҪд»…д»…д»Һж”ҝеәңйғЁй—ЁжҲ–иҖ…е·ҘдҪңдәәе‘ҳзҡ„жҲҗжң¬-收зӣҠи§’еәҰвҖңз®—иҙҰвҖқпјҢиҖҢеә”иҜҘз»јеҗҲе…ЁеұҖвҖңз®—жҖ»иҙҰвҖқгҖӮдҫӢеҰӮпјҢи®ёеӨҡең°ж–№еңЁз–«жғ…йҳІжҺ§дёӯйҮҚеӨҚзҷ»и®°зҫӨдј—дёӘдәәиә«д»ҪдҝЎжҒҜпјҢеӨҡж¬ЎиҝӣиЎҢдәәи„ёдҝЎжҒҜзҡ„йҮҮйӣҶдёҺж ёйӘҢпјҢзңӢдјјвҖңдҫҝж°‘вҖқпјҢдҪҶд№ҹеҸҜиғҪеҜјиҮҙе…¬ж°‘иә«д»ҪдҝЎжҒҜзҡ„жі„йңІпјҢд»ҺзӨҫдјҡзҰҸзҘүжҖ»дҪ“и§’еәҰзңӢжңүзҡ„дёҫеҠЁе№¶ж— ж„Ҹд№үпјҢд»…д»…жҳҜж–№дҫҝдёӘеҲ«йғЁй—Ёе’Ңе·ҘдҪңдәәе‘ҳиҖҢе·ІгҖӮеӣ жӯӨпјҢеңЁжҷәж…§жІ»зҗҶдёӯд№ҹеә”иҜҘеҹәдәҺе…·дҪ“зҡ„зҺҜеўғзЎ®е®ҡжңүйҷҗзҡ„жІ»зҗҶзӣ®ж Үе’Ңд»»еҠЎпјҢеҜ№дәҺдёӘдәәдҝЎжҒҜзҡ„йҮҮйӣҶиҝӣиЎҢж•ҙдҪ“з»ҹзӯ№пјҢдёҘеҠ жҠҠжҺ§пјҢеҲҶзұ»з®ЎзҗҶпјҢеҮҸе°‘ж•°жҚ®зҡ„йҮҚеӨҚйҮҮйӣҶпјҢдёҚдҪҶиҰҒи®©зҫӨдј—вҖңе°‘и·‘и·ҜвҖқпјҢд№ҹиҰҒи®©зҫӨдј—зҡ„дёӘдәәдҝЎжҒҜвҖңе°‘и·‘и·ҜвҖқгҖӮ
ж”ҝеәңеңЁж•°жҚ®иҝҗиЎҢдёӯзҡ„и§’иүІ
еңЁд»ҘеӨ§ж•°жҚ®жҠҖжңҜдёәдё»иҰҒзү№еҫҒзҡ„жҷәж…§жІ»зҗҶдёӯпјҢж”ҝеәңеҪ“然жҳҜжү®жј”зқҖеҹәзЎҖжҖ§зҡ„и§’иүІгҖӮиҖҢдё”пјҢз”ұдәҺж•°жҚ®зҡ„дҪҝз”Ёе…·жңүйқһжҺ’д»–жҖ§пјҢ并дёҚеӣ дёәжҹҗдёӘдё»дҪ“зҡ„дҪҝз”ЁиҖҢжҺ’ж–Ҙе…¶д»–дё»дҪ“зҡ„дҪҝз”ЁпјӣеҫҲеӨ§зЁӢеәҰдёҠе…¶иҝҳе…·жңүйқһз«һдәүжҖ§пјҢж•°жҚ®дҪҝдёӘдҪ“еҜ№дәҺдё–з•Ңзҡ„и®ӨиҜҶзҡ„жҸҗеҚҮд№ҹдёҚдјҡеҪұе“Қе…¶д»–дё»дҪ“зҡ„и®ӨиҜҶжҸҗеҚҮгҖӮд№ҹе°ұжҳҜиҜҙпјҢж•°жҚ®иҰҒзҙ е…·жңүе…¬е…ұе“Ғзҡ„жҖ§иҙЁгҖӮжҢүз…§з»Ҹе…ёзҡ„е…¬е…ұз»ҸжөҺеӯҰзҗҶи®әпјҢе…¬е…ұе“Ғзҡ„дҫӣз»ҷеә”иҜҘз”ұж”ҝеәңиҙҹиҙЈпјҢеёӮеңәеңЁиҝҷдёҖйўҶеҹҹеҸҜиғҪдјҡеӨұзҒөгҖӮ
然иҖҢпјҢжҷәж…§жІ»зҗҶз»Ҳ究еә”иҗҪи„ҡеңЁвҖңжІ»зҗҶвҖқдёҠпјҢйңҖиҰҒеӨҡе…ғдё»дҪ“зҡ„жңүеәҸеҸӮдёҺпјҢдёҚеә”з”ұж”ҝеәңдёҖ家зӢ¬еҠһгҖӮиҖҢдё”пјҢж•°жҚ®дҪңдёәдёҖз§ҚиҰҒзҙ пјҢеҸӮдёҺдәҶд»·еҖјзҡ„еҲӣйҖ пјҢ其收зӣҠеә”иҜҘеҹәжң¬йҒөеҫӘеёӮеңәеҺҹеҲҷгҖӮеҸҰеӨ–пјҢ既然еҰӮеүҚжүҖиҝ°пјҢж•°жҚ®зҡ„д»·еҖјжҳҜеҹәдәҺеҶізӯ–д»»еҠЎзҡ„пјҢж•°жҚ®д№ҹдёҚжҳҜи¶ҠеӨҡи¶ҠеҘҪзҡ„пјҢйӮЈд№ҲиҮіе°‘еңЁдёӘдҪ“еҶізӯ–иҖ…иә«дёҠпјҢж•°жҚ®иҰҒзҙ еӯҳеңЁиҫ№йҷ…收зӣҠйҖ’еҮҸзҡ„еҸҜиғҪжҖ§гҖӮдёҺжӯӨеҗҢж—¶пјҢд»ҺзӨҫдјҡж•ҙдҪ“жқҘзңӢеҸҜд»Ҙи®Өдёәж•°жҚ®иҰҒзҙ зҡ„иҫ№йҷ…收зӣҠйҖ’еўһпјҢеҸҜиғҪеҜјиҮҙзӨҫдјҡжңҖдјҳдёҺдёӘдҪ“жңҖдјҳд№Ӣй—ҙзҡ„еҒҸзҰ»гҖӮиҝҷдёҺзҹҘиҜҶиҝҷдёҖз”ҹдә§иҰҒзҙ жүҖйқўдёҙзҡ„з§Ғдәәдҫӣз»ҷдёҚи¶ізҡ„зү№зӮ№зұ»дјјгҖӮдҪҶжҳҜж•°жҚ®иҝҳжңүеҸҰдёҖдёӘйҮҚиҰҒзү№еҫҒпјҢдҪҝжҲ‘们дёҚиғҪз®ҖеҚ•е°ҶеҜ№з”ҹдә§иҖ…иҝӣиЎҢиЎҘиҙҙзӯүжҝҖеҠұзҹҘиҜҶз”ҹдә§е’Ңз§ҜзҙҜзҡ„е·Ҙе…·з…§жҗ¬еҲ°ж•°жҚ®дёӯжқҘгҖӮиҝҷе°ұжҳҜж•°жҚ®иҰҒзҙ зҡ„дә§з”ҹиҖ…е’ҢжӢҘжңүиҖ…жҳҜеҲҶзҰ»зҡ„пјҢж•°жҚ®иө„жәҗжқҘиҮӘдәҺеҚғеҚғдёҮдёҮзҡ„з”ЁжҲ·иЎҢдёәи®°еҪ•пјҢз»ҸиҝҮж•°жҚ®йҮҮйӣҶгҖҒжё…жҙ—е’ҢеҠ е·ҘеҗҺжҲҗдёәж•°жҚ®иҰҒзҙ пјҢиҖҢдә§з”ҹж•°жҚ®зҡ„з”ЁжҲ·дёҚеҶҚжҳҜж•°жҚ®иҰҒзҙ зҡ„жӢҘжңүиҖ…гҖӮеӣ жӯӨпјҢеҰӮжһңиҰҒи§ЈеҶіж•°жҚ®иҰҒзҙ зҡ„з§Ғдәәдҫӣз»ҷдёҚи¶ій—®йўҳпјҢжҲ‘们йңҖиҰҒд»Һж•°жҚ®зҡ„иҝҗиЎҢиҝҮзЁӢе…ҘжүӢпјҢеҜ№дәҺж•°жҚ®зҡ„дә§з”ҹиҖ…гҖҒ收йӣҶиҖ…е’ҢдҪҝз”ЁиҖ…зӯүйғҪжҸҗдҫӣйҖӮеҪ“зҡ„жҝҖеҠұгҖӮ
и®ёе®ӘжҳҘе’ҢзҺӢжҙӢз ”з©¶дәҶйғЁеҲҶзұ»еһӢдјҒдёҡзҡ„еӨ§ж•°жҚ®дё»иҰҒеә”з”ЁеңәжҷҜпјҢжҲ‘们еҸҜд»Ҙж №жҚ®ж•°жҚ®дә§з”ҹиҖ…дёҺжӢҘжңүиҖ…зҡ„е…ізі»е°Ҷе…¶еҲҶдёәдёүзұ»еңәжҷҜпјҢж”ҝеәңеңЁе…¶дёӯеҸҜд»Ҙдә§з”ҹдёҚеҗҢдҪңз”Ёпјҡж•°жҚ®дә§з”ҹдәҺз”ҹдә§жҙ»еҠЁпјҢеҰӮеҶңдёҡдјҒдёҡеҜ№з”ҹдә§зҡ„зІҫеҮҶжҺ§еҲ¶е’ҢжҷәиғҪз®ЎзҗҶгҖҒеҲ¶йҖ дёҡдјҒдёҡзҡ„жҷәиғҪеҢ–е·Ҙдёҡз”ҹдә§зәҝгҖҒжҲҝең°дә§з»ҸзәӘзұ»дјҒдёҡзҡ„еңЁзәҝзңӢжҲҝзӯүпјӣж•°жҚ®дә§з”ҹдәҺж•ҙдҪ“жҖ§зҡ„зӨҫдјҡжҙ»еҠЁпјҢеҰӮдәӨйҖҡеҮәиЎҢдёӯзҡ„зІҫз»ҶеҢ–е…¬дәӨи°ғеәҰдёҺз®ЎзҗҶпјҢжҷәж…§дҝЎеҸ·зҒҜгҖҒжҷәж…§зү©жөҒгҖҒйӣ¶е”®йӨҗйҘ®дјҒдёҡзҡ„еҚіж—¶й…ҚйҖҒе’ҢзІҫеҮҶйҖүеқҖзӯүпјӣж•°жҚ®дә§з”ҹдәҺдёӘеҲ«з”ЁжҲ·зҡ„иЎҢеҠЁпјҢеҰӮе®ҡеҲ¶еҢ–з”ҹдә§гҖҒжҷәиғҪе”®еҗҺжңҚеҠЎгҖҒз”ЁжҲ·/е®ўжҲ·з”»еғҸгҖҒдёӘжҖ§еҢ–жҺЁиҚҗгҖҒиҝңзЁӢеҢ»з–—иҜҠж–ӯгҖҒдҝЎиҙ·йЈҺйҷ©иҜ„дј°гҖҒдҝЎз”ЁдҪ“зі»зӯүгҖӮ
еӨ§ж•°жҚ®дё»иҰҒеә”з”ЁеңәжҷҜеҸҠж”ҝеәңеңЁе…¶дёӯзҡ„и§’иүІ

第дёҖзұ»еңәжҷҜдёӯж•°жҚ®иҝҗиЎҢйҖҡиҝҮйҷҚдҪҺжҲҗжң¬еҲӣйҖ д»·еҖјпјҢж•°жҚ®дә§з”ҹиҖ…дёҺжӢҘжңүиҖ…д№Ӣй—ҙж— еҲ©зӣҠеҶІзӘҒпјҢз”ҡиҮіеҗҲдёәдёҖдҪ“пјҢеӣ жӯӨеә”иў«и§ҶдёәеёӮеңәз»ҸжөҺдёӯзҡ„жӯЈеёёз»ҸиҗҘжҙ»еҠЁпјҢж”ҝеәңдёҚеә”иҝҮеӨҡе№Ійў„гҖӮеҪ“然пјҢиҝҷдәӣж•°жҚ®еҜ№дәҺе…¶д»–еёӮеңәдё»дҪ“еҸҜиғҪе…·жңүжҪңеңЁд»·еҖјпјҢжҷәж…§жІ»зҗҶдёӯеҰӮжһңд№ҹйңҖиҰҒиҝҷдәӣж•°жҚ®пјҢйӮЈд№Ҳж”ҝеәңеә”иҜҘз»ҷдәҲиҝҷзұ»дјҒдёҡи¶іеӨҹзҡ„жҝҖеҠұд»ҘдҝғдҪҝе…¶еҲҶдә«ж•°жҚ®пјҢйҷҚдҪҺе…¬е…ұдәӢеҠЎжҲҗжң¬гҖӮ
第дәҢзұ»еңәжҷҜдёӯж•°жҚ®иҝҗиЎҢйҖҡиҝҮжҸҗеҚҮж•ҲзҺҮдә§з”ҹд»·еҖјпјҢж•°жҚ®з”ҹдә§иҖ…иҷҪ然дёҺжӢҘжңүиҖ…еҲҶзҰ»пјҢдҪҶжҳҜжІЎжңүжҳҺжҳҫзҡ„еҲ©зӣҠеҶІзӘҒпјҢеҺҹеӣ еңЁдәҺж•°жҚ®жҳҜд»ҘеҠ жҖ»зҡ„еҪўејҸиҝӣе…ҘеҶізӯ–иҝҮзЁӢдёӯпјҢиҖҢдё”е…¶зӣ®ж ҮеҸ–еҗ‘иҫғдёәжё…жҷ°е’ҢеҚ•дёҖгҖӮиҝҷзұ»еңәжҷҜдёӯзҡ„ж•°жҚ®е…¬е…ұе“ҒжҖ§иҙЁжңҖејәпјҢжңҖе…·жңүеҲӣйҖ зӨҫдјҡд»·еҖјзҡ„жҪңеҠӣгҖӮе®һйҷ…дёҠпјҢдёҖиҲ¬жүҖи®Ізҡ„вҖңжҷәж…§еҹҺеёӮвҖқдё»иҰҒдҪ“зҺ°еңЁиҝҷдёҖеңәжҷҜдёӯгҖӮеӣ жӯӨпјҢж”ҝеәңеә”иҜҘдё»еҠЁеҸӮдёҺе…¶дёӯпјҢеңЁж•°жҚ®зҡ„收йӣҶгҖҒеӯҳеӮЁе’ҢеҠ е·ҘеӨ„зҗҶдёӯеҸ‘жҢҘдё»иҰҒдҪңз”ЁпјҢе»әи®ҫејҖж”ҫзҡ„ж•°жҚ®еҹәзЎҖи®ҫж–ҪпјҢ并鼓еҠұе…¶д»–дё»дҪ“з§ҜжһҒејҖеҸ‘еә”з”ЁиҝҷдәӣејҖж”ҫж•°жҚ®пјҢд»ҺиҖҢжҸҗеҚҮе…¬е…ұдәӢеҠЎж•ҲзҺҮгҖӮ
第дёүзұ»еңәжҷҜдёӯж•°жҚ®йҖҡиҝҮдјҳеҢ–жңҚеҠЎеҜ№иұЎзҡ„дҪ“йӘҢиҖҢеҲӣйҖ д»·еҖјпјҢж•°жҚ®зҡ„дә§з”ҹиҖ…е’ҢжӢҘжңүиҖ…е®Ңе…ЁеҲҶзҰ»пјҢжҹҗдәӣж—¶еҖҷиҝҳжңүзқҖеҲ©зӣҠеҶІзӘҒгҖӮиҖҢдё”пјҢд»·еҖјеҲӣйҖ дёҺд»·еҖјеҲҶй…Қд№Ӣй—ҙеҫҲйҡҫеҲ’еҲҶжҲӘ然иҫ№з•ҢпјҢе…ізі»еҫ®еҰҷпјҢеҫҲе®№жҳ“жҲҗдёәвҖңеӨ§ж•°жҚ®жқҖзҶҹвҖқвҖңд»·ж јжӯ§и§ҶвҖқзҡ„еҲ©еҷЁпјҢд»ҺиҖҢжҚҹе®із”ЁжҲ·еҲ©зӣҠгҖӮеӣ жӯӨеңЁиҝҷзұ»еңәжҷҜзҡ„жҷәж…§жІ»зҗҶдёӯпјҢеә”иҜҘеҢәеҲҶж•°жҚ®зҡ„дә§з”ҹжҳҜжқҘиҮӘдәҺз”ЁжҲ·зҡ„иҮӘж„ҝжҠ«йңІпјҢиҝҳжҳҜдёҚзҹҘдёҚи§үдёӯзҡ„иў«еҠЁйҮҮйӣҶгҖӮеҜ№дәҺеҗҺиҖ…еә”дёҘеҠ зҰҒжӯўпјҢеқҡеҶіжү“еҮ»пјӣеҜ№дәҺеүҚиҖ…еҲҷеә”дәҲд»ҘдҝқжҠӨпјҢ并дёҘж јзӣ‘з®ЎпјҢз§ҜжһҒеј•е…ҘеӨҡе…ғдё»дҪ“еҸӮдёҺпјҢеңЁж”ҝеәңзӣ‘з®Ўд№ӢеӨ–еҪўжҲҗзӨҫдјҡзҡ„йқһжӯЈејҸзӣ‘з®ЎдҪ“еҲ¶пјҢд»ҘдјҳеҢ–е…¬е…ұдәӢеҠЎдҪ“йӘҢгҖӮ
еҚідҪҝж”ҝеәңзңҹзҡ„иғҪжҺҢжҸЎж¶өзӣ–зӨҫдјҡз”ҹжҙ»ж–№ж–№йқўйқўзҡ„жө·йҮҸж•°жҚ®пјҢж”ҝеәңд№ҹдёҚжҳҜжҷәж…§жІ»зҗҶдёӯзҡ„е”ҜдёҖиЎҢеҠЁиҖ…гҖӮжІ»зҗҶзҡ„жңҖз»Ҳзӣ®зҡ„иҝҳжҳҜжҸҗй«ҳдәәж°‘зҫӨдј—зҡ„иҺ·еҫ—ж„ҹгҖҒе№ёзҰҸж„ҹгҖҒе®үе…Ёж„ҹгҖӮд»Һе…ЁзӨҫдјҡзҡ„жҲҗжң¬ж”¶зӣҠи§’еәҰзңӢпјҢеёӮеңәдё»дҪ“еҲ©з”ЁвҖңдә’иҒ”зҪ‘+вҖқжҠҖжңҜеҪўжҲҗзҡ„еҗ„з§Қж–°дёҡжҖҒгҖҒж–°жҠҖжңҜж”№еҸҳдәҶжҲ‘们зҡ„зӨҫдјҡз»ҸжөҺеҪўжҖҒпјҢе…¶жң¬иә«еҜ№дәҺжІ»зҗҶж јеұҖе°ұжңүзқҖж·ұеҲ»еҪұе“ҚгҖӮдҫӢеҰӮпјҢз”өеӯҗе•ҶеҠЎгҖҒж•°еӯ—з»ҸжөҺзҡ„蓬еӢғеҸ‘еұ•жһҒеӨ§жҸҗеҚҮдәҶжңҚеҠЎдёҡзҡ„з”ҹдә§ж•ҲзҺҮпјҢеўһеҠ дәҶеӣҪеҶ…йңҖжұӮпјҢеҲӣйҖ дәҶе°ұдёҡпјҢиҝҷжң¬иә«е°ұзј“и§ЈдәҶзӨҫдјҡжІ»зҗҶзҡ„еҺӢеҠӣгҖӮжңҖиҝ‘пјҢ笔иҖ…еҹәдәҺең°зә§еёӮж•°жҚ®зҡ„дёҖйЎ№з ”з©¶еҸ‘зҺ°пјҢж•°еӯ—йҮ‘иһҚеҸ‘еұ•еёҰжқҘзҡ„ж”Ҝд»ҳдҫҝеҲ©жҖ§жҸҗеҚҮжҳҫи‘—йҷҚдҪҺдәҶзӣ—зӘғжЎҲзҡ„еҸ‘жЎҲзҺҮпјҢжҸҗеҚҮдәҶеұ…ж°‘зҡ„е№ёзҰҸж„ҹе’Ңе®үе…Ёж„ҹгҖӮеӣ жӯӨпјҢж•°еӯ—з»ҸжөҺж—¶д»Јзҡ„и®ёеӨҡз»ҸиҗҘж–№ејҸзҡ„еҲӣж–°иҷҪз„¶е№¶ж— вҖңжІ»зҗҶвҖқзҡ„зӣ®зҡ„пјҢд№ҹжІЎжңүж”ҝеәңйғЁй—Ёзҡ„зӣҙжҺҘеҸӮдёҺпјҢдҪҶжҳҜд№ҹеҸҜд»ҘеҸ‘жҢҘвҖңжІ»зҗҶвҖқзҡ„еҠҹж•ҲпјҢеңЁе№ҝд№үдёҠжҲҗдёәжҷәж…§жІ»зҗҶдҪ“зі»зҡ„дёҖйғЁеҲҶгҖӮ
дәәе·ҘжҷәиғҪеңЁжҷәж…§жІ»зҗҶдёӯзҡ„еә”з”ЁеұҖйҷҗ
дәәе·ҘжҷәиғҪжҳҜиҝ‘е№ҙжқҘйқһеёёеүҚжІҝе’Ңзғӯй—Ёзҡ„жҠҖжңҜпјҢиҜ•еӣҫдҪҝжңәеҷЁиғҪеӨҹиғңд»»дёҖдәӣйҖҡеёёйңҖиҰҒдәәзұ»жҷәж…§жүҚиғҪе®ҢжҲҗзҡ„еӨҚжқӮе·ҘдҪңпјҢжңәеҷЁиҝӣиЎҢзҡ„вҖңеӯҰд№ вҖқиҮӘ然зҰ»дёҚејҖж•°жҚ®зҡ„иҫ“е…ҘгҖӮдәәе·ҘжҷәиғҪжҠҖжңҜзҡ„е№ҝжіӣдҪҝз”Ёз»ҷдәәзұ»зӨҫдјҡз”ҹжҙ»еёҰжқҘдәҶеҫҲеӨҡдҫҝеҲ©пјҢеңЁж”ҝеҠЎжңҚеҠЎдёӯпјҢеҹәдәҺдәәе·ҘжҷәиғҪзҡ„жңәеҷЁжҷәиғҪиҜҶеҲ«гҖҒиә«д»ҪйӘҢиҜҒгҖҒжңҚеҠЎжҺЁиҚҗгҖҒжҷәиғҪе®ўжңҚе’ҢдҝЎжҒҜеӨ„зҗҶзӯүе·Із»Ҹе№ҝжіӣеә”з”ЁгҖӮдҪҶжҳҜпјҢгҖҠз»Ҳз»“иҖ…гҖӢгҖҠе°‘ж•°жҙҫжҠҘе‘ҠгҖӢзӯүзҫҺеӣҪеҪұзүҮдёӯеҮәзҺ°зҡ„дәәзұ»еҶізӯ–е°Ҷиў«дәәе·ҘжҷәиғҪд»Јжӣҝзҡ„еңәжҷҜпјҢд№ҹд»Өи§ӮиҖ…еҗҺжҖ•гҖӮйӮЈд№ҲпјҢеңЁжҷәж…§жІ»зҗҶдёӯпјҢдәәе·ҘжҷәиғҪзҡ„еә”з”ЁеҸҜд»Ҙиө°еҲ°е“ӘдёҖжӯҘе‘ўпјҹ
еӣһзӯ”иҝҷдёҖй—®йўҳзҡ„е…ій”®еңЁдәҺпјҢдҪңдёәжңҚеҠЎеҜ№иұЎпјҢзӨҫдјҡе…¬дј—еңЁеӨҡеӨ§зЁӢеәҰдёҠж„ҝж„Ҹж”ҝеәңйғЁй—Ёз”Ёдәәе·ҘжҷәиғҪд»Јжӣҝдәәзұ»еҶізӯ–пјҹиҝҷйңҖиҰҒжҲ‘们еҜ№дәҺдәәе·ҘжҷәиғҪе’Ңдәәзұ»еҶізӯ–зҡ„зӣёеҜ№ж•ҲзҺҮиҝӣиЎҢжҜ”иҫғпјҢиҖҢиҝҷз§Қж•ҲзҺҮжҜ”иҫғжң¬иә«д№ҹжңүзқҖйқҷжҖҒе’ҢеҠЁжҖҒд№ӢеҲҶгҖӮ
д»ҺйқҷжҖҒж•ҲзҺҮзңӢпјҢдәәе·ҘжҷәиғҪзҡ„еҹәзЎҖжҳҜж•°жҚ®е’Ңз®—жі•пјҢдҫқжүҳжҺҢжҸЎеңЁж”ҝеәңйғЁй—ЁеҶ…йғЁзҡ„еӨ§йҮҸж•°жҚ®иө„жәҗе’Ңдә‘и®Ўз®—жҸҗдҫӣзҡ„иҝ‘д№Һж— йҷҗзҡ„и®Ўз®—иғҪеҠӣзҡ„ж”Ҝж’‘пјҢдәәе·ҘжҷәиғҪйҖҡиҝҮж·ұеәҰеӯҰд№ еҸҜд»Ҙд»Һжө·йҮҸж”ҝеҠЎеӨ§ж•°жҚ®дёӯжҢ–жҺҳеҮәе®қиҙөзҡ„зҹҘиҜҶгҖӮзӣёжҜ”дәҺе…·жңүз»ҸйӘҢејҸгҖҒйҡҸж„ҸжҖ§гҖҒйқһе®ҡйҮҸзӯүзү№еҫҒзҡ„дј з»ҹеҶізӯ–жЁЎејҸпјҢдәәе·ҘжҷәиғҪзҡ„ж•ҲзҺҮжӣҙй«ҳпјҢеҮәй”ҷжҰӮзҺҮжӣҙдҪҺпјҢжӣҙеҸҜйҖӮеә”新时代科еӯҰеҶізӯ–зҡ„ж–°йңҖжұӮгҖӮ
然иҖҢпјҢд»ҺеҠЁжҖҒж•ҲзҺҮжқҘзңӢпјҢдәәе·ҘжҷәиғҪзҡ„еүҚжҷҜжңӘеҝ…йқһеёёд№җи§ӮгҖӮйҰ–е…ҲпјҢеңЁз®—жі•зҡ„еә”з”ЁиҝҮзЁӢдёӯпјҢеҹәдәҺе·Іжңүж•°жҚ®и®ӯз»ғжЁЎеһӢ并дёҚиғҪе®Ңе…ЁйҒҝе…Қдәәдёәзҡ„еҒҸи§ҒгҖҒиҜҜи§Је’ҢеҒҸзҲұпјҢзӨҫдјҡе…¬е№іе’Ңе…¬жӯЈд»ҺиҖҢдјҡеҸ—еҲ°еҪұе“ҚгҖӮиҖҢдё”ж·ұеәҰеӯҰд№ зҡ„з®—жі•еҫҲеӨ§зЁӢеәҰдёҠиҝҳжҳҜвҖңй»‘з®ұвҖқпјҢиҖҢжі•жІ»йңҖиҰҒ规еҲҷзҡ„йҖҸжҳҺжҖ§е’ҢзЎ®е®ҡжҖ§пјҢз®—жі•зҡ„иҝҷдёҖеҶізӯ–зү№еҫҒдёҺжі•жІ»иҰҒжұӮдёҚзӣёз¬ҰеҗҲгҖӮе…¶ж¬ЎпјҢиЎЁйқўдёҠзңӢдјјд№Һдәәе·ҘжҷәиғҪеҸҜд»ҘеҸ‘жҺҳжӣҙеӨҡзҡ„ж•°жҚ®пјҢд»ҺиҖҢеё®еҠ©е…¬е…ұйғЁй—Ёзҡ„еҶізӯ–иҖ…е®һзҺ°жӣҙеҝ«зҡ„еӯҰд№ гҖӮдҪҶжҳҜпјҢдёҺжӯӨеҗҢж—¶з®—жі•д№ҹеңЁдёҚж–ӯиҝӯд»ЈеҚҮзә§пјҢиҝҷе°ұж¶үеҸҠеҲ°и°ҒжқҘеҜ№з®—жі•иҝӣиЎҢж”№иҝӣпјҹеңЁжҷәж…§жІ»зҗҶдёӯпјҢдәәе·ҘжҷәиғҪеә”з”Ёзҡ„ејҖеҸ‘иҖ…дёҖиҲ¬дёҚжҳҜж”ҝеәңйғЁй—Ёе·ҘдҪңдәәе‘ҳпјҢиҖҢжҳҜвҖңд№ҷж–№вҖқпјҢеҰӮжһңдҪҝз”ЁиҖ…е’ҢејҖеҸ‘иҖ…д№Ӣй—ҙзјәд№Ҹжңүж•ҲжІҹйҖҡпјҢз®—жі•е°ұеҸҜиғҪдјҡжҢҒз»ӯиҫ“еҮәй”ҷиҜҜз»“жһңгҖӮ第дёүпјҢдәәе·ҘжҷәиғҪеҮәй”ҷжҰӮзҺҮеҸҜиғҪиҫғдәәдёәеҶізӯ–жӣҙдҪҺпјҢдҪҶжҳҜд»Қ然жңүеҮәй”ҷзҡ„еҸҜиғҪпјҢйӮЈд№ҲдёҖж—ҰеҮәй”ҷеә”иҜҘеҗ‘и°Ғй—®иҙЈпјҹжҳҜеә”з”Ёдәәе·ҘжҷәиғҪиҝӣиЎҢж”ҝеҠЎжңҚеҠЎзҡ„ж”ҝеәңйғЁй—ЁпјҢиҝҳжҳҜејҖеҸ‘дәәе·ҘжҷәиғҪеә”з”Ёзҡ„дјҒдёҡпјҹеҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҢдјҒдёҡдёҺж”ҝеәңзҡ„е…ізі»жҳҜеҗҲеҗҢе…ізі»пјҢжүҝжӢ…зҡ„жҳҜжңүйҷҗиҙЈд»»пјҢеӣ жӯӨиЎҢж”ҝдҪ“еҲ¶еҶ…йғЁзҡ„й—®иҙЈйҖ»иҫ‘еҫҖеҫҖйҡҫд»Ҙжү©еұ•еҲ°дјҒдёҡеұӮйқўгҖӮиҝҷз§ҚжІ»зҗҶдё»дҪ“зҡ„вҖңжқғиҙЈеӨұеҪ“вҖқз»ҷзӨҫдјҡеёҰжқҘдәҶиҫғеӨ§йЈҺйҷ©гҖӮ第еӣӣпјҢзҺ°жңүзҡ„дәәе·ҘжҷәиғҪж”ҝеҠЎжңҚеҠЎеә”з”ЁйғҪжҳҜеҹәдәҺе·Іжңүж•°жҚ®иҝӣиЎҢи®ӯз»ғзҡ„пјҢиҖҢиҝҷдәӣж•°жҚ®жң¬иә«жҳҜеҜ№зӨҫдјҡжҲҗе‘ҳиЎҢдёәзҡ„ж•°еӯ—еҢ–жөӢеәҰгҖӮдёҖж–№йқўпјҢ并йқһжүҖжңүзҡ„дёҺеҶізӯ–зӣёе…ізҡ„иЎҢдёәйғҪеҸҜд»Ҙиў«еҗҲзҗҶйҮҸеҢ–пјӣеҸҰдёҖж–№йқўпјҢж—Ҙеёёз”ҹжҙ»дёӯеӯҳеңЁеӨ§йҮҸеҸҚеёёе’Ңж„ҸеӨ–пјҢеҹәдәҺи§ӮеҜҹеҲ°зҡ„жңүйҷҗзҡ„еҚ•дёӘдёӘдҪ“иЎҢдёәж•°жҚ®еҜ№дәҺе…¶д»–дёӘдҪ“йҮҮеҸ–иЎҢеҠЁпјҢеҫҲе®№жҳ“дә§з”ҹе°Ҹж ·жң¬и°¬иҜҜгҖӮиҖҢдё”еҰӮжһңдәәе·ҘжҷәиғҪжҲҗдёәеҶізӯ–е·Ҙе…·пјҢеңЁжҹҗз§ҚзЁӢеәҰдёҠпјҢжӣҙж–№дҫҝдәҶдёҖдәӣзӨҫдјҡжҲҗе‘ҳй’ҲеҜ№з®—жі•зҡ„иҰҒжұӮж”№еҸҳиҮӘе·ұжңӘжқҘзҡ„иЎҢдёәпјҢвҖңжҠ•е…¶жүҖеҘҪвҖқпјҢжҲ–иҖ…зҜЎж”№ж•°жҚ®зҡ„еҪ•е…ҘпјҢд»ҘжңҹиҺ·еҫ—жңүеҲ©дәҺиҮӘе·ұзҡ„з»“жһңпјҢз”ҡиҮіе№Іи„ҶйҮҮеҸ–иЎҢеҠЁйҒҝе…ҚиҮӘе·ұзҡ„иЎҢдёәиў«зӣ‘жҺ§е’ҢжөӢйҮҸгҖӮиҝҷе°Өе…¶еңЁдёҠж–ҮжүҖи®Ізҡ„第дёүзұ»еңәжҷҜдёӯжӣҙе®№жҳ“дә§з”ҹгҖӮиҝҷдәӣеҸҜиғҪжҖ§йғҪеҜ№дәәе·ҘжҷәиғҪеңЁжҷәж…§жІ»зҗҶдёӯзҡ„еә”з”Ёж–ҪеҠ дәҶйҷҗеҲ¶гҖӮ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеңЁз¬¬дёүзұ»еңәжҷҜдёӯпјҢжңҖе®№жҳ“дә§з”ҹеҲҶй…ҚдёҠзҡ„зҹӣзӣҫе’ҢеҶІзӘҒпјҢжӯӨж—¶еә”з”Ёдәәе·ҘжҷәиғҪиҝӣиЎҢеҶізӯ–жңҖе®№жҳ“дә§з”ҹдәүи®®пјҢз®—жі•еңЁжӯӨж—¶жңҖеӨҡеҸӘиғҪдҪңдёәдёҖз§ҚеҗҺеҸ°зҡ„иҫ…еҠ©е’ҢеҸӮиҖғпјҢиҖҢж— жі•д»ЈжӣҝеҶізӯ–иҖ…иҝӣиЎҢдҝЎжҒҜйҮҮйӣҶе’ҢеҶізӯ–гҖӮ
иҫ№жІҒи®ӨдёәпјҢж”ҝеәңжҜ”з§ҒдәәжӣҙиғҪе»үд»·ең°ж”Ҝй…Қиҝҗз”ЁзҹҘиҜҶдёҺжқғеҠӣгҖӮд№ҹе°ұжҳҜиҜҙпјҢж”ҝеәңеңЁж•°жҚ®дҪҝз”Ёдёӯе…·жңүжҜ”иҫғдјҳеҠҝгҖӮд»Һж•°жҚ®зҡ„иҝҗиЎҢиҝҮзЁӢзңӢпјҢж”ҝеәңеңЁж•°жҚ®зҡ„еӮЁеӯҳдёҠзӣёеҜ№дәҺдјҒдёҡе…·жңүжҜ”иҫғдјҳеҠҝпјҢеңЁж•°жҚ®ж”¶йӣҶдёҠеҲҷжҳҜж”ҝеәңе’ҢдјҒдёҡеҗ„жңүжүҖй•ҝпјҢеңЁж•°жҚ®еҠ е·ҘеӨ„зҗҶе’ҢејҖеҸ‘еә”з”Ёж–№йқўеҲҷжҳҜдјҒдёҡе…·жңүжҜ”иҫғдјҳеҠҝгҖӮеӣ жӯӨпјҢжҲ‘们еә”жҢүз…§ж•°жҚ®иҝҗиЎҢиҝҮзЁӢдёӯзҡ„еҗ„дё»дҪ“зҡ„дјҳеҠҝе’Ңзү№зӮ№пјҢж №жҚ®жІ»зҗҶзӣ®ж Үе’Ңд»»еҠЎи§„еҲ’ж•°жҚ®зҡ„йҮҮйӣҶпјҢи°Ёж…ҺдҪҝз”Ёз®—жі•пјҢеҢәеҲҶж”ҝеәңгҖҒеёӮеңәе’ҢзӨҫдјҡзҡ„иҫ№з•ҢпјҢд»Ҙе……еҲҶеҸ‘жҢҘеҗ„ж–№з§ҜжһҒжҖ§пјҢжӣҙеҘҪең°жҺЁиҝӣеӣҪ家治зҗҶдҪ“зі»е’ҢжІ»зҗҶиғҪеҠӣзҺ°д»ЈеҢ–гҖӮ
| 
 й«ҳз‘һдёңзӯүпјҡ2025е№ҙиө„дә§
й«ҳз‘һдёңзӯүпјҡ2025е№ҙиө„дә§ еҶңдёҡж–°иҙЁз”ҹдә§еҠӣпјҡеҶ…ж¶ө
еҶңдёҡж–°иҙЁз”ҹдә§еҠӣпјҡеҶ…ж¶ө еҲҳдҝҠжқ°зӯүпјҡжһ„е»әйҖӮеә”еҶң
еҲҳдҝҠжқ°зӯүпјҡжһ„е»әйҖӮеә”еҶң 11жңҲе…Ёзҗғи°·зү©еёӮеңәдёҺиҙё
11жңҲе…Ёзҗғи°·зү©еёӮеңәдёҺиҙё з®Ўж¶ӣзӯүпјҡпјҡдәәж°‘еёҒжұҮзҺҮ
з®Ўж¶ӣзӯүпјҡпјҡдәәж°‘еёҒжұҮзҺҮ й’ҹжӯЈз”ҹпјҡеҗ‘е®ҢжҲҗйў„з®—зӣ®
й’ҹжӯЈз”ҹпјҡеҗ‘е®ҢжҲҗйў„з®—зӣ® жқҺиҝ…йӣ·пјҡжҳҺе№ҙиҙўж”ҝиөӨеӯ—
жқҺиҝ…йӣ·пјҡжҳҺе№ҙиҙўж”ҝиөӨеӯ— еј зәўе®Үпјҡжһ„е»әе…·жңүдёӯеӣҪ
еј зәўе®Үпјҡжһ„е»әе…·жңүдёӯеӣҪ ж—әеӯЈдёҚж—ә еҪ“еүҚз”ҹзҢӘеёӮ
ж—әеӯЈдёҚж—ә еҪ“еүҚз”ҹзҢӘеёӮ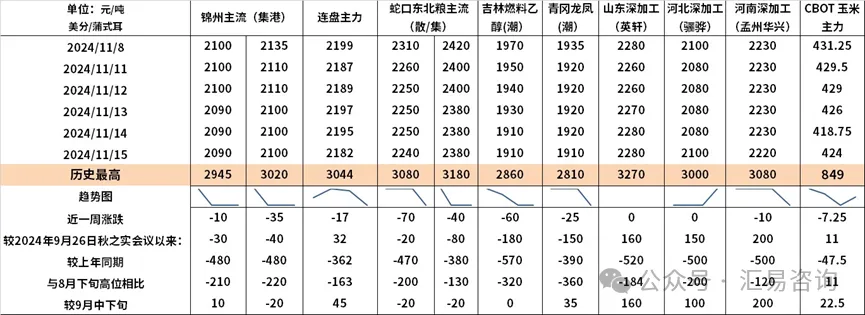 д»ҺеҪ“еүҚеӣҪеҶ…зҺүзұіеёӮеңәең°
д»ҺеҪ“еүҚеӣҪеҶ…зҺүзұіеёӮеңәең° з®Ўж¶ӣпјҡзү№жң—жҷ®еӣһеҪ’еҜ№дёӯ
з®Ўж¶ӣпјҡзү№жң—жҷ®еӣһеҪ’еҜ№дёӯ







 еҸ‘иЎЁдәҺ 2021-3-15 10:47:44
еҸ‘иЎЁдәҺ 2021-3-15 10:47:44
 жҸҗеҚҮеҚЎ
жҸҗеҚҮеҚЎ зҪ®йЎ¶еҚЎ
зҪ®йЎ¶еҚЎ
 еҰӮдҪ•жһ„е»әејҳжү¬ж•ҷиӮІе®¶зІҫзҘһзҡ„жңәеҲ¶дҪ“зі»пјҹжҠҠжҸЎеҘҪ
еҰӮдҪ•жһ„е»әејҳжү¬ж•ҷиӮІе®¶зІҫзҘһзҡ„жңәеҲ¶дҪ“зі»пјҹжҠҠжҸЎеҘҪ иҙўж”ҝйғЁпјҡжҸҗеүҚдёӢиҫҫ566дәҝе…ғпјҒ
иҙўж”ҝйғЁпјҡжҸҗеүҚдёӢиҫҫ566дәҝе…ғпјҒ зҺӢдәҡеҚҺпјҡд»Ҙжңүж•ҲжІ»зҗҶжҺЁиҝӣд№Ўжқ‘е…ЁйқўжҢҜе…ҙ
зҺӢдәҡеҚҺпјҡд»Ҙжңүж•ҲжІ»зҗҶжҺЁиҝӣд№Ўжқ‘е…ЁйқўжҢҜе…ҙ еҘҪз”ҹжҖҒдәҰжңүвҖңеҘҪд»·й’ұвҖқ зӨҫдјҡиө„жң¬йҰ–ж¬ЎеҸӮдёҺж°ҙ
еҘҪз”ҹжҖҒдәҰжңүвҖңеҘҪд»·й’ұвҖқ зӨҫдјҡиө„жң¬йҰ–ж¬ЎеҸӮдёҺж°ҙ


